 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment Effect Estimation for User Interest Exploration on Recommender Systems
May 14, 2024Recommender systems learn personalized user preferences from user feedback like clicks. However, user feedback is usually biased towards partially observed interests, leaving many users' hidden interests unexplored. Existing approaches typically mitigate the bias, increase recommendation diversity, or use bandit algorithms to balance exploration-exploitation trade-offs. Nevertheless, they fail to consider the potential rewards of recommending different categories of items and lack the global scheduling of allocating top-N recommendations to categories, leading to suboptimal exploration. In this work, we propose an Uplift model-based Recommender (UpliftRec) framework, which regards top-N recommendation as a treatment optimization problem. UpliftRec estimates the treatment effects, i.e., the click-through rate (CTR) under different category exposure ratios, by using observational user feedback. UpliftRec calculates group-level treatment effects to discover users' hidden interests with high CTR rewards and leverages inverse propensity weighting to alleviate confounder bias. Thereafter, UpliftRec adopts a dynamic programming method to calculate the optimal treatment for overall CTR maximization. We implement UpliftRec on different backend models and conduct extensive experiments on three datasets. The empirical results validate the effectiveness of UpliftRec in discovering users' hidden interests while achieving superior recommendation accuracy.
Multiple Interest and Fine Granularity Network for User Modeling
Dec 05, 2021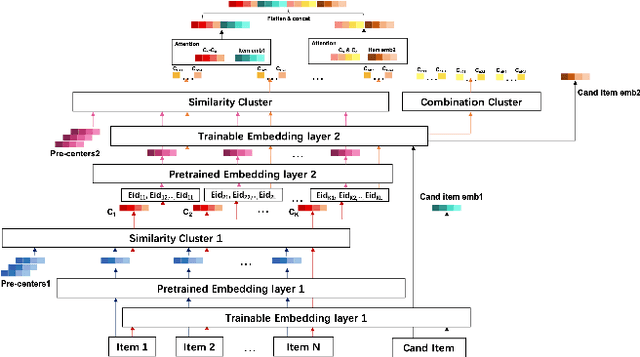
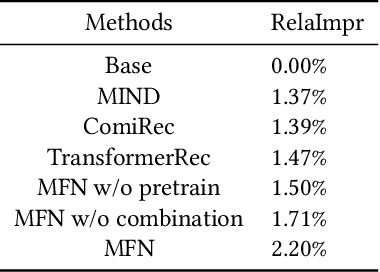
User modeling plays a fundamental role in industrial recommender systems, either in the matching stage and the ranking stage, in terms of both the customer experience and business revenue. How to extract users' multiple interests effectively from their historical behavior sequences to improve the relevance and personalization of the recommend results remains an open problem for user modeling.Most existing deep-learning based approaches exploit item-ids and category-ids but neglect fine-grained features like color and mate-rial, which hinders modeling the fine granularity of users' interests.In the paper, we present Multiple interest and Fine granularity Net-work (MFN), which tackle users' multiple and fine-grained interests and construct the model from both the similarity relationship and the combination relationship among the users' multiple interests.Specifically, for modeling the similarity relationship, we leverage two sets of embeddings, where one is the fixed embedding from pre-trained models (e.g. Glove) to give the attention weights and the other is trainable embedding to be trained with MFN together.For modeling the combination relationship, self-attentive layers are exploited to build the higher order combinations of different interest representations. In the construction of network, we design an interest-extract module using attention mechanism to capture multiple interest representations from user historical behavior sequences and leverage an auxiliary loss to boost the distinction of the interest representations. Then a hierarchical network is applied to model the attention relation between the multiple interest vectors of different granularities and the target item. We evaluate MFNon both public and industrial datasets. The experimental results demonstrate that the proposed MFN achieves superior performance than other existed representing methods.
Generator and Critic: A Deep Reinforcement Learning Approach for Slate Re-ranking in E-commerce
May 25, 2020

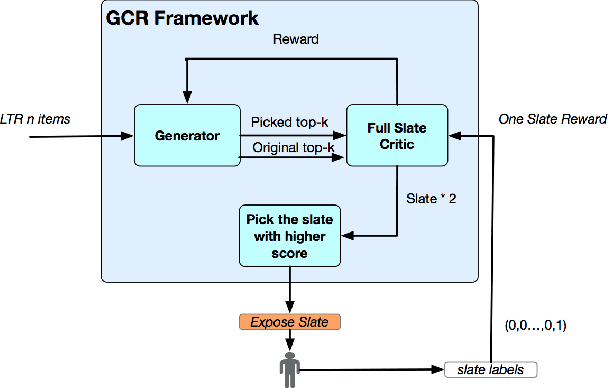

The slate re-ranking problem considers the mutual influences between items to improve user satisfaction in e-commerce, compared with the point-wise ranking. Previous works either directly rank items by an end to end model, or rank items by a score function that trades-off the point-wise score and the diversity between items. However, there are two main existing challenges that are not well studied: (1) the evaluation of the slate is hard due to the complex mutual influences between items of one slate; (2) even given the optimal evaluation, searching the optimal slate is challenging as the action space is exponentially large. In this paper, we present a novel Generator and Critic slate re-ranking approach, where the Critic evaluates the slate and the Generator ranks the items by the reinforcement learning approach. We propose a Full Slate Critic (FSC) model that considers the real impressed items and avoids the impressed bias of existing models. For the Generator, to tackle the problem of large action space, we propose a new exploration reinforcement learning algorithm, called PPO-Exploration. Experimental results show that the FSC model significantly outperforms the state of the art slate evaluation methods, and the PPO-Exploration algorithm outperforms the existing reinforcement learning methods substantially. The Generator and Critic approach improves both the slate efficiency(4% gmv and 5% number of orders) and diversity in live experiments on one of the largest e-commerce websites in the world.