 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Dynamic Graph Neural Networks via Relevance Back-propagation
Jul 22, 2022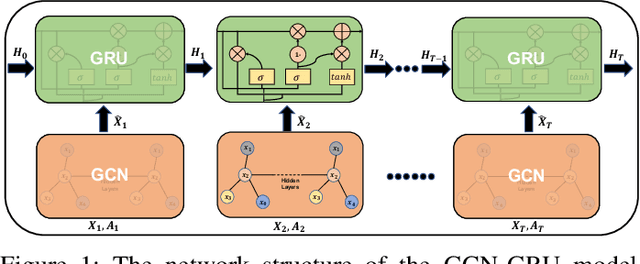
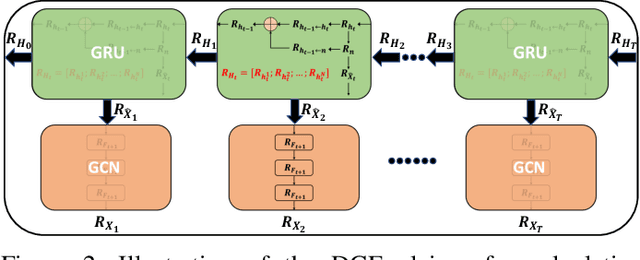
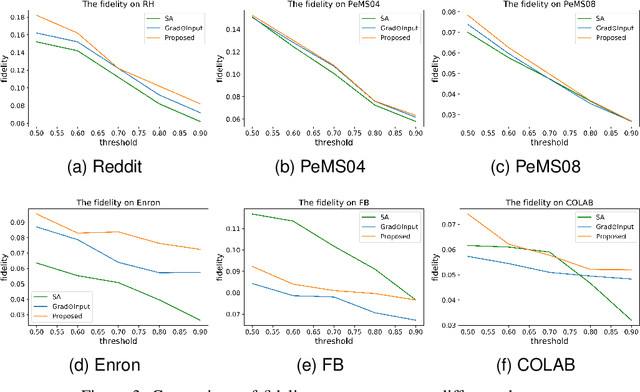
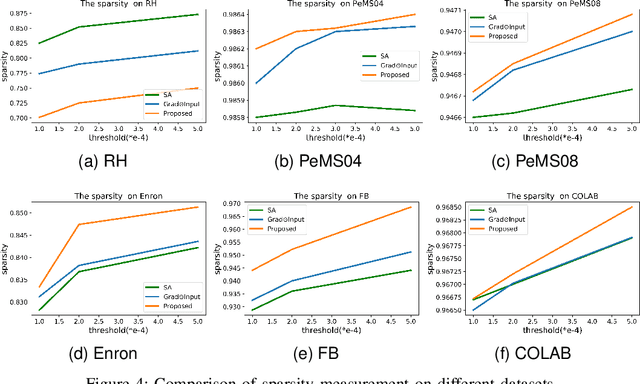
Graph Neural Networks (GNNs) have shown remarkable effectiveness in capturing abundant information in graph-structured data. However, the black-box nature of GNNs hinders users from understanding and trusting the models, thus leading to difficulties in their applications. While recent years witness the prosperity of the studies on explaining GNNs, most of them focus on static graphs, leaving the explanation of dynamic GNNs nearly unexplored. It is challenging to explain dynamic GNNs, due to their unique characteristic of time-varying graph structures. Directly using existing models designed for static graphs on dynamic graphs is not feasible because they ignore temporal dependencies among the snapshots. In this work, we propose DGExplainer to provide reliable explanation on dynamic GNNs. DGExplainer redistributes the output activation score of a dynamic GNN to the relevances of the neurons of its previous layer, which iterates until the relevance scores of the input neuron are obtained. We conduct quantitative and qualitative experiments on real-world datasets to demonstrate the effectiveness of the proposed framework for identifying important nodes for link prediction and node regression for dynamic GNNs.
Multiple Interest and Fine Granularity Network for User Modeling
Dec 05, 2021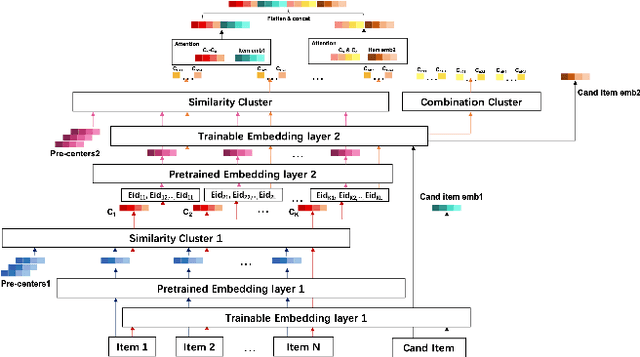
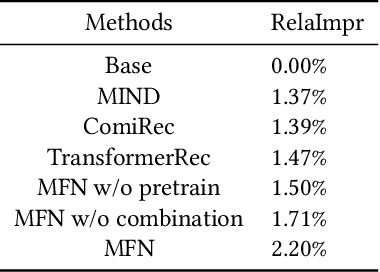
User modeling plays a fundamental role in industrial recommender systems, either in the matching stage and the ranking stage, in terms of both the customer experience and business revenue. How to extract users' multiple interests effectively from their historical behavior sequences to improve the relevance and personalization of the recommend results remains an open problem for user modeling.Most existing deep-learning based approaches exploit item-ids and category-ids but neglect fine-grained features like color and mate-rial, which hinders modeling the fine granularity of users' interests.In the paper, we present Multiple interest and Fine granularity Net-work (MFN), which tackle users' multiple and fine-grained interests and construct the model from both the similarity relationship and the combination relationship among the users' multiple interests.Specifically, for modeling the similarity relationship, we leverage two sets of embeddings, where one is the fixed embedding from pre-trained models (e.g. Glove) to give the attention weights and the other is trainable embedding to be trained with MFN together.For modeling the combination relationship, self-attentive layers are exploited to build the higher order combinations of different interest representations. In the construction of network, we design an interest-extract module using attention mechanism to capture multiple interest representations from user historical behavior sequences and leverage an auxiliary loss to boost the distinction of the interest representations. Then a hierarchical network is applied to model the attention relation between the multiple interest vectors of different granularities and the target item. We evaluate MFNon both public and industrial datasets. The experimental results demonstrate that the proposed MFN achieves superior performance than other existed representing methods.
Deep Kernel Learning via Random Fourier Features
Oct 07, 2019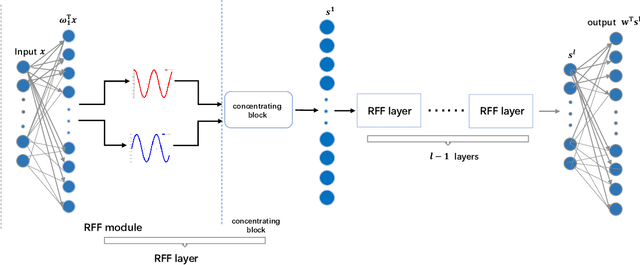
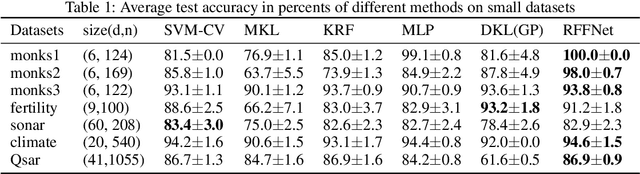
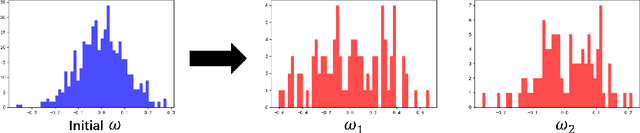
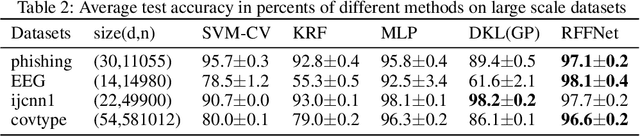
Kernel learning methods are among the most effective learning methods and have been vigorously studied in the past decades. However, when tackling with complicated tasks, classical kernel methods are not flexible or "rich" enough to describe the data and hence could not yield satisfactory performance. In this paper, via Random Fourier Features (RFF), we successfully incorporate the deep architecture into kernel learning, which significantly boosts the flexibility and richness of kernel machines while keeps kernels' advantage of pairwise handling small data. With RFF, we could establish a deep structure and make every kernel in RFF layers could be trained end-to-end. Since RFF with different distributions could represent different kernels, our model has the capability of finding suitable kernels for each layer, which is much more flexible than traditional kernel-based methods where the kernel is pre-selected. This fact also helps yield a more sophisticated kernel cascade connection in the architecture. On small datasets (less than 1000 samples), for which deep learning is generally not suitable due to overfitting, our method achieves superior performance compared to advanced kernel methods. On large-scale datasets, including non-image and image classification tasks, our method also has competitive performance.