 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025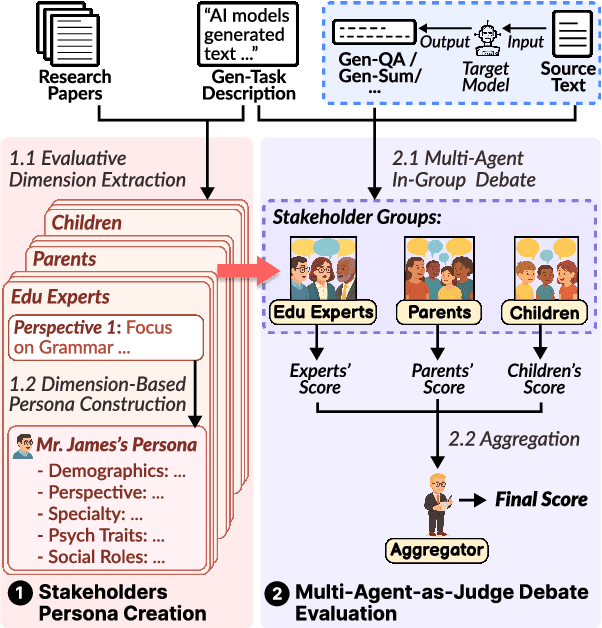



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
Dual-Modality Computational Ophthalmic Imaging with Deep Learning and Coaxial Optical Design
Apr 13, 2025The growing burden of myopia and retinal diseases necessitates more accessible and efficient eye screening solutions. This study presents a compact, dual-function optical device that integrates fundus photography and refractive error detection into a unified platform. The system features a coaxial optical design using dichroic mirrors to separate wavelength-dependent imaging paths, enabling simultaneous alignment of fundus and refraction modules. A Dense-U-Net-based algorithm with customized loss functions is employed for accurate pupil segmentation, facilitating automated alignment and focusing. Experimental evaluations demonstrate the system's capability to achieve high-precision pupil localization (EDE = 2.8 px, mIoU = 0.931) and reliable refractive estimation with a mean absolute error below 5%. Despite limitations due to commercial lens components, the proposed framework offers a promising solution for rapid, intelligent, and scalable ophthalmic screening, particularly suitable for community health settings.
Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer
Jan 13, 2025Securing long-term success is the ultimate aim of recommender systems, demanding strategies capable of foreseeing and shaping the impact of decisions on future user satisfaction. Current recommendation strategies grapple with two significant hurdles. Firstly, the future impacts of recommendation decisions remain obscured, rendering it impractical to evaluate them through direct optimization of immediate metrics. Secondly, conflicts often emerge between multiple objectives, like enhancing accuracy versus exploring diverse recommendations. Existing strategies, trapped in a "training, evaluation, and retraining" loop, grow more labor-intensive as objectives evolve. To address these challenges, we introduce a future-conditioned strategy for multi-objective controllable recommendations, allowing for the direct specification of future objectives and empowering the model to generate item sequences that align with these goals autoregressively. We present the Multi-Objective Controllable Decision Transformer (MocDT), an offline Reinforcement Learning (RL) model capable of autonomously learning the mapping from multiple objectives to item sequences, leveraging extensive offline data. Consequently, it can produce recommendations tailored to any specified objectives during the inference stage. Our empirical findings emphasize the controllable recommendation strategy's ability to produce item sequences according to different objectives while maintaining performance that is competitive with current recommendation strategies across various objectives.
DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems
Aug 22, 2024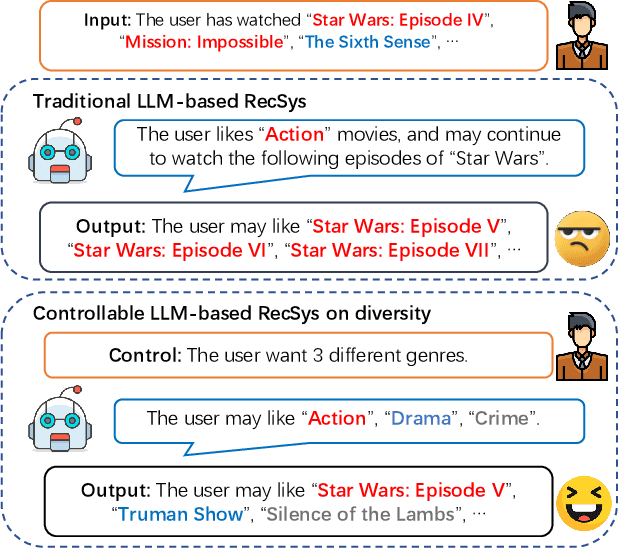



The integration of Large Language Models (LLMs) into recommender systems has led to substantial performance improvements. However, this often comes at the cost of diminished recommendation diversity, which can negatively impact user satisfaction. To address this issue, controllable recommendation has emerged as a promising approach, allowing users to specify their preferences and receive recommendations that meet their diverse needs. Despite its potential, existing controllable recommender systems frequently rely on simplistic mechanisms, such as a single prompt, to regulate diversity-an approach that falls short of capturing the full complexity of user preferences. In response to these limitations, we propose DLCRec, a novel framework designed to enable fine-grained control over diversity in LLM-based recommendations. Unlike traditional methods, DLCRec adopts a fine-grained task decomposition strategy, breaking down the recommendation process into three sequential sub-tasks: genre prediction, genre filling, and item prediction. These sub-tasks are trained independently and inferred sequentially according to user-defined control numbers, ensuring more precise control over diversity. Furthermore, the scarcity and uneven distribution of diversity-related user behavior data pose significant challenges for fine-tuning. To overcome these obstacles, we introduce two data augmentation techniques that enhance the model's robustness to noisy and out-of-distribution data. These techniques expose the model to a broader range of patterns, improving its adaptability in generating recommendations with varying levels of diversity. Our extensive empirical evaluation demonstrates that DLCRec not only provides precise control over diversity but also outperforms state-of-the-art baselines across multiple recommendation scenarios.
Treatment Effect Estimation for User Interest Exploration on Recommender Systems
May 14, 2024Recommender systems learn personalized user preferences from user feedback like clicks. However, user feedback is usually biased towards partially observed interests, leaving many users' hidden interests unexplored. Existing approaches typically mitigate the bias, increase recommendation diversity, or use bandit algorithms to balance exploration-exploitation trade-offs. Nevertheless, they fail to consider the potential rewards of recommending different categories of items and lack the global scheduling of allocating top-N recommendations to categories, leading to suboptimal exploration. In this work, we propose an Uplift model-based Recommender (UpliftRec) framework, which regards top-N recommendation as a treatment optimization problem. UpliftRec estimates the treatment effects, i.e., the click-through rate (CTR) under different category exposure ratios, by using observational user feedback. UpliftRec calculates group-level treatment effects to discover users' hidden interests with high CTR rewards and leverages inverse propensity weighting to alleviate confounder bias. Thereafter, UpliftRec adopts a dynamic programming method to calculate the optimal treatment for overall CTR maximization. We implement UpliftRec on different backend models and conduct extensive experiments on three datasets. The empirical results validate the effectiveness of UpliftRec in discovering users' hidden interests while achieving superior recommendation accuracy.
Benchmarking the Cell Image Segmentation Models Robustness under the Microscope Optical Aberrations
Apr 12, 2024Cell segmentation is essential in biomedical research for analyzing cellular morphology and behavior. Deep learning methods, particularly convolutional neural networks (CNNs), have revolutionized cell segmentation by extracting intricate features from images. However, the robustness of these methods under microscope optical aberrations remains a critical challenge. This study comprehensively evaluates the performance of cell instance segmentation models under simulated aberration conditions using the DynamicNuclearNet (DNN) and LIVECell datasets. Aberrations, including Astigmatism, Coma, Spherical, and Trefoil, were simulated using Zernike polynomial equations. Various segmentation models, such as Mask R-CNN with different network heads (FPN, C3) and backbones (ResNet, VGG19, SwinS), were trained and tested under aberrated conditions. Results indicate that FPN combined with SwinS demonstrates superior robustness in handling simple cell images affected by minor aberrations. Conversely, Cellpose2.0 proves effective for complex cell images under similar conditions. Our findings provide insights into selecting appropriate segmentation models based on cell morphology and aberration severity, enhancing the reliability of cell segmentation in biomedical applications. Further research is warranted to validate these methods with diverse aberration types and emerging segmentation models. Overall, this research aims to guide researchers in effectively utilizing cell segmentation models in the presence of minor optical aberrations.
FairytaleCQA: Integrating a Commonsense Knowledge Graph into Children's Storybook Narratives
Nov 16, 2023
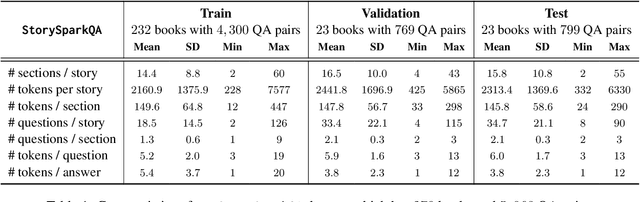
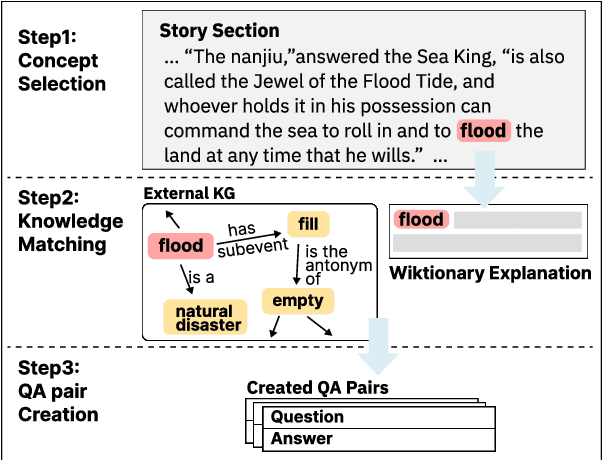
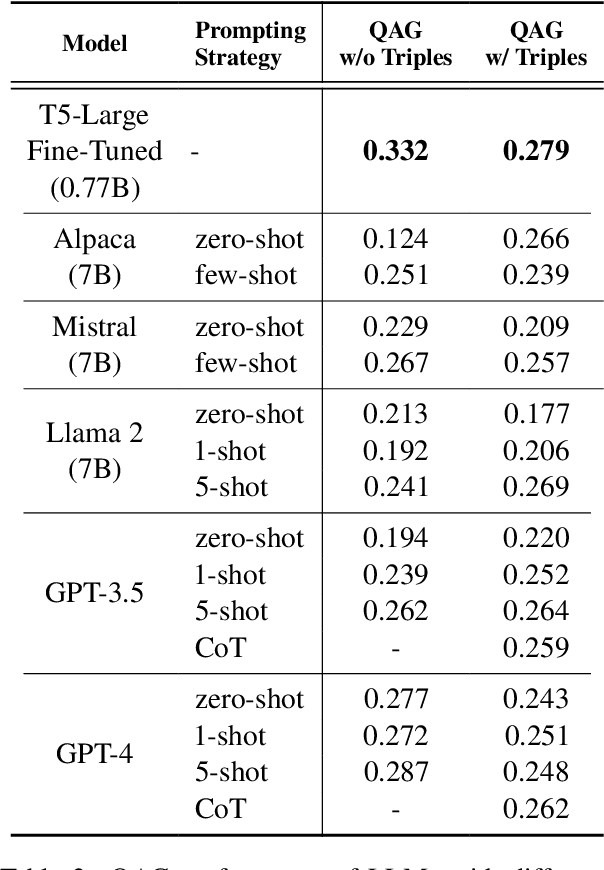
AI models (including LLM) often rely on narrative question-answering (QA) datasets to provide customized QA functionalities to support downstream children education applications; however, existing datasets only include QA pairs that are grounded within the given storybook content, but children can learn more when teachers refer the storybook content to real-world knowledge (e.g., commonsense knowledge). We introduce the FairytaleCQA dataset, which is annotated by children education experts, to supplement 278 storybook narratives with educationally appropriate commonsense knowledge. The dataset has 5,868 QA pairs that not only originate from the storybook narrative but also contain the commonsense knowledge grounded by an external knowledge graph (i.e., ConceptNet). A follow-up experiment shows that a smaller model (T5-large) fine-tuned with FairytaleCQA reliably outperforms much larger prompt-engineered LLM (e.g., GPT-4) in this new QA-pair generation task (QAG). This result suggests that: 1) our dataset brings novel challenges to existing LLMs, and 2) human experts' data annotation are still critical as they have much nuanced knowledge that LLMs do not know in the children educational domain.