 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Pretraining on Encrypted Synthetic Data for Privacy-Preserving LLMs
Jan 12, 2026Preserving privacy in sensitive data while pretraining large language models on small, domain-specific corpora presents a significant challenge. In this work, we take an exploratory step toward privacy-preserving continual pretraining by proposing an entity-based framework that synthesizes encrypted training data to protect personally identifiable information (PII). Our approach constructs a weighted entity graph to guide data synthesis and applies deterministic encryption to PII entities, enabling LLMs to encode new knowledge through continual pretraining while granting authorized access to sensitive data through decryption keys. Our results on limited-scale datasets demonstrate that our pretrained models outperform base models and ensure PII security, while exhibiting a modest performance gap compared to models trained on unencrypted synthetic data. We further show that increasing the number of entities and leveraging graph-based synthesis improves model performance, and that encrypted models retain instruction-following capabilities with long retrieved contexts. We discuss the security implications and limitations of deterministic encryption, positioning this work as an initial investigation into the design space of encrypted data pretraining for privacy-preserving LLMs. Our code is available at https://github.com/DataArcTech/SoE.
RETuning: Upgrading Inference-Time Scaling for Stock Movement Prediction with Large Language Models
Oct 24, 2025Recently, large language models (LLMs) have demonstrated outstanding reasoning capabilities on mathematical and coding tasks. However, their application to financial tasks-especially the most fundamental task of stock movement prediction-remains underexplored. We study a three-class classification problem (up, hold, down) and, by analyzing existing reasoning responses, observe that: (1) LLMs follow analysts' opinions rather than exhibit a systematic, independent analytical logic (CoTs). (2) LLMs list summaries from different sources without weighing adversarial evidence, yet such counterevidence is crucial for reliable prediction. It shows that the model does not make good use of its reasoning ability to complete the task. To address this, we propose Reflective Evidence Tuning (RETuning), a cold-start method prior to reinforcement learning, to enhance prediction ability. While generating CoT, RETuning encourages dynamically constructing an analytical framework from diverse information sources, organizing and scoring evidence for price up or down based on that framework-rather than on contextual viewpoints-and finally reflecting to derive the prediction. This approach maximally aligns the model with its learned analytical framework, ensuring independent logical reasoning and reducing undue influence from context. We also build a large-scale dataset spanning all of 2024 for 5,123 A-share stocks, with long contexts (32K tokens) and over 200K samples. In addition to price and news, it incorporates analysts' opinions, quantitative reports, fundamental data, macroeconomic indicators, and similar stocks. Experiments show that RETuning successfully unlocks the model's reasoning ability in the financial domain. Inference-time scaling still works even after 6 months or on out-of-distribution stocks, since the models gain valuable insights about stock movement prediction.
GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation
Sep 26, 2025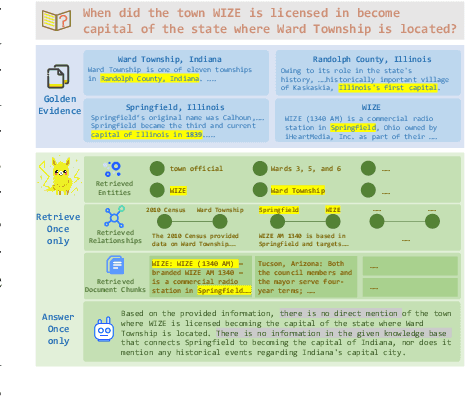
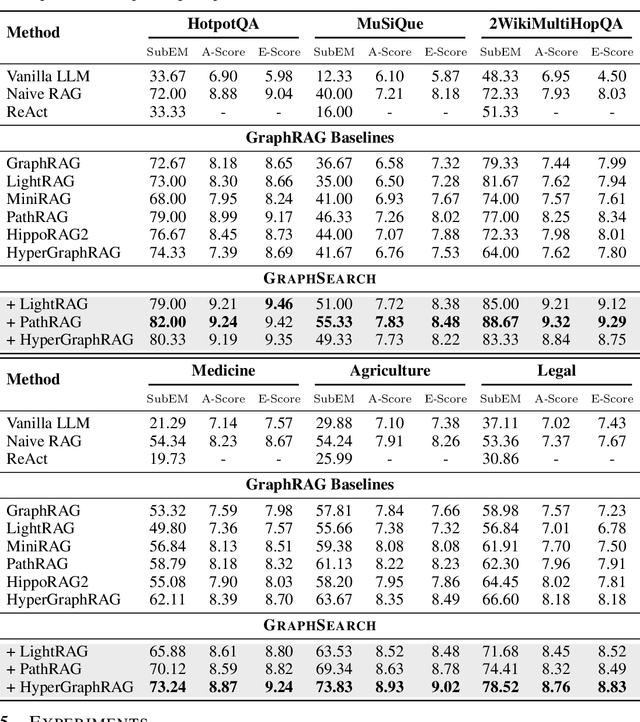

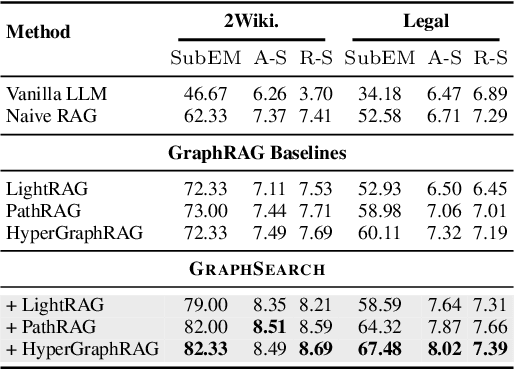
Graph Retrieval-Augmented Generation (GraphRAG) enhances factual reasoning in LLMs by structurally modeling knowledge through graph-based representations. However, existing GraphRAG approaches face two core limitations: shallow retrieval that fails to surface all critical evidence, and inefficient utilization of pre-constructed structural graph data, which hinders effective reasoning from complex queries. To address these challenges, we propose \textsc{GraphSearch}, a novel agentic deep searching workflow with dual-channel retrieval for GraphRAG. \textsc{GraphSearch} organizes the retrieval process into a modular framework comprising six modules, enabling multi-turn interactions and iterative reasoning. Furthermore, \textsc{GraphSearch} adopts a dual-channel retrieval strategy that issues semantic queries over chunk-based text data and relational queries over structural graph data, enabling comprehensive utilization of both modalities and their complementary strengths. Experimental results across six multi-hop RAG benchmarks demonstrate that \textsc{GraphSearch} consistently improves answer accuracy and generation quality over the traditional strategy, confirming \textsc{GraphSearch} as a promising direction for advancing graph retrieval-augmented generation.
Select2Reason: Efficient Instruction-Tuning Data Selection for Long-CoT Reasoning
May 22, 2025A practical approach to activate long chain-of-thoughts reasoning ability in pre-trained large language models is to perform supervised fine-tuning on instruction datasets synthesized by strong Large Reasoning Models such as DeepSeek-R1, offering a cost-effective alternative to reinforcement learning. However, large-scale instruction sets with more than 100k samples incur significant training overhead, while effective strategies for automatic long-CoT instruction selection still remain unexplored. In this work, we propose Select2Reason, a novel and efficient instruction-tuning data selection framework for long-CoT reasoning. From the perspective of emergence of rethinking behaviors like self-correction and backtracking, we investigate common metrics that may determine the quality of long-CoT reasoning instructions. Select2Reason leverages a quantifier to estimate difficulty of question and jointly incorporates a reasoning trace length-based heuristic through a weighted scheme for ranking to prioritize high-utility examples. Empirical results on OpenR1-Math-220k demonstrate that fine-tuning LLM on only 10% of the data selected by Select2Reason achieves performance competitive with or superior to full-data tuning and open-source baseline OpenR1-Qwen-7B across three competition-level and six comprehensive mathematical benchmarks. Further experiments highlight the scalability in varying data size, efficiency during inference, and its adaptability to other instruction pools with minimal cost.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Neural-Inspired Advances in Integral Cryptanalysis
May 16, 2025The study by Gohr et.al at CRYPTO 2019 and sunsequent related works have shown that neural networks can uncover previously unused features, offering novel insights into cryptanalysis. Motivated by these findings, we employ neural networks to learn features specifically related to integral properties and integrate the corresponding insights into optimized search frameworks. These findings validate the framework of using neural networks for feature exploration, providing researchers with novel insights that advance established cryptanalysis methods. Neural networks have inspired the development of more precise integral search models. By comparing the integral distinguishers obtained via neural networks with those identified by classical methods, we observe that existing automated search models often fail to find optimal distinguishers. To address this issue, we develop a meet in the middle search framework that balances model accuracy and computational efficiency. As a result, we reduce the number of active plaintext bits required for an 11 rounds integral distinguisher on SKINNY64/64, and further identify a 12 rounds key dependent integral distinguisher achieving one additional round over the previous best-known result. The integral distinguishers discovered by neural networks enable key recovery attacks on more rounds. We identify a 7 rounds key independent integral distinguisher from neural networks with even only one active plaintext cell, which is based on linear combinations of bits. This distinguisher enables a 15 rounds key recovery attack on SKINNYn/n, improving upon the previous record by one round. Additionally, we discover an 8 rounds key dependent integral distinguisher using neural network that further reduces the time complexity of key recovery attacks against SKINNY.
Synthesize-on-Graph: Knowledgeable Synthetic Data Generation for Continue Pre-training of Large Language Models
May 02, 2025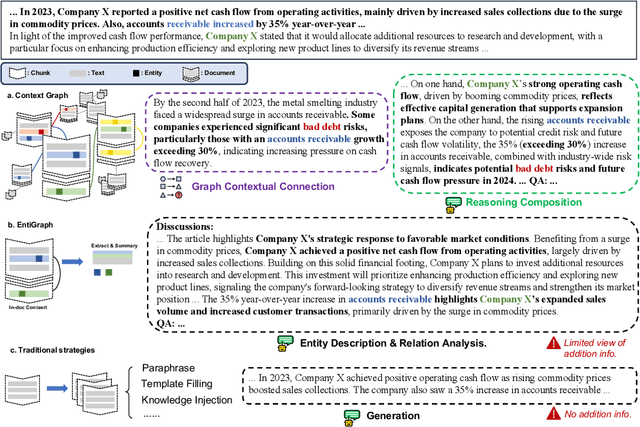
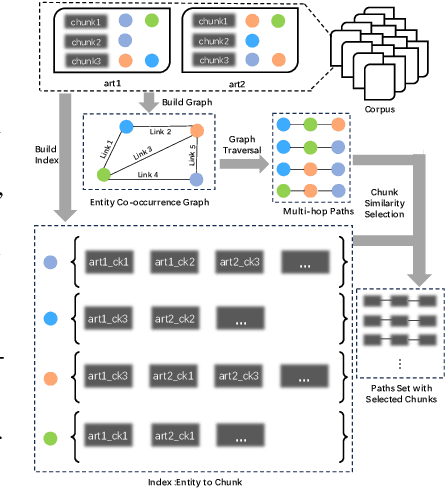

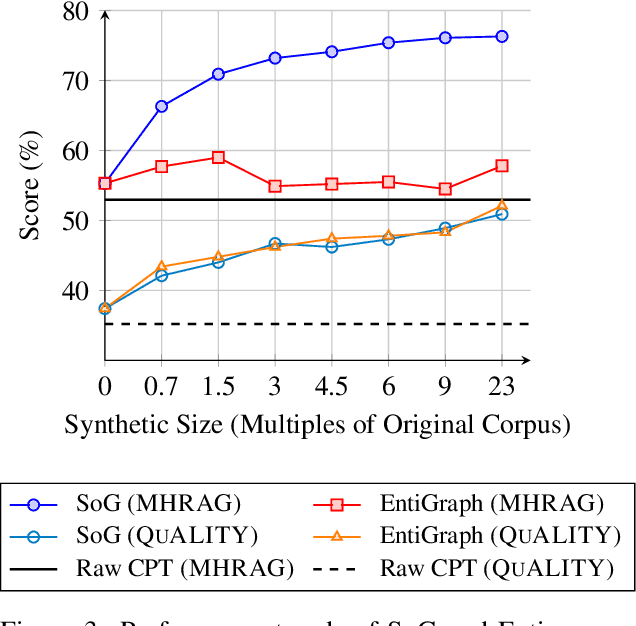
Large Language Models (LLMs) have achieved remarkable success but remain data-inefficient, especially when learning from small, specialized corpora with limited and proprietary data. Existing synthetic data generation methods for continue pre-training focus on intra-document content and overlook cross-document knowledge associations, limiting content diversity and depth. We propose Synthetic-on-Graph (SoG), a synthetic data generation framework that incorporates cross-document knowledge associations for efficient corpus expansion. SoG constructs a context graph by extracting entities and concepts from the original corpus, representing cross-document associations, and employing a graph walk strategy for knowledge-associated sampling. This enhances synthetic data diversity and coherence, enabling models to learn complex knowledge structures and handle rare knowledge. To further improve synthetic data quality, we integrate Chain-of-Thought (CoT) and Contrastive Clarifying (CC) synthetic, enhancing reasoning processes and discriminative power. Experiments show that SoG outperforms the state-of-the-art (SOTA) method in a multi-hop document Q&A dataset while performing comparably to the SOTA method on the reading comprehension task datasets, which also underscores the better generalization capability of SoG. Our work advances synthetic data generation and provides practical solutions for efficient knowledge acquisition in LLMs, especially in domains with limited data availability.
QuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025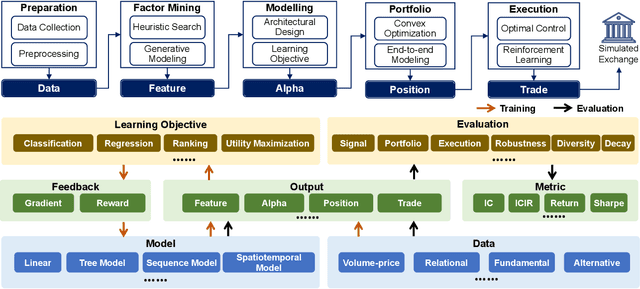



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
CTSR: Cartesian tensor-based sparse regression for data-driven discovery of high-dimensional invariant governing equations
Apr 10, 2025



Accurate and concise governing equations are crucial for understanding system dynamics. Recently, data-driven methods such as sparse regression have been employed to automatically uncover governing equations from data, representing a significant shift from traditional first-principles modeling. However, most existing methods focus on scalar equations, limiting their applicability to simple, low-dimensional scenarios, and failing to ensure rotation and reflection invariance without incurring significant computational cost or requiring additional prior knowledge. This paper proposes a Cartesian tensor-based sparse regression (CTSR) technique to accurately and efficiently uncover complex, high-dimensional governing equations while ensuring invariance. Evaluations on two two-dimensional (2D) and two three-dimensional (3D) test cases demonstrate that the proposed method achieves superior accuracy and efficiency compared to the conventional technique.
From Deep Learning to LLMs: A survey of AI in Quantitative Investment
Mar 27, 2025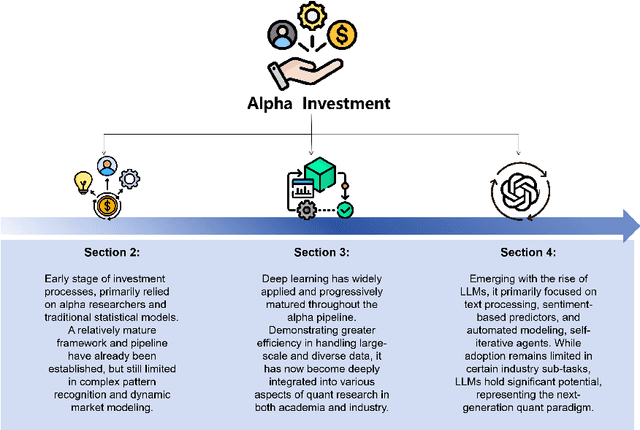
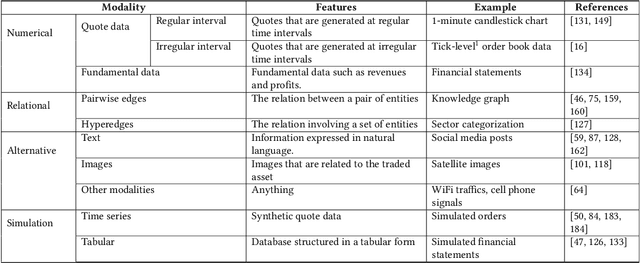
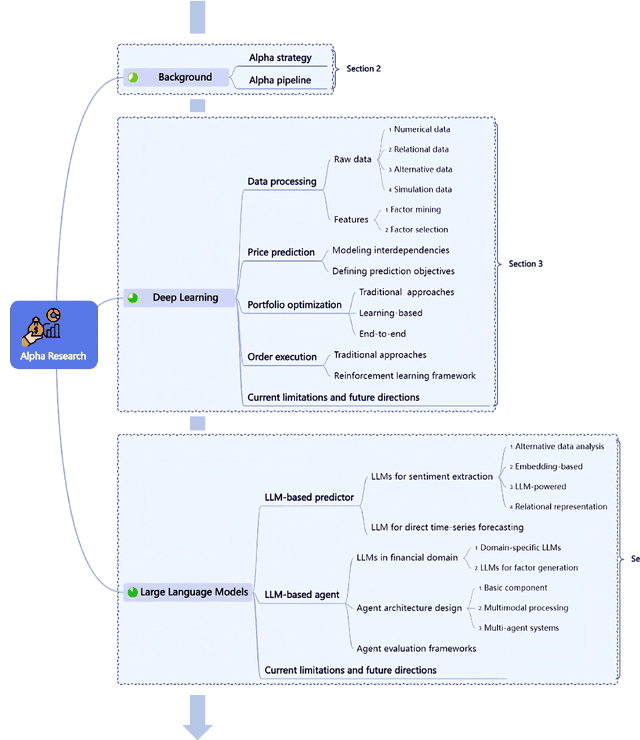
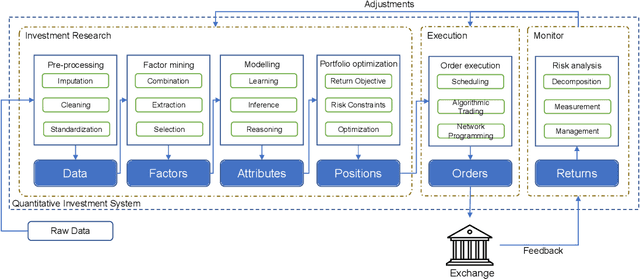
Quantitative investment (quant) is an emerging, technology-driven approach in asset management, increasingy shaped by advancements in artificial intelligence. Recent advances in deep learning and large language models (LLMs) for quant finance have improved predictive modeling and enabled agent-based automation, suggesting a potential paradigm shift in this field. In this survey, taking alpha strategy as a representative example, we explore how AI contributes to the quantitative investment pipeline. We first examine the early stage of quant research, centered on human-crafted features and traditional statistical models with an established alpha pipeline. We then discuss the rise of deep learning, which enabled scalable modeling across the entire pipeline from data processing to order execution. Building on this, we highlight the emerging role of LLMs in extending AI beyond prediction, empowering autonomous agents to process unstructured data, generate alphas, and support self-iterative workflows.