 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMA: Real-time Omni-Multimodal Assistant with Interactive Streaming Understanding
Jan 15, 2026Recent Omni-multimodal Large Language Models show promise in unified audio, vision, and text modeling. However, streaming audio-video understanding remains challenging, as existing approaches suffer from disjointed capabilities: they typically exhibit incomplete modality support or lack autonomous proactive monitoring. To address this, we present ROMA, a real-time omni-multimodal assistant for unified reactive and proactive interaction. ROMA processes continuous inputs as synchronized multimodal units, aligning dense audio with discrete video frames to handle granularity mismatches. For online decision-making, we introduce a lightweight speak head that decouples response initiation from generation to ensure precise triggering without task conflict. We train ROMA with a curated streaming dataset and a two-stage curriculum that progressively optimizes for streaming format adaptation and proactive responsiveness. To standardize the fragmented evaluation landscape, we reorganize diverse benchmarks into a unified suite covering both proactive (alert, narration) and reactive (QA) settings. Extensive experiments across 12 benchmarks demonstrate ROMA achieves state-of-the-art performance on proactive tasks while competitive in reactive settings, validating its robustness in unified real-time omni-multimodal understanding.
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain Generalization
Jan 08, 2026Supervised fine-tuning (SFT) on chain-of-thought (CoT) trajectories demonstrations is a common approach for enabling reasoning in large language models. Standard practices typically only retain trajectories with correct final answers (positives) while ignoring the rest (negatives). We argue that this paradigm discards substantial supervision and exacerbates overfitting, limiting out-of-domain (OOD) generalization. Specifically, we surprisingly find that incorporating negative trajectories into SFT yields substantial OOD generalization gains over positive-only training, as these trajectories often retain valid intermediate reasoning despite incorrect final answers. To understand this effect in depth, we systematically analyze data, training dynamics, and inference behavior, identifying 22 recurring patterns in negative chains that serve a dual role: they moderate loss descent to mitigate overfitting during training and boost policy entropy by 35.67% during inference to facilitate exploration. Motivated by these observations, we further propose Gain-based LOss Weighting (GLOW), an adaptive, sample-aware scheme that exploits such distinctive training dynamics by rescaling per-sample loss based on inter-epoch progress. Empirically, GLOW efficiently leverages unfiltered trajectories, yielding a 5.51% OOD gain over positive-only SFT on Qwen2.5-7B and boosting MMLU from 72.82% to 76.47% as an RL initialization.
Rethinking All Evidence: Enhancing Trustworthy Retrieval-Augmented Generation via Conflict-Driven Summarization
Jul 02, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating their parametric knowledge with external retrieved content. However, knowledge conflicts caused by internal inconsistencies or noisy retrieved content can severely undermine the generation reliability of RAG systems.In this work, we argue that LLMs should rethink all evidence, including both retrieved content and internal knowledge, before generating responses.We propose CARE-RAG (Conflict-Aware and Reliable Evidence for RAG), a novel framework that improves trustworthiness through Conflict-Driven Summarization of all available evidence.CARE-RAG first derives parameter-aware evidence by comparing parameter records to identify diverse internal perspectives. It then refines retrieved evidences to produce context-aware evidence, removing irrelevant or misleading content. To detect and summarize conflicts, we distill a 3B LLaMA3.2 model to perform conflict-driven summarization, enabling reliable synthesis across multiple sources.To further ensure evaluation integrity, we introduce a QA Repair step to correct outdated or ambiguous benchmark answers.Experiments on revised QA datasets with retrieval data show that CARE-RAG consistently outperforms strong RAG baselines, especially in scenarios with noisy or conflicting evidence.
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
CheXLearner: Text-Guided Fine-Grained Representation Learning for Progression Detection
May 11, 2025



Temporal medical image analysis is essential for clinical decision-making, yet existing methods either align images and text at a coarse level - causing potential semantic mismatches - or depend solely on visual information, lacking medical semantic integration. We present CheXLearner, the first end-to-end framework that unifies anatomical region detection, Riemannian manifold-based structure alignment, and fine-grained regional semantic guidance. Our proposed Med-Manifold Alignment Module (Med-MAM) leverages hyperbolic geometry to robustly align anatomical structures and capture pathologically meaningful discrepancies across temporal chest X-rays. By introducing regional progression descriptions as supervision, CheXLearner achieves enhanced cross-modal representation learning and supports dynamic low-level feature optimization. Experiments show that CheXLearner achieves 81.12% (+17.2%) average accuracy and 80.32% (+11.05%) F1-score on anatomical region progression detection - substantially outperforming state-of-the-art baselines, especially in structurally complex regions. Additionally, our model attains a 91.52% average AUC score in downstream disease classification, validating its superior feature representation.
MIGE: A Unified Framework for Multimodal Instruction-Based Image Generation and Editing
Feb 28, 2025Despite significant progress in diffusion-based image generation, subject-driven generation and instruction-based editing remain challenging. Existing methods typically treat them separately, struggling with limited high-quality data and poor generalization. However, both tasks require capturing complex visual variations while maintaining consistency between inputs and outputs. Therefore, we propose MIGE, a unified framework that standardizes task representations using multimodal instructions. It treats subject-driven generation as creation on a blank canvas and instruction-based editing as modification of an existing image, establishing a shared input-output formulation. MIGE introduces a novel multimodal encoder that maps free-form multimodal instructions into a unified vision-language space, integrating visual and semantic features through a feature fusion mechanism.This unification enables joint training of both tasks, providing two key advantages: (1) Cross-Task Enhancement: By leveraging shared visual and semantic representations, joint training improves instruction adherence and visual consistency in both subject-driven generation and instruction-based editing. (2) Generalization: Learning in a unified format facilitates cross-task knowledge transfer, enabling MIGE to generalize to novel compositional tasks, including instruction-based subject-driven editing. Experiments show that MIGE excels in both subject-driven generation and instruction-based editing while setting a state-of-the-art in the new task of instruction-based subject-driven editing. Code and model have been publicly available at https://github.com/Eureka-Maggie/MIGE.
A Survey on LLM-as-a-Judge
Nov 23, 2024Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey of LLM-as-a-Judge, addressing the core question: How can reliable LLM-as-a-Judge systems be built? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.
Unlocking the Power of Large Language Models for Entity Alignment
Feb 23, 2024



Entity Alignment (EA) is vital for integrating diverse knowledge graph (KG) data, playing a crucial role in data-driven AI applications. Traditional EA methods primarily rely on comparing entity embeddings, but their effectiveness is constrained by the limited input KG data and the capabilities of the representation learning techniques. Against this backdrop, we introduce ChatEA, an innovative framework that incorporates large language models (LLMs) to improve EA. To address the constraints of limited input KG data, ChatEA introduces a KG-code translation module that translates KG structures into a format understandable by LLMs, thereby allowing LLMs to utilize their extensive background knowledge to improve EA accuracy. To overcome the over-reliance on entity embedding comparisons, ChatEA implements a two-stage EA strategy that capitalizes on LLMs' capability for multi-step reasoning in a dialogue format, thereby enhancing accuracy while preserving efficiency. Our experimental results affirm ChatEA's superior performance, highlighting LLMs' potential in facilitating EA tasks.
Qsnail: A Questionnaire Dataset for Sequential Question Generation
Feb 22, 2024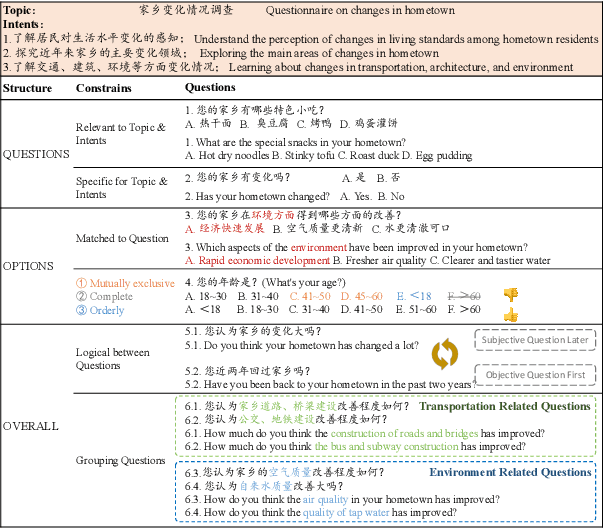

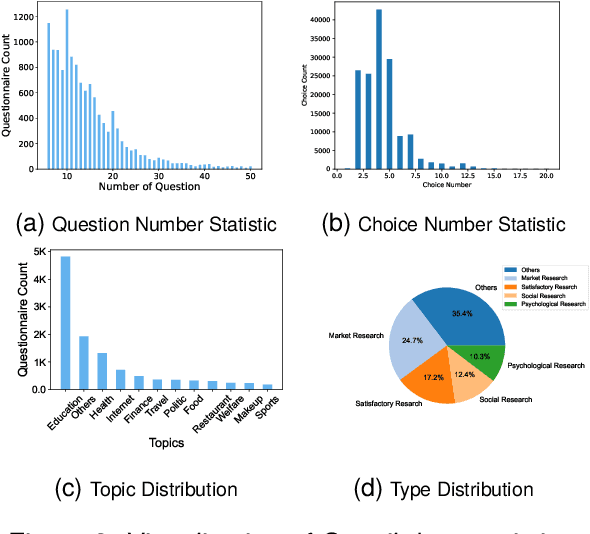
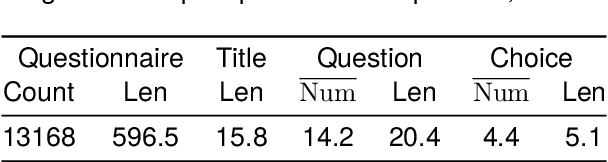
The questionnaire is a professional research methodology used for both qualitative and quantitative analysis of human opinions, preferences, attitudes, and behaviors. However, designing and evaluating questionnaires demands significant effort due to their intricate and complex structure. Questionnaires entail a series of questions that must conform to intricate constraints involving the questions, options, and overall structure. Specifically, the questions should be relevant and specific to the given research topic and intent. The options should be tailored to the questions, ensuring they are mutually exclusive, completed, and ordered sensibly. Moreover, the sequence of questions should follow a logical order, grouping similar topics together. As a result, automatically generating questionnaires presents a significant challenge and this area has received limited attention primarily due to the scarcity of high-quality datasets. To address these issues, we present Qsnail, the first dataset specifically constructed for the questionnaire generation task, which comprises 13,168 human-written questionnaires gathered from online platforms. We further conduct experiments on Qsnail, and the results reveal that retrieval models and traditional generative models do not fully align with the given research topic and intents. Large language models, while more closely related to the research topic and intents, exhibit significant limitations in terms of diversity and specificity. Despite enhancements through the chain-of-thought prompt and finetuning, questionnaires generated by language models still fall short of human-written questionnaires. Therefore, questionnaire generation is challenging and needs to be further explored. The dataset is available at: https://github.com/LeiyanGithub/qsnail.