 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
A Survey on LLM-as-a-Judge
Nov 23, 2024Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey of LLM-as-a-Judge, addressing the core question: How can reliable LLM-as-a-Judge systems be built? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.
Fact-Level Confidence Calibration and Self-Correction
Nov 20, 2024



Confidence calibration in LLMs, i.e., aligning their self-assessed confidence with the actual accuracy of their responses, enabling them to self-evaluate the correctness of their outputs. However, current calibration methods for LLMs typically estimate two scalars to represent overall response confidence and correctness, which is inadequate for long-form generation where the response includes multiple atomic facts and may be partially confident and correct. These methods also overlook the relevance of each fact to the query. To address these challenges, we propose a Fact-Level Calibration framework that operates at a finer granularity, calibrating confidence to relevance-weighted correctness at the fact level. Furthermore, comprehensive analysis under the framework inspired the development of Confidence-Guided Fact-level Self-Correction ($\textbf{ConFix}$), which uses high-confidence facts within a response as additional knowledge to improve low-confidence ones. Extensive experiments across four datasets and six models demonstrate that ConFix effectively mitigates hallucinations without requiring external knowledge sources such as retrieval systems.
Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts for Open-Domain QA?
Jan 22, 2024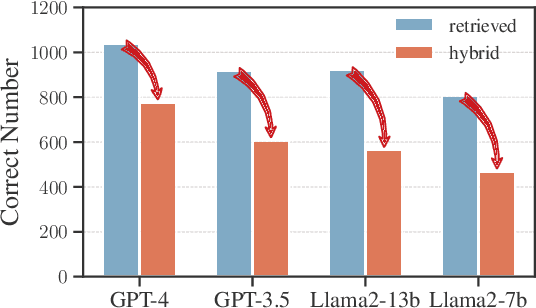
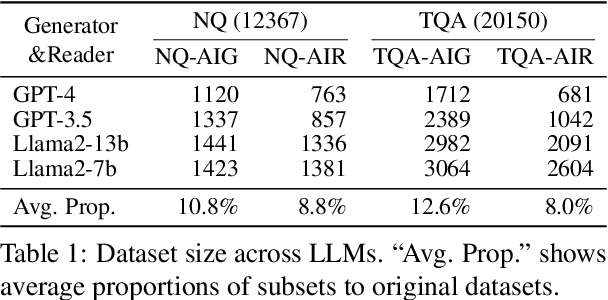
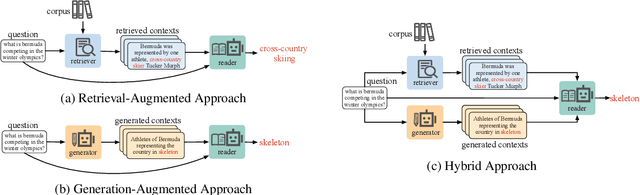
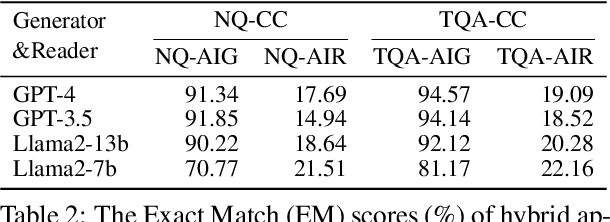
While auxiliary information has become a key to enhance Large Language Models (LLMs), relatively little is known about how well LLMs merge these contexts, specifically generated and retrieved. To study this, we formulate a task specifically designed to identify whether the answers, derived from the integration of generated and retrieved contexts, are attributed to either generated or retrieved contexts. To support this task, we develop a methodology to construct datasets with conflicting contexts, where each question is paired with both generated and retrieved contexts, yet only one of them contains the correct answer. Our experiments reveal a significant bias in LLMs towards generated contexts, as evidenced across state-of-the-art open (Llama2-7b/13b) and closed (GPT 3.5/4) systems. We further identify two key factors contributing to this bias: i) Contexts generated by LLMs typically show greater similarity to the questions, increasing their likelihood of selection; ii) The segmentation process used in retrieved contexts disrupts their completeness, thereby hindering their full utilization in LLMs. Our analysis enhances the understanding of how LLMs merge diverse contexts, offering valuable insights for advancing current augmentation methods for LLMs.