 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Reinforcement Learning with Self-Reflection for Agentic Search
Mar 11, 2026This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically, MR-Search performs cross-episode exploration by generating explicit self-reflections after each episode and leveraging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. We further introduce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained credit assignment on each episode. Empirical results across various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing strong generalization and relative improvements of 9.2% to 19.3% across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR-Search.
R$^2$PO: Decoupling Training Trajectories from Inference Responses for LLM Reasoning
Jan 17, 2026Reinforcement learning has become a central paradigm for improving LLM reasoning. However, existing methods use a single policy to produce both inference responses and training optimization trajectories. The objective conflict between generating stable inference responses and diverse training trajectories leads to insufficient exploration, which harms reasoning capability. In this paper, to address the problem, we propose R$^2$PO (Residual Rollout Policy Optimization), which introduces a lightweight Residual Rollout-Head atop the policy to decouple training trajectories from inference responses, enabling controlled trajectory diversification during training while keeping inference generation stable. Experiments across multiple benchmarks show that our method consistently outperforms baselines, achieving average accuracy gains of 3.1% on MATH-500 and 2.4% on APPS, while also reducing formatting errors and mitigating length bias for stable optimization. Our code is publicly available at https://github.com/RRPO-ARR/Code.
Do We Always Need Query-Level Workflows? Rethinking Agentic Workflow Generation for Multi-Agent Systems
Jan 16, 2026Multi-Agent Systems (MAS) built on large language models typically solve complex tasks by coordinating multiple agents through workflows. Existing approaches generates workflows either at task level or query level, but their relative costs and benefits remain unclear. After rethinking and empirical analyses, we show that query-level workflow generation is not always necessary, since a small set of top-K best task-level workflows together already covers equivalent or even more queries. We further find that exhaustive execution-based task-level evaluation is both extremely token-costly and frequently unreliable. Inspired by the idea of self-evolution and generative reward modeling, we propose a low-cost task-level generation framework \textbf{SCALE}, which means \underline{\textbf{S}}elf prediction of the optimizer with few shot \underline{\textbf{CAL}}ibration for \underline{\textbf{E}}valuation instead of full validation execution. Extensive experiments demonstrate that \textbf{SCALE} maintains competitive performance, with an average degradation of just 0.61\% compared to existing approach across multiple datasets, while cutting overall token usage by up to 83\%.
GIFT: Games as Informal Training for Generalizable LLMs
Jan 09, 2026While Large Language Models (LLMs) have achieved remarkable success in formal learning tasks such as mathematics and code generation, they still struggle with the "practical wisdom" and generalizable intelligence, such as strategic creativity and social reasoning, that characterize human cognition. This gap arises from a lack of informal learning, which thrives on interactive feedback rather than goal-oriented instruction. In this paper, we propose treating Games as a primary environment for LLM informal learning, leveraging their intrinsic reward signals and abstracted complexity to cultivate diverse competencies. To address the performance degradation observed in multi-task learning, we introduce a Nested Training Framework. Unlike naive task mixing optimizing an implicit "OR" objective, our framework employs sequential task composition to enforce an explicit "AND" objective, compelling the model to master multiple abilities simultaneously to achieve maximal rewards. Using GRPO-based reinforcement learning across Matrix Games, TicTacToe, and Who's the Spy games, we demonstrate that integrating game-based informal learning not only prevents task interference but also significantly bolsters the model's generalization across broad ability-oriented benchmarks. The framework and implementation are publicly available.
Simple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
From Outcomes to Processes: Guiding PRM Learning from ORM for Inference-Time Alignment
Jun 14, 2025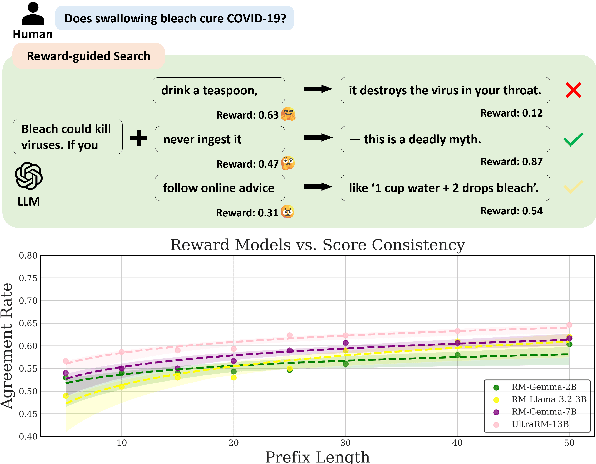
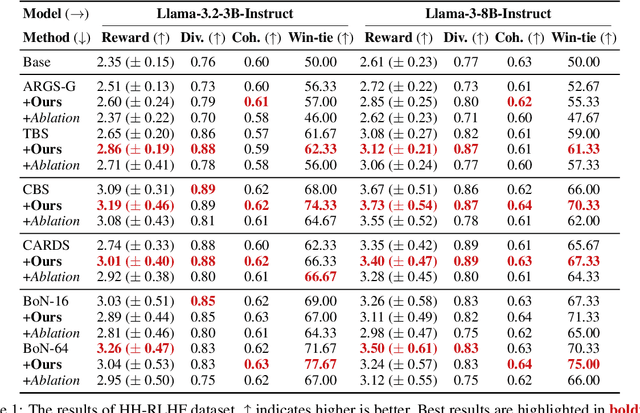
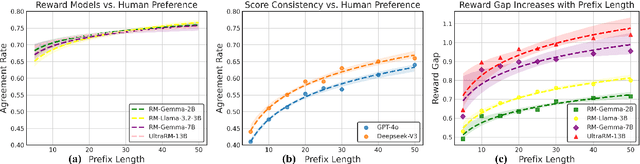

Inference-time alignment methods have gained significant attention for their efficiency and effectiveness in aligning large language models (LLMs) with human preferences. However, existing dominant approaches using reward-guided search (RGS) primarily rely on outcome reward models (ORMs), which suffer from a critical granularity mismatch: ORMs are designed to provide outcome rewards for complete responses, while RGS methods rely on process rewards to guide the policy, leading to inconsistent scoring and suboptimal alignment. To address this challenge, we introduce process reward models (PRMs) into RGS and argue that an ideal PRM should satisfy two objectives: Score Consistency, ensuring coherent evaluation across partial and complete responses, and Preference Consistency, aligning partial sequence assessments with human preferences. Based on these, we propose SP-PRM, a novel dual-consistency framework integrating score consistency-based and preference consistency-based partial evaluation modules without relying on human annotation. Extensive experiments on dialogue, summarization, and reasoning tasks demonstrate that SP-PRM substantially enhances existing RGS methods, achieving a 3.6%-10.3% improvement in GPT-4 evaluation scores across all tasks.
Incentivizing Strong Reasoning from Weak Supervision
May 28, 2025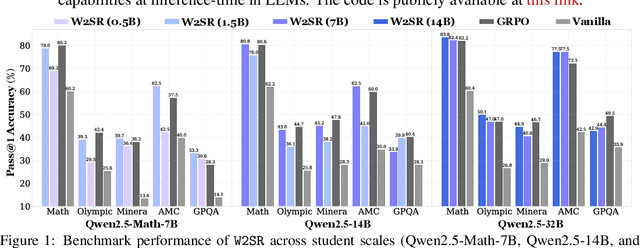
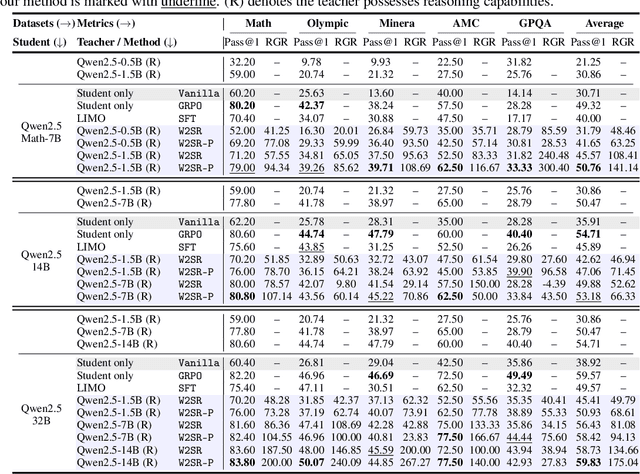
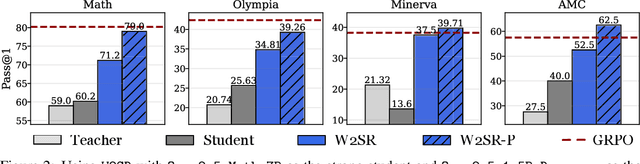
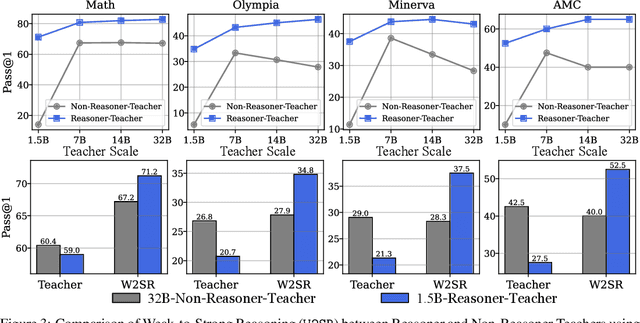
Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/w2sr.
Incentivizing Reasoning from Weak Supervision
May 26, 2025Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/W2SR.
Inference-time Alignment in Continuous Space
May 26, 2025Aligning large language models with human feedback at inference time has received increasing attention due to its flexibility. Existing methods rely on generating multiple responses from the base policy for search using a reward model, which can be considered as searching in a discrete response space. However, these methods struggle to explore informative candidates when the base policy is weak or the candidate set is small, resulting in limited effectiveness. In this paper, to address this problem, we propose Simple Energy Adaptation ($\textbf{SEA}$), a simple yet effective algorithm for inference-time alignment. In contrast to expensive search over the discrete space, SEA directly adapts original responses from the base policy toward the optimal one via gradient-based sampling in continuous latent space. Specifically, SEA formulates inference as an iterative optimization procedure on an energy function over actions in the continuous space defined by the optimal policy, enabling simple and effective alignment. For instance, despite its simplicity, SEA outperforms the second-best baseline with a relative improvement of up to $ \textbf{77.51%}$ on AdvBench and $\textbf{16.36%}$ on MATH. Our code is publicly available at https://github.com/yuanyige/SEA
InfoNCE is a Free Lunch for Semantically guided Graph Contrastive Learning
May 07, 2025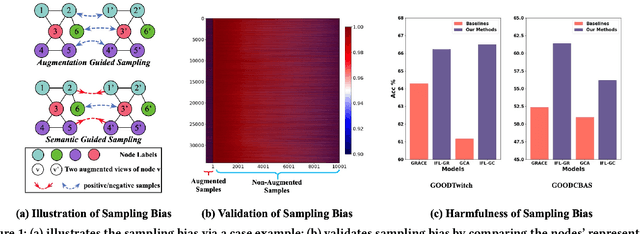
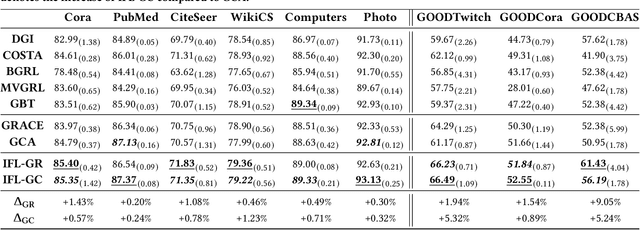
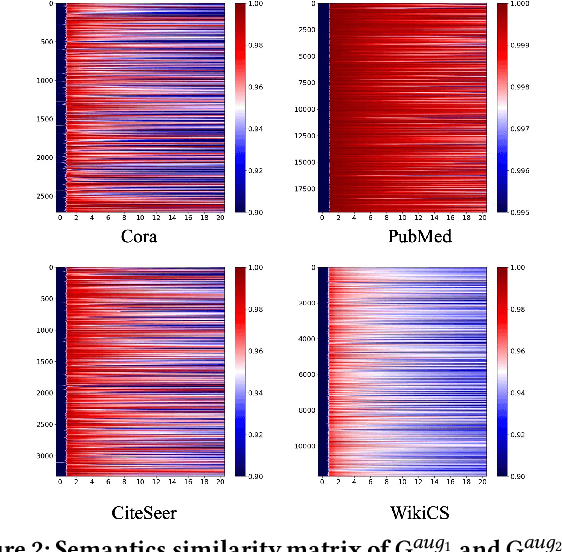
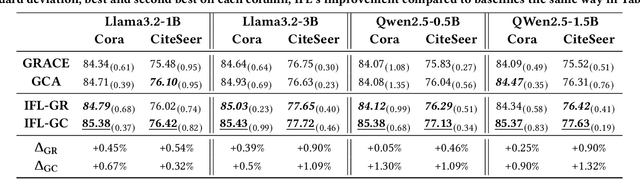
As an important graph pre-training method, Graph Contrastive Learning (GCL) continues to play a crucial role in the ongoing surge of research on graph foundation models or LLM as enhancer for graphs. Traditional GCL optimizes InfoNCE by using augmentations to define self-supervised tasks, treating augmented pairs as positive samples and others as negative. However, this leads to semantically similar pairs being classified as negative, causing significant sampling bias and limiting performance. In this paper, we argue that GCL is essentially a Positive-Unlabeled (PU) learning problem, where the definition of self-supervised tasks should be semantically guided, i.e., augmented samples with similar semantics are considered positive, while others, with unknown semantics, are treated as unlabeled. From this perspective, the key lies in how to extract semantic information. To achieve this, we propose IFL-GCL, using InfoNCE as a "free lunch" to extract semantic information. Specifically, We first prove that under InfoNCE, the representation similarity of node pairs aligns with the probability that the corresponding contrastive sample is positive. Then we redefine the maximum likelihood objective based on the corrected samples, leading to a new InfoNCE loss function. Extensive experiments on both the graph pretraining framework and LLM as an enhancer show significantly improvements of IFL-GCL in both IID and OOD scenarios, achieving up to a 9.05% improvement, validating the effectiveness of semantically guided. Code for IFL-GCL is publicly available at: https://github.com/Camel-Prince/IFL-GCL.