 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment
Dec 17, 2025RAW images have shown superior performance than sRGB images in many image processing tasks, especially for low-light image enhancement. However, most existing methods for RAW-based low-light enhancement usually sequentially process multi-scale information, which makes it difficult to achieve lightweight models and high processing speeds. Besides, they usually ignore the green channel superiority of RAW images, and fail to achieve better reconstruction performance with good use of green channel information. In this work, we propose an efficient RAW Image Enhancement Network (ERIENet), which parallelly processes multi-scale information with efficient convolution modules, and takes advantage of rich information in green channels to guide the reconstruction of images. Firstly, we introduce an efficient multi-scale fully-parallel architecture with a novel channel-aware residual dense block to extract feature maps, which reduces computational costs and achieves real-time processing speed. Secondly, we introduce a green channel guidance branch to exploit the rich information within the green channels of the input RAW image. It increases the quality of reconstruction results with few parameters and computations. Experiments on commonly used low-light image enhancement datasets show that ERIENet outperforms state-of-the-art methods in enhancing low-light RAW images with higher effiency. It also achieves an optimal speed of over 146 frame-per-second (FPS) for 4K-resolution images on a single NVIDIA GeForce RTX 3090 with 24G memory.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Noise Calibration and Spatial-Frequency Interactive Network for STEM Image Enhancement
Apr 03, 2025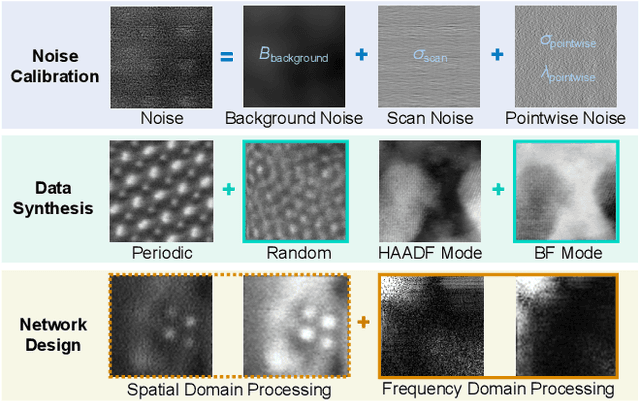



Scanning Transmission Electron Microscopy (STEM) enables the observation of atomic arrangements at sub-angstrom resolution, allowing for atomically resolved analysis of the physical and chemical properties of materials. However, due to the effects of noise, electron beam damage, sample thickness, etc, obtaining satisfactory atomic-level images is often challenging. Enhancing STEM images can reveal clearer structural details of materials. Nonetheless, existing STEM image enhancement methods usually overlook unique features in the frequency domain, and existing datasets lack realism and generality. To resolve these issues, in this paper, we develop noise calibration, data synthesis, and enhancement methods for STEM images. We first present a STEM noise calibration method, which is used to synthesize more realistic STEM images. The parameters of background noise, scan noise, and pointwise noise are obtained by statistical analysis and fitting of real STEM images containing atoms. Then we use these parameters to develop a more general dataset that considers both regular and random atomic arrangements and includes both HAADF and BF mode images. Finally, we design a spatial-frequency interactive network for STEM image enhancement, which can explore the information in the frequency domain formed by the periodicity of atomic arrangement. Experimental results show that our data is closer to real STEM images and achieves better enhancement performances together with our network. Code will be available at https://github.com/HeasonLee/SFIN}{https://github.com/HeasonLee/SFIN.
Mono2Stereo: Monocular Knowledge Transfer for Enhanced Stereo Matching
Nov 14, 2024



The generalization and performance of stereo matching networks are limited due to the domain gap of the existing synthetic datasets and the sparseness of GT labels in the real datasets. In contrast, monocular depth estimation has achieved significant advancements, benefiting from large-scale depth datasets and self-supervised strategies. To bridge the performance gap between monocular depth estimation and stereo matching, we propose leveraging monocular knowledge transfer to enhance stereo matching, namely Mono2Stereo. We introduce knowledge transfer with a two-stage training process, comprising synthetic data pre-training and real-world data fine-tuning. In the pre-training stage, we design a data generation pipeline that synthesizes stereo training data from monocular images. This pipeline utilizes monocular depth for warping and novel view synthesis and employs our proposed Edge-Aware (EA) inpainting module to fill in missing contents in the generated images. In the fine-tuning stage, we introduce a Sparse-to-Dense Knowledge Distillation (S2DKD) strategy encouraging the distributions of predictions to align with dense monocular depths. This strategy mitigates issues with edge blurring in sparse real-world labels and enhances overall consistency. Experimental results demonstrate that our pre-trained model exhibits strong zero-shot generalization capabilities. Furthermore, domain-specific fine-tuning using our pre-trained model and S2DKD strategy significantly increments in-domain performance. The code will be made available soon.
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Sep 02, 2024With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.
FCDFusion: a Fast, Low Color Deviation Method for Fusing Visible and Infrared Image Pairs
Aug 02, 2024



Visible and infrared image fusion (VIF) aims to combine information from visible and infrared images into a single fused image. Previous VIF methods usually employ a color space transformation to keep the hue and saturation from the original visible image. However, for fast VIF methods, this operation accounts for the majority of the calculation and is the bottleneck preventing faster processing. In this paper, we propose a fast fusion method, FCDFusion, with little color deviation. It preserves color information without color space transformations, by directly operating in RGB color space. It incorporates gamma correction at little extra cost, allowing color and contrast to be rapidly improved. We regard the fusion process as a scaling operation on 3D color vectors, greatly simplifying the calculations. A theoretical analysis and experiments show that our method can achieve satisfactory results in only 7 FLOPs per pixel. Compared to state-of-the-art fast, color-preserving methods using HSV color space, our method provides higher contrast at only half of the computational cost. We further propose a new metric, color deviation, to measure the ability of a VIF method to preserve color. It is specifically designed for VIF tasks with color visible-light images, and overcomes deficiencies of existing VIF metrics used for this purpose. Our code is available at https://github.com/HeasonLee/FCDFusion.