 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashEvaluator: Expanding Search Space with Parallel Evaluation
Mar 03, 2026The Generator-Evaluator (G-E) framework, i.e., evaluating K sequences from a generator and selecting the top-ranked one according to evaluator scores, is a foundational paradigm in tasks such as Recommender Systems (RecSys) and Natural Language Processing (NLP). Traditional evaluators process sequences independently, suffering from two major limitations: (1) lack of explicit cross-sequence comparison, leading to suboptimal accuracy; (2) poor parallelization with linear complexity of O(K), resulting in inefficient resource utilization and negative impact on both throughput and latency. To address these challenges, we propose FlashEvaluator, which enables cross-sequence token information sharing and processes all sequences in a single forward pass. This yields sublinear computational complexity that improves the system's efficiency and supports direct inter-sequence comparisons that improve selection accuracy. The paper also provides theoretical proofs and extensive experiments on recommendation and NLP tasks, demonstrating clear advantages over conventional methods. Notably, FlashEvaluator has been deployed in online recommender system of Kuaishou, delivering substantial and sustained revenue gains in practice.
GoalRank: Group-Relative Optimization for a Large Ranking Model
Sep 26, 2025Mainstream ranking approaches typically follow a Generator-Evaluator two-stage paradigm, where a generator produces candidate lists and an evaluator selects the best one. Recent work has attempted to enhance performance by expanding the number of candidate lists, for example, through multi-generator settings. However, ranking involves selecting a recommendation list from a combinatorially large space. Simply enlarging the candidate set remains ineffective, and performance gains quickly saturate. At the same time, recent advances in large recommendation models have shown that end-to-end one-stage models can achieve promising performance with the expectation of scaling laws. Motivated by this, we revisit ranking from a generator-only one-stage perspective. We theoretically prove that, for any (finite Multi-)Generator-Evaluator model, there always exists a generator-only model that achieves strictly smaller approximation error to the optimal ranking policy, while also enjoying scaling laws as its size increases. Building on this result, we derive an evidence upper bound of the one-stage optimization objective, from which we find that one can leverage a reward model trained on real user feedback to construct a reference policy in a group-relative manner. This reference policy serves as a practical surrogate of the optimal policy, enabling effective training of a large generator-only ranker. Based on these insights, we propose GoalRank, a generator-only ranking framework. Extensive offline experiments on public benchmarks and large-scale online A/B tests demonstrate that GoalRank consistently outperforms state-of-the-art methods.
Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025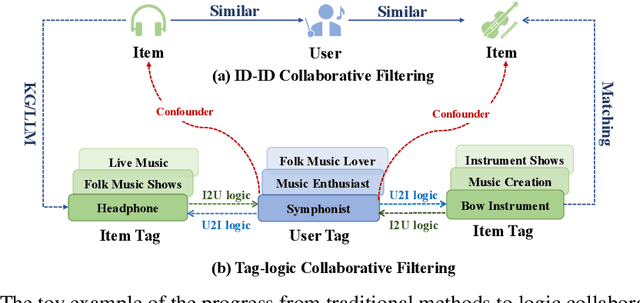
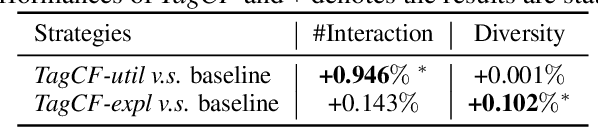
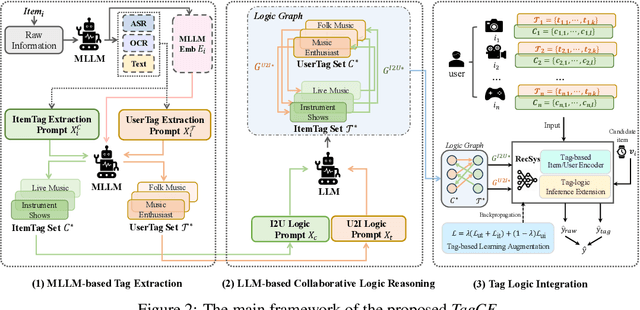
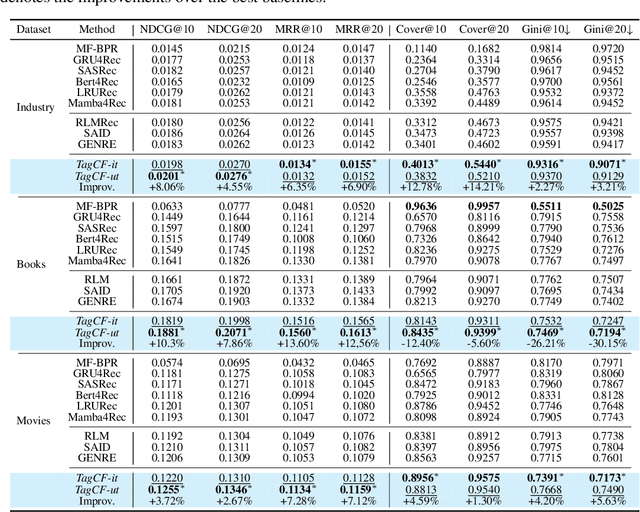
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
Comprehensive List Generation for Multi-Generator Reranking
Apr 22, 2025Reranking models solve the final recommendation lists that best fulfill users' demands. While existing solutions focus on finding parametric models that approximate optimal policies, recent approaches find that it is better to generate multiple lists to compete for a ``pass'' ticket from an evaluator, where the evaluator serves as the supervisor who accurately estimates the performance of the candidate lists. In this work, we show that we can achieve a more efficient and effective list proposal with a multi-generator framework and provide empirical evidence on two public datasets and online A/B tests. More importantly, we verify that the effectiveness of a generator is closely related to how much it complements the views of other generators with sufficiently different rerankings, which derives the metric of list comprehensiveness. With this intuition, we design an automatic complementary generator-finding framework that learns a policy that simultaneously aligns the users' preferences and maximizes the list comprehensiveness metric. The experimental results indicate that the proposed framework can further improve the multi-generator reranking performance.
* 11 pages, 6 figures, 9 tables
Explicit Uncertainty Modeling for Video Watch Time Prediction
Apr 10, 2025In video recommendation, a critical component that determines the system's recommendation accuracy is the watch-time prediction module, since how long a user watches a video directly reflects personalized preferences. One of the key challenges of this problem is the user's stochastic watch-time behavior. To improve the prediction accuracy for such an uncertain behavior, existing approaches show that one can either reduce the noise through duration bias modeling or formulate a distribution modeling task to capture the uncertainty. However, the uncontrolled uncertainty is not always equally distributed across users and videos, inducing a balancing paradox between the model accuracy and the ability to capture out-of-distribution samples. In practice, we find that the uncertainty of the watch-time prediction model also provides key information about user behavior, which, in turn, could benefit the prediction task itself. Following this notion, we derive an explicit uncertainty modeling strategy for the prediction model and propose an adversarial optimization framework that can better exploit the user watch-time behavior. This framework has been deployed online on an industrial video sharing platform that serves hundreds of millions of daily active users, which obtains a significant increase in users' video watch time by 0.31% through the online A/B test. Furthermore, extended offline experiments on two public datasets verify the effectiveness of the proposed framework across various watch-time prediction backbones.
Stratified Expert Cloning with Adaptive Selection for User Retention in Large-Scale Recommender Systems
Apr 08, 2025



User retention has emerged as a critical challenge in large-scale recommender systems, significantly impacting the long-term success of online platforms. Existing methods often focus on short-term engagement metrics, failing to capture the complex dynamics of user preferences and behaviors over extended periods. While reinforcement learning (RL) approaches have shown promise in optimizing long-term rewards, they face difficulties in credit assignment, sample efficiency, and exploration when applied to the user retention problem. In this work, we propose Stratified Expert Cloning (SEC), a novel imitation learning framework that effectively leverages abundant logged data from high-retention users to learn robust recommendation policies. SEC introduces three key innovations: 1) a multi-level expert stratification strategy that captures the nuances in expert user behaviors at different retention levels; 2) an adaptive expert selection mechanism that dynamically assigns users to the most suitable policy based on their current state and historical retention level; and 3) an action entropy regularization technique that promotes recommendation diversity and mitigates the risk of policy collapse. Through extensive offline experiments and online A/B tests on two major video platforms, Kuaishou and Kuaishou Lite, with hundreds of millions of daily active users, we demonstrate SEC's significant improvements over state-of-the-art methods in user retention. The results demonstrate significant improvements in user retention, with cumulative lifts of 0.098\% and 0.122\% in active days on Kuaishou and Kuaishou Lite respectively, additionally bringing tens of thousands of daily active users to each platform.
Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation
Jan 29, 2025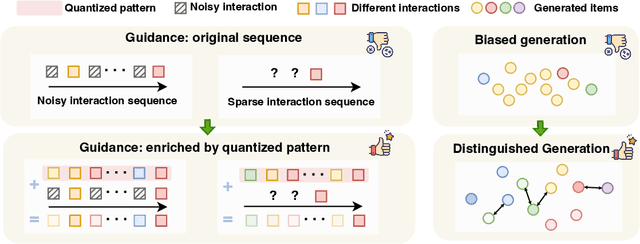
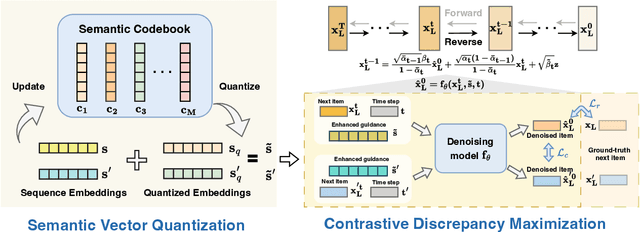
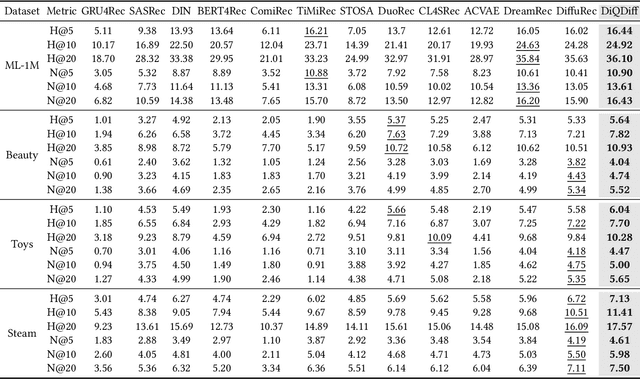
Diffusion models (DMs) have emerged as promising approaches for sequential recommendation due to their strong ability to model data distributions and generate high-quality items. Existing work typically adds noise to the next item and progressively denoises it guided by the user's interaction sequence, generating items that closely align with user interests. However, we identify two key issues in this paradigm. First, the sequences are often heterogeneous in length and content, exhibiting noise due to stochastic user behaviors. Using such sequences as guidance may hinder DMs from accurately understanding user interests. Second, DMs are prone to data bias and tend to generate only the popular items that dominate the training dataset, thus failing to meet the personalized needs of different users. To address these issues, we propose Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation (DiQDiff), which aims to extract robust guidance to understand user interests and generate distinguished items for personalized user interests within DMs. To extract robust guidance, DiQDiff introduces Semantic Vector Quantization (SVQ) to quantize sequences into semantic vectors (e.g., collaborative signals and category interests) using a codebook, which can enrich the guidance to better understand user interests. To generate distinguished items, DiQDiff personalizes the generation through Contrastive Discrepancy Maximization (CDM), which maximizes the distance between denoising trajectories using contrastive loss to prevent biased generation for different users. Extensive experiments are conducted to compare DiQDiff with multiple baseline models across four widely-used datasets. The superior recommendation performance of DiQDiff against leading approaches demonstrates its effectiveness in sequential recommendation tasks.
Value Function Decomposition in Markov Recommendation Process
Jan 29, 2025



Recent advances in recommender systems have shown that user-system interaction essentially formulates long-term optimization problems, and online reinforcement learning can be adopted to improve recommendation performance. The general solution framework incorporates a value function that estimates the user's expected cumulative rewards in the future and guides the training of the recommendation policy. To avoid local maxima, the policy may explore potential high-quality actions during inference to increase the chance of finding better future rewards. To accommodate the stepwise recommendation process, one widely adopted approach to learning the value function is learning from the difference between the values of two consecutive states of a user. However, we argue that this paradigm involves an incorrect approximation in the stochastic process. Specifically, between the current state and the next state in each training sample, there exist two separate random factors from the stochastic policy and the uncertain user environment. Original temporal difference (TD) learning under these mixed random factors may result in a suboptimal estimation of the long-term rewards. As a solution, we show that these two factors can be separately approximated by decomposing the original temporal difference loss. The disentangled learning framework can achieve a more accurate estimation with faster learning and improved robustness against action exploration. As empirical verification of our proposed method, we conduct offline experiments with online simulated environments built based on public datasets.
Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer
Jan 13, 2025Securing long-term success is the ultimate aim of recommender systems, demanding strategies capable of foreseeing and shaping the impact of decisions on future user satisfaction. Current recommendation strategies grapple with two significant hurdles. Firstly, the future impacts of recommendation decisions remain obscured, rendering it impractical to evaluate them through direct optimization of immediate metrics. Secondly, conflicts often emerge between multiple objectives, like enhancing accuracy versus exploring diverse recommendations. Existing strategies, trapped in a "training, evaluation, and retraining" loop, grow more labor-intensive as objectives evolve. To address these challenges, we introduce a future-conditioned strategy for multi-objective controllable recommendations, allowing for the direct specification of future objectives and empowering the model to generate item sequences that align with these goals autoregressively. We present the Multi-Objective Controllable Decision Transformer (MocDT), an offline Reinforcement Learning (RL) model capable of autonomously learning the mapping from multiple objectives to item sequences, leveraging extensive offline data. Consequently, it can produce recommendations tailored to any specified objectives during the inference stage. Our empirical findings emphasize the controllable recommendation strategy's ability to produce item sequences according to different objectives while maintaining performance that is competitive with current recommendation strategies across various objectives.
LLM-Powered User Simulator for Recommender System
Dec 22, 2024



User simulators can rapidly generate a large volume of timely user behavior data, providing a testing platform for reinforcement learning-based recommender systems, thus accelerating their iteration and optimization. However, prevalent user simulators generally suffer from significant limitations, including the opacity of user preference modeling and the incapability of evaluating simulation accuracy. In this paper, we introduce an LLM-powered user simulator to simulate user engagement with items in an explicit manner, thereby enhancing the efficiency and effectiveness of reinforcement learning-based recommender systems training. Specifically, we identify the explicit logic of user preferences, leverage LLMs to analyze item characteristics and distill user sentiments, and design a logical model to imitate real human engagement. By integrating a statistical model, we further enhance the reliability of the simulation, proposing an ensemble model that synergizes logical and statistical insights for user interaction simulations. Capitalizing on the extensive knowledge and semantic generation capabilities of LLMs, our user simulator faithfully emulates user behaviors and preferences, yielding high-fidelity training data that enrich the training of recommendation algorithms. We establish quantifying and qualifying experiments on five datasets to validate the simulator's effectiveness and stability across various recommendation scenarios.