 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaAct: Simulating Short-Video Users with Personalized Agents for Counterfactual Filter Bubble Auditing
Jan 30, 2026Short-video platforms rely on personalized recommendation, raising concerns about filter bubbles that narrow content exposure. Auditing such phenomena at scale is challenging because real user studies are costly and privacy-sensitive, and existing simulators fail to reproduce realistic behaviors due to their reliance on textual signals and weak personalization. We propose PersonaAct, a framework for simulating short-video users with persona-conditioned multimodal agents trained on real behavioral traces for auditing filter bubbles in breadth and depth. PersonaAct synthesizes interpretable personas through automated interviews combining behavioral analysis with structured questioning, then trains agents on multimodal observations using supervised fine-tuning and reinforcement learning. We deploy trained agents for filter bubble auditing and evaluate bubble breadth via content diversity and bubble depth via escape potential. The evaluation demonstrates substantial improvements in fidelity over generic LLM baselines, enabling realistic behavior reproduction. Results reveal significant content narrowing over interaction. However, we find that Bilibili demonstrates the strongest escape potential. We release the first open multimodal short-video dataset and code to support reproducible auditing of recommender systems.
BaseCal: Unsupervised Confidence Calibration via Base Model Signals
Jan 08, 2026Reliable confidence is essential for trusting the outputs of LLMs, yet widely deployed post-trained LLMs (PoLLMs) typically compromise this trust with severe overconfidence. In contrast, we observe that their corresponding base LLMs often remain well-calibrated. This naturally motivates us to calibrate PoLLM confidence using the base LLM as a reference. This work proposes two ways to achieve this. A straightforward solution, BaseCal-ReEval, evaluates PoLLM's responses by feeding them into the base LLM to get average probabilities as confidence. While effective, this approach introduces additional inference overhead. To address this, we propose BaseCal-Proj, which trains a lightweight projection to map the final-layer hidden states of PoLLMs back to those of their base LLMs. These projected states are then processed by the base LLM's output layer to derive base-calibrated confidence for PoLLM's responses. Notably, BaseCal is an unsupervised, plug-and-play solution that operates without human labels or LLM modifications. Experiments across five datasets and three LLM families demonstrate the effectiveness of BaseCal, reducing Expected Calibration Error (ECE) by an average of 42.90\% compared to the best unsupervised baselines.
Safety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis
Jan 07, 2026Safety alignment in Large Language Models (LLMs) inherently presents a multi-objective optimization conflict, often accompanied by an unintended degradation of general capabilities. Existing mitigation strategies typically rely on global gradient geometry to resolve these conflicts, yet they overlook Modular Heterogeneity within Transformers, specifically that the functional sensitivity and degree of conflict vary substantially across different attention heads. Such global approaches impose uniform update rules across all parameters, often resulting in suboptimal trade-offs by indiscriminately updating utility sensitive heads that exhibit intense gradient conflicts. To address this limitation, we propose Conflict-Aware Sparse Tuning (CAST), a framework that integrates head-level diagnosis with sparse fine-tuning. CAST first constructs a pre-alignment conflict map by synthesizing Optimization Conflict and Functional Sensitivity, which then guides the selective update of parameters. Experiments reveal that alignment conflicts in LLMs are not uniformly distributed. We find that the drop in general capabilities mainly comes from updating a small group of ``high-conflict'' heads. By simply skipping these heads during training, we significantly reduce this loss without compromising safety, offering an interpretable and parameter-efficient approach to improving the safety-utility trade-off.
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood
Oct 10, 2025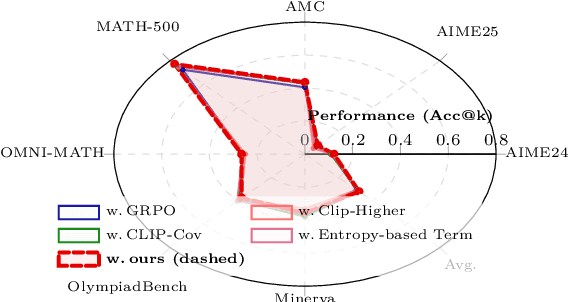
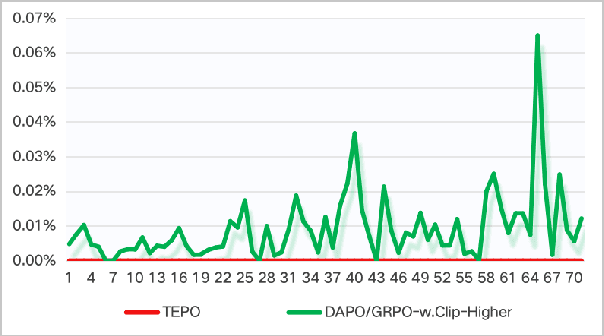
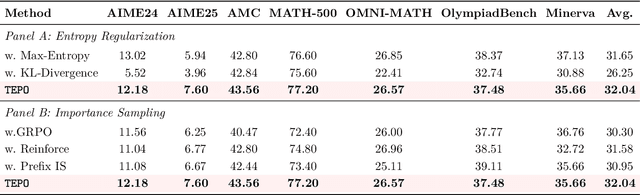
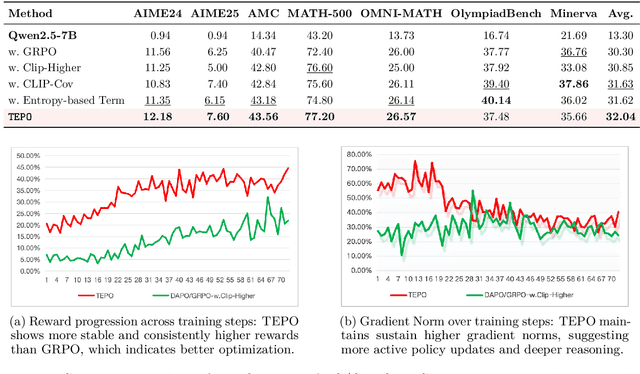
Group Relative Policy Optimization (GRPO) has significantly advanced the reasoning ability of large language models (LLMs), particularly by boosting their mathematical performance. However, GRPO and related entropy-regularization methods still face challenges rooted in the sparse token rewards inherent to chain-of-thought (CoT). Current approaches often rely on undifferentiated token-level entropy adjustments, which frequently lead to entropy collapse or model collapse. In this work, we propose TEPO, a novel token-level framework that incorporates Markov Likelihood (sequence likelihood) links group-level rewards with tokens via token-level aggregation. Experiments show that TEPO consistently outperforms existing baselines across key metrics (including @k and accuracy). It not only sets a new state of the art on mathematical reasoning tasks but also significantly enhances training stability.
Fine-tuning Done Right in Model Editing
Sep 26, 2025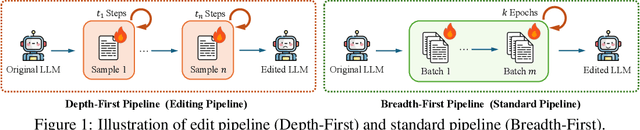
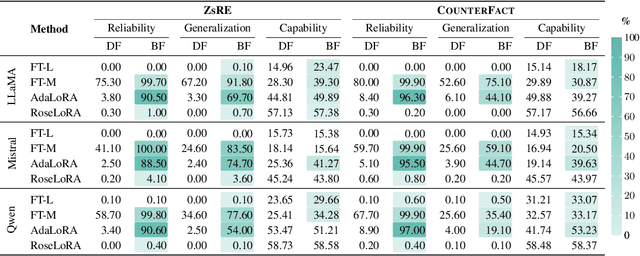
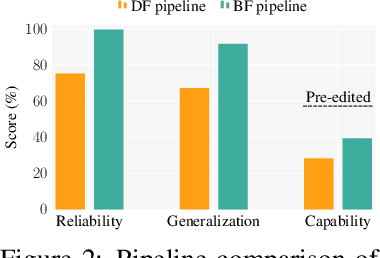

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
LLM4MEA: Data-free Model Extraction Attacks on Sequential Recommenders via Large Language Models
Jul 22, 2025Recent studies have demonstrated the vulnerability of sequential recommender systems to Model Extraction Attacks (MEAs). MEAs collect responses from recommender systems to replicate their functionality, enabling unauthorized deployments and posing critical privacy and security risks. Black-box attacks in prior MEAs are ineffective at exposing recommender system vulnerabilities due to random sampling in data selection, which leads to misaligned synthetic and real-world distributions. To overcome this limitation, we propose LLM4MEA, a novel model extraction method that leverages Large Language Models (LLMs) as human-like rankers to generate data. It generates data through interactions between the LLM ranker and target recommender system. In each interaction, the LLM ranker analyzes historical interactions to understand user behavior, and selects items from recommendations with consistent preferences to extend the interaction history, which serves as training data for MEA. Extensive experiments demonstrate that LLM4MEA significantly outperforms existing approaches in data quality and attack performance, reducing the divergence between synthetic and real-world data by up to 64.98% and improving MEA performance by 44.82% on average. From a defensive perspective, we propose a simple yet effective defense strategy and identify key hyperparameters of recommender systems that can mitigate the risk of MEAs.
Knowledgeable-r1: Policy Optimization for Knowledge Exploration in Retrieval-Augmented Generation
Jun 05, 2025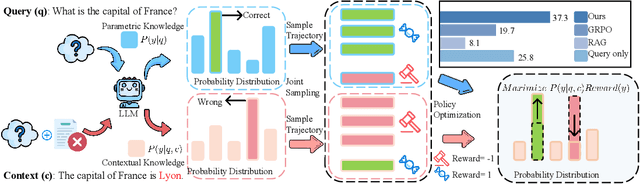

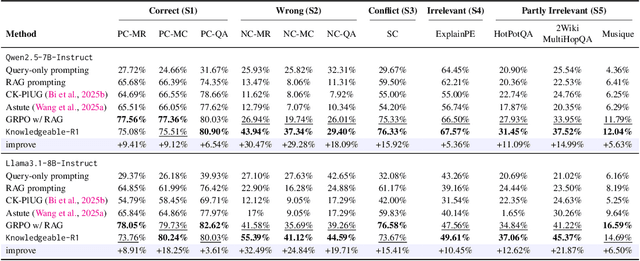
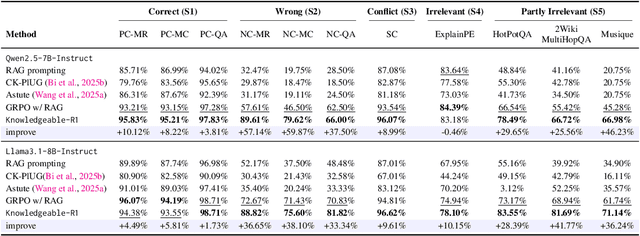
Retrieval-augmented generation (RAG) is a mainstream method for improving performance on knowledge-intensive tasks. However,current RAG systems often place too much emphasis on retrieved contexts. This can lead to reliance on inaccurate sources and overlook the model's inherent knowledge, especially when dealing with misleading or excessive information. To resolve this imbalance, we propose Knowledgeable-r1 that using joint sampling and define multi policy distributions in knowledge capability exploration to stimulate large language models'self-integrated utilization of parametric and contextual knowledge. Experiments show that Knowledgeable-r1 significantly enhances robustness and reasoning accuracy in both parameters and contextual conflict tasks and general RAG tasks, especially outperforming baselines by 17.07% in counterfactual scenarios and demonstrating consistent gains across RAG tasks. Our code are available at https://github.com/lcy80366872/ knowledgeable-r1.
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
The 1st Workshop on Human-Centered Recommender Systems
Nov 22, 2024
Recommender systems are quintessential applications of human-computer interaction. Widely utilized in daily life, they offer significant convenience but also present numerous challenges, such as the information cocoon effect, privacy concerns, fairness issues, and more. Consequently, this workshop aims to provide a platform for researchers to explore the development of Human-Centered Recommender Systems~(HCRS). HCRS refers to the creation of recommender systems that prioritize human needs, values, and capabilities at the core of their design and operation. In this workshop, topics will include, but are not limited to, robustness, privacy, transparency, fairness, diversity, accountability, ethical considerations, and user-friendly design. We hope to engage in discussions on how to implement and enhance these properties in recommender systems. Additionally, participants will explore diverse evaluation methods, including innovative metrics that capture user satisfaction and trust. This workshop seeks to foster a collaborative environment for researchers to share insights and advance the field toward more ethical, user-centric, and socially responsible recommender systems.
The Fall of ROME: Understanding the Collapse of LLMs in Model Editing
Jun 17, 2024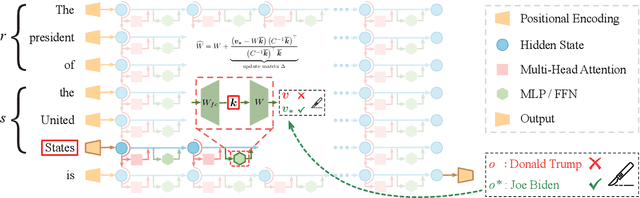
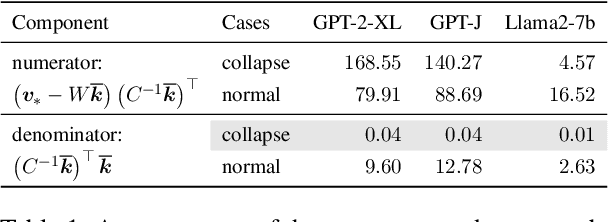
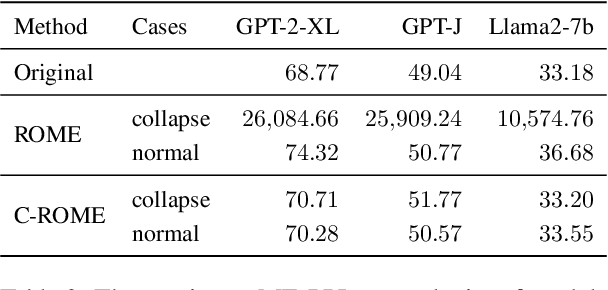
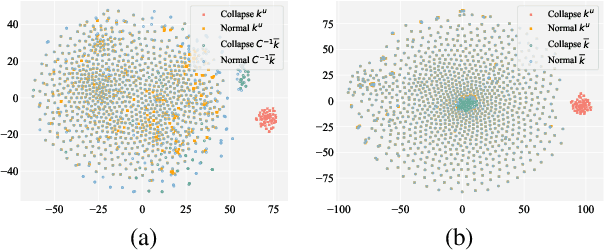
Despite significant progress in model editing methods, their application in real-world scenarios remains challenging as they often cause large language models (LLMs) to collapse. Among them, ROME is particularly concerning, as it could disrupt LLMs with only a single edit. In this paper, we study the root causes of such collapse. Through extensive analysis, we identify two primary factors that contribute to the collapse: i) inconsistent handling of prefixed and unprefixed keys in the parameter update equation may result in very small denominators, causing excessively large parameter updates; ii) the subject of collapse cases is usually the first token, whose unprefixed key distribution significantly differs from the prefixed key distribution in autoregressive transformers, causing the aforementioned issue to materialize. To validate our analysis, we propose a simple yet effective approach: uniformly using prefixed keys during editing phase and adding prefixes during the testing phase. The experimental results show that the proposed solution can prevent model collapse while maintaining the effectiveness of the edits.