 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Fake News on Social Media: A Novel Reliability Aware Machine-Crowd Hybrid Intelligence-Based Method
Dec 07, 2024



Fake news on social media platforms poses a significant threat to societal systems, underscoring the urgent need for advanced detection methods. The existing detection methods can be divided into machine intelligence-based, crowd intelligence-based, and hybrid intelligence-based methods. Among them, hybrid intelligence-based methods achieve the best performance but fail to consider the reliability issue in detection. In light of this, we propose a novel Reliability Aware Hybrid Intelligence (RAHI) method for fake news detection. Our method comprises three integral modules. The first module employs a Bayesian deep learning model to capture the inherent reliability within machine intelligence. The second module uses an Item Response Theory (IRT)-based user response aggregation to account for the reliability in crowd intelligence. The third module introduces a new distribution fusion mechanism, which takes the distributions derived from both machine and crowd intelligence as input, and outputs a fused distribution that provides predictions along with the associated reliability. The experiments on the Weibo dataset demonstrate the advantages of our method. This study contributes to the research field with a novel RAHI-based method, and the code is shared at https://github.com/Kangwei-g/RAHI. This study has practical implications for three key stakeholders: internet users, online platform managers, and the government.
Towards Trustworthy Web Attack Detection: An Uncertainty-Aware Ensemble Deep Kernel Learning Model
Oct 10, 2024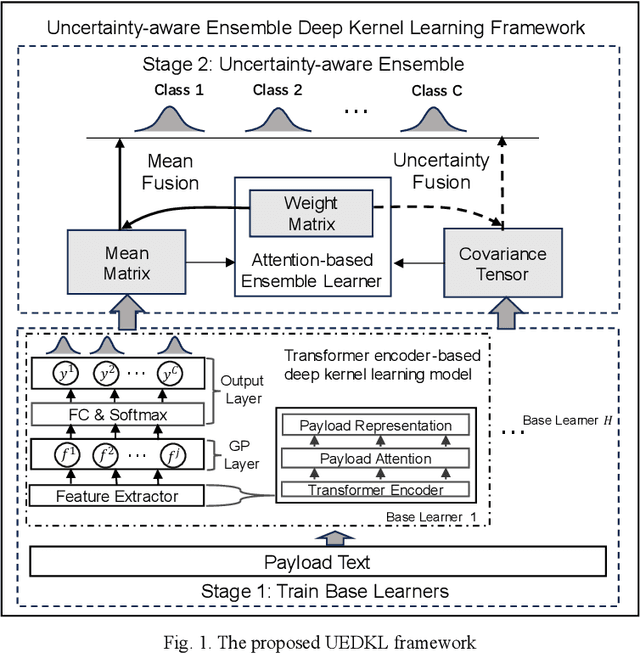
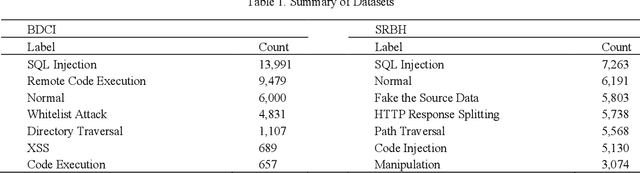
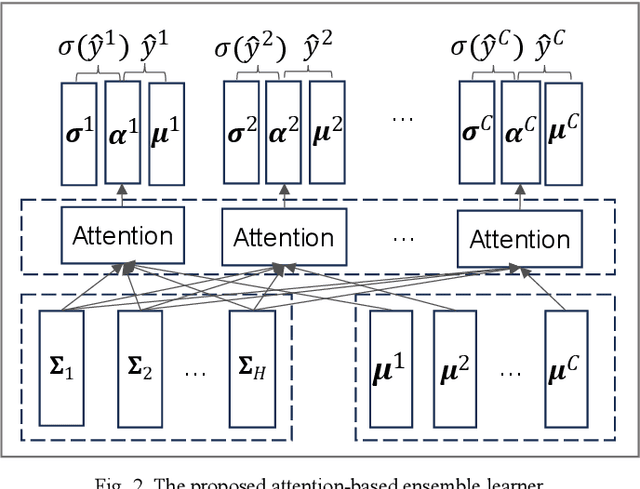
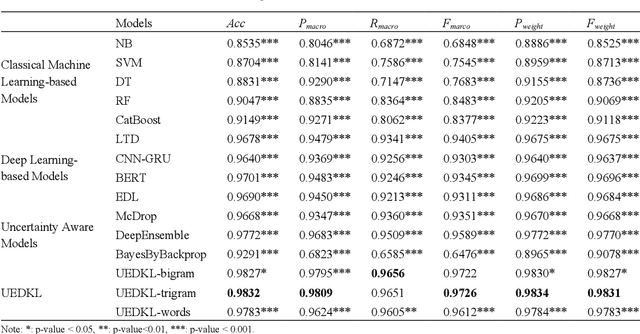
Web attacks are one of the major and most persistent forms of cyber threats, which bring huge costs and losses to web application-based businesses. Various detection methods, such as signature-based, machine learning-based, and deep learning-based, have been proposed to identify web attacks. However, these methods either (1) heavily rely on accurate and complete rule design and feature engineering, which may not adapt to fast-evolving attacks, or (2) fail to estimate model uncertainty, which is essential to the trustworthiness of the prediction made by the model. In this study, we proposed an Uncertainty-aware Ensemble Deep Kernel Learning (UEDKL) model to detect web attacks from HTTP request payload data with the model uncertainty captured from the perspective of both data distribution and model parameters. The proposed UEDKL utilizes a deep kernel learning model to distinguish normal HTTP requests from different types of web attacks with model uncertainty estimated from data distribution perspective. Multiple deep kernel learning models were trained as base learners to capture the model uncertainty from model parameters perspective. An attention-based ensemble learning approach was designed to effectively integrate base learners' predictions and model uncertainty. We also proposed a new metric named High Uncertainty Ratio-F Score Curve to evaluate model uncertainty estimation. Experiments on BDCI and SRBH datasets demonstrated that the proposed UEDKL framework yields significant improvement in both web attack detection performance and uncertainty estimation quality compared to benchmark models.
A Whole-Process Certifiably Robust Aggregation Method Against Backdoor Attacks in Federated Learning
Jun 30, 2024



Federated Learning (FL) has garnered widespread adoption across various domains such as finance, healthcare, and cybersecurity. Nonetheless, FL remains under significant threat from backdoor attacks, wherein malicious actors insert triggers into trained models, enabling them to perform certain tasks while still meeting FL's primary objectives. In response, robust aggregation methods have been proposed, which can be divided into three types: ex-ante, ex-durante, and ex-post methods. Given the complementary nature of these methods, combining all three types is promising yet unexplored. Such a combination is non-trivial because it requires leveraging their advantages while overcoming their disadvantages. Our study proposes a novel whole-process certifiably robust aggregation (WPCRA) method for FL, which enhances robustness against backdoor attacks across three phases: ex-ante, ex-durante, and ex-post. Moreover, since the current geometric median estimation method fails to consider differences among clients, we propose a novel weighted geometric median estimation algorithm (WGME). This algorithm estimates the geometric median of model updates from clients based on each client's weight, further improving the robustness of WPCRA against backdoor attacks. We also theoretically prove that WPCRA offers improved certified robustness guarantees with a larger certified radius. We evaluate the advantages of our methods based on the task of loan status prediction. Comparison with baselines shows that our methods significantly improve FL's robustness against backdoor attacks. This study contributes to the literature with a novel WPCRA method and a novel WGME algorithm. Our code is available at https://github.com/brick-brick/WPCRAM.
Personalized Music Recommendation with a Heterogeneity-aware Deep Bayesian Network
Jun 20, 2024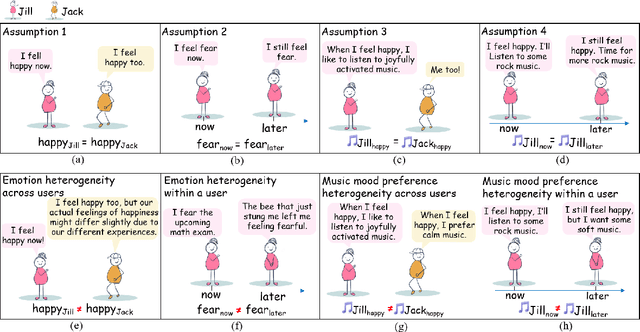
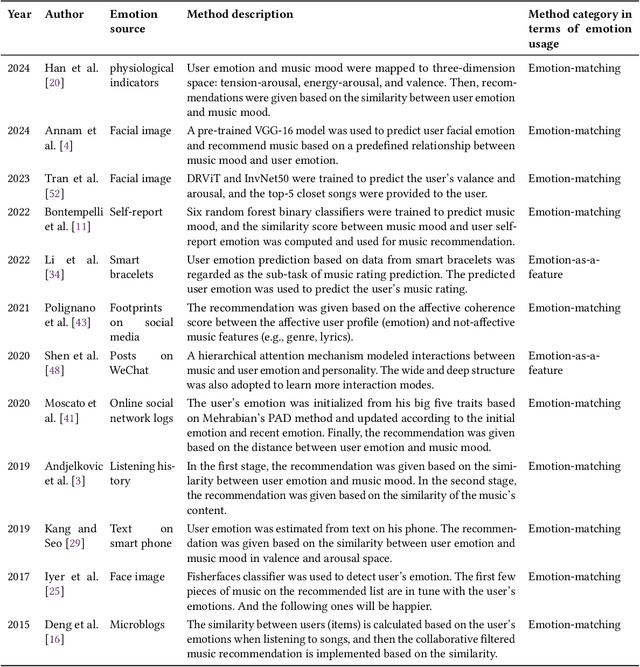
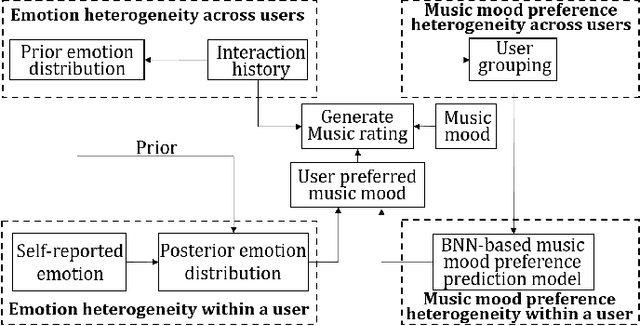
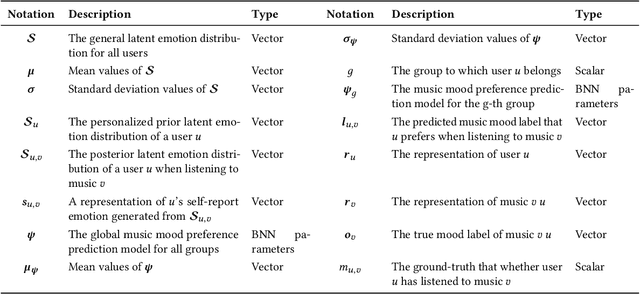
Music recommender systems are crucial in music streaming platforms, providing users with music they would enjoy. Recent studies have shown that user emotions can affect users' music mood preferences. However, existing emotion-aware music recommender systems (EMRSs) explicitly or implicitly assume that users' actual emotional states expressed by an identical emotion word are homogeneous. They also assume that users' music mood preferences are homogeneous under an identical emotional state. In this article, we propose four types of heterogeneity that an EMRS should consider: emotion heterogeneity across users, emotion heterogeneity within a user, music mood preference heterogeneity across users, and music mood preference heterogeneity within a user. We further propose a Heterogeneity-aware Deep Bayesian Network (HDBN) to model these assumptions. The HDBN mimics a user's decision process to choose music with four components: personalized prior user emotion distribution modeling, posterior user emotion distribution modeling, user grouping, and Bayesian neural network-based music mood preference prediction. We constructed a large-scale dataset called EmoMusicLJ to validate our method. Extensive experiments demonstrate that our method significantly outperforms baseline approaches on widely used HR and NDCG recommendation metrics. Ablation experiments and case studies further validate the effectiveness of our HDBN. The source code is available at https://github.com/jingrk/HDBN.
TopicModel4J: A Java Package for Topic Models
Oct 28, 2020

Topic models provide a flexible and principled framework for exploring hidden structure in high-dimensional co-occurrence data and are commonly used natural language processing (NLP) of text. In this paper, we design and implement a Java package, TopicModel4J, which contains 13 kinds of representative algorithms for fitting topic models. The TopicModel4J in the Java programming environment provides an easy-to-use interface for data analysts to run the algorithms, and allow to easily input and output data. In addition, this package provides a few unstructured text preprocessing techniques, such as splitting textual data into words, lowercasing the words, preforming lemmatization and removing the useless characters, URLs and stop words.
Generative Adversarial Active Learning for Unsupervised Outlier Detection
Sep 28, 2018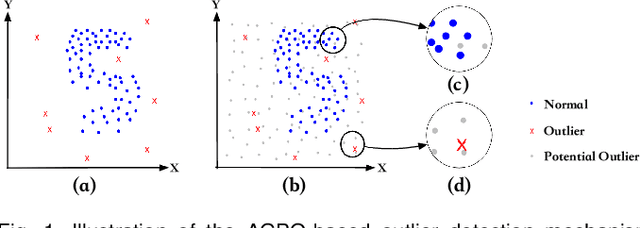

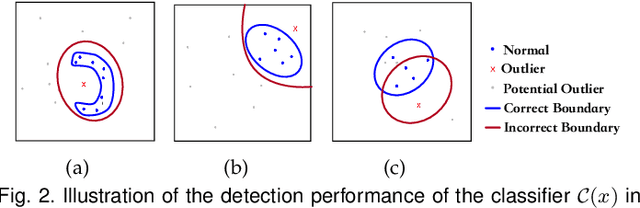
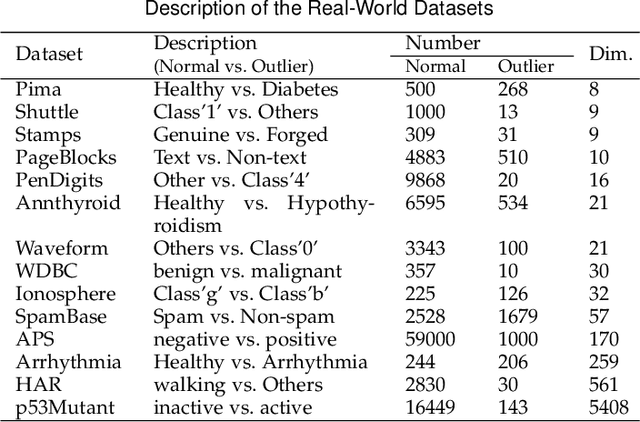
Outlier detection is an important topic in machine learning and has been used in a wide range of applications. In this paper, we approach outlier detection as a binary-classification issue by sampling potential outliers from a uniform reference distribution. However, due to the sparsity of data in high-dimensional space, a limited number of potential outliers may fail to provide sufficient information to assist the classifier in describing a boundary that can separate outliers from normal data effectively. To address this, we propose a novel Single-Objective Generative Adversarial Active Learning (SO-GAAL) method for outlier detection, which can directly generate informative potential outliers based on the mini-max game between a generator and a discriminator. Moreover, to prevent the generator from falling into the mode collapsing problem, the stop node of training should be determined when SO-GAAL is able to provide sufficient information. But without any prior information, it is extremely difficult for SO-GAAL. Therefore, we expand the network structure of SO-GAAL from a single generator to multiple generators with different objectives (MO-GAAL), which can generate a reasonable reference distribution for the whole dataset. We empirically compare the proposed approach with several state-of-the-art outlier detection methods on both synthetic and real-world datasets. The results show that MO-GAAL outperforms its competitors in the majority of cases, especially for datasets with various cluster types or high irrelevant variable ratio.