 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer
Jan 13, 2025Securing long-term success is the ultimate aim of recommender systems, demanding strategies capable of foreseeing and shaping the impact of decisions on future user satisfaction. Current recommendation strategies grapple with two significant hurdles. Firstly, the future impacts of recommendation decisions remain obscured, rendering it impractical to evaluate them through direct optimization of immediate metrics. Secondly, conflicts often emerge between multiple objectives, like enhancing accuracy versus exploring diverse recommendations. Existing strategies, trapped in a "training, evaluation, and retraining" loop, grow more labor-intensive as objectives evolve. To address these challenges, we introduce a future-conditioned strategy for multi-objective controllable recommendations, allowing for the direct specification of future objectives and empowering the model to generate item sequences that align with these goals autoregressively. We present the Multi-Objective Controllable Decision Transformer (MocDT), an offline Reinforcement Learning (RL) model capable of autonomously learning the mapping from multiple objectives to item sequences, leveraging extensive offline data. Consequently, it can produce recommendations tailored to any specified objectives during the inference stage. Our empirical findings emphasize the controllable recommendation strategy's ability to produce item sequences according to different objectives while maintaining performance that is competitive with current recommendation strategies across various objectives.
Generative Adversarial Active Learning for Unsupervised Outlier Detection
Sep 28, 2018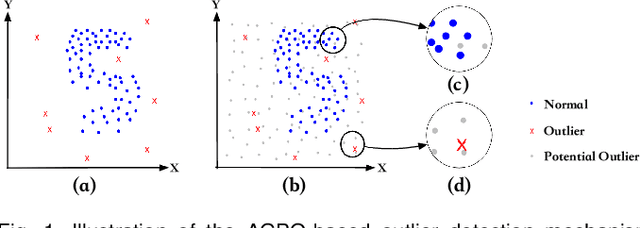

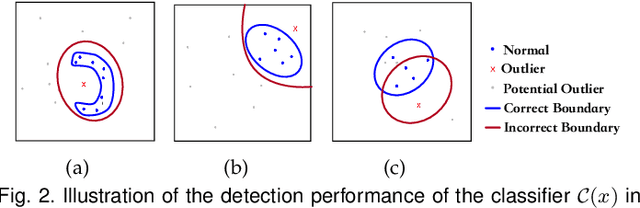
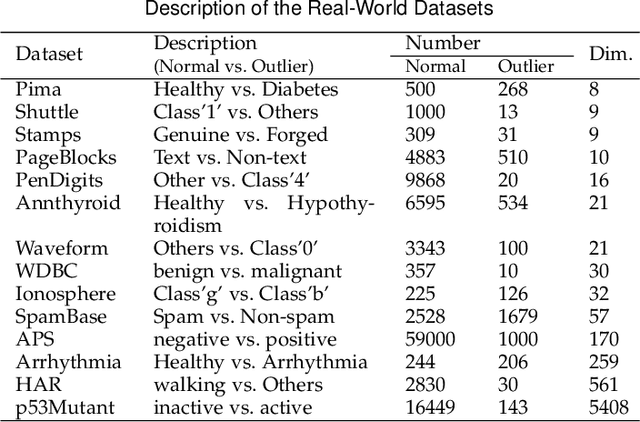
Outlier detection is an important topic in machine learning and has been used in a wide range of applications. In this paper, we approach outlier detection as a binary-classification issue by sampling potential outliers from a uniform reference distribution. However, due to the sparsity of data in high-dimensional space, a limited number of potential outliers may fail to provide sufficient information to assist the classifier in describing a boundary that can separate outliers from normal data effectively. To address this, we propose a novel Single-Objective Generative Adversarial Active Learning (SO-GAAL) method for outlier detection, which can directly generate informative potential outliers based on the mini-max game between a generator and a discriminator. Moreover, to prevent the generator from falling into the mode collapsing problem, the stop node of training should be determined when SO-GAAL is able to provide sufficient information. But without any prior information, it is extremely difficult for SO-GAAL. Therefore, we expand the network structure of SO-GAAL from a single generator to multiple generators with different objectives (MO-GAAL), which can generate a reasonable reference distribution for the whole dataset. We empirically compare the proposed approach with several state-of-the-art outlier detection methods on both synthetic and real-world datasets. The results show that MO-GAAL outperforms its competitors in the majority of cases, especially for datasets with various cluster types or high irrelevant variable ratio.