 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemCast: Memory-Driven Time Series Forecasting with Experience-Conditioned Reasoning
Feb 03, 2026Time series forecasting (TSF) plays a critical role in decision-making for many real-world applications. Recently, LLM-based forecasters have made promising advancements. Despite their effectiveness, existing methods often lack explicit experience accumulation and continual evolution. In this work, we propose MemCast, a learning-to-memory framework that reformulates TSF as an experience-conditioned reasoning task. Specifically, we learn experience from the training set and organize it into a hierarchical memory. This is achieved by summarizing prediction results into historical patterns, distilling inference trajectories into reasoning wisdom, and inducing extracted temporal features into general laws. Furthermore, during inference, we leverage historical patterns to guide the reasoning process and utilize reasoning wisdom to select better trajectories, while general laws serve as criteria for reflective iteration. Additionally, to enable continual evolution, we design a dynamic confidence adaptation strategy that updates the confidence of individual entries without leaking the test set distribution. Extensive experiments on multiple datasets demonstrate that MemCast consistently outperforms previous methods, validating the effectiveness of our approach. Our code is available at https://github.com/Xiaoyu-Tao/MemCast-TS.
Explaining Synergistic Effects in Social Recommendations
Jan 26, 2026In social recommenders, the inherent nonlinearity and opacity of synergistic effects across multiple social networks hinders users from understanding how diverse information is leveraged for recommendations, consequently diminishing explainability. However, existing explainers can only identify the topological information in social networks that significantly influences recommendations, failing to further explain the synergistic effects among this information. Inspired by existing findings that synergistic effects enhance mutual information between inputs and predictions to generate information gain, we extend this discovery to graph data. We quantify graph information gain to identify subgraphs embodying synergistic effects. Based on the theoretical insights, we propose SemExplainer, which explains synergistic effects by identifying subgraphs that embody them. SemExplainer first extracts explanatory subgraphs from multi-view social networks to generate preliminary importance explanations for recommendations. A conditional entropy optimization strategy to maximize information gain is developed, thereby further identifying subgraphs that embody synergistic effects from explanatory subgraphs. Finally, SemExplainer searches for paths from users to recommended items within the synergistic subgraphs to generate explanations for the recommendations. Extensive experiments on three datasets demonstrate the superiority of SemExplainer over baseline methods, providing superior explanations of synergistic effects.
Bridging Semantic Understanding and Popularity Bias with LLMs
Jan 15, 2026Semantic understanding of popularity bias is a crucial yet underexplored challenge in recommender systems, where popular items are often favored at the expense of niche content. Most existing debiasing methods treat the semantic understanding of popularity bias as a matter of diversity enhancement or long-tail coverage, neglecting the deeper semantic layer that embodies the causal origins of the bias itself. Consequently, such shallow interpretations limit both their debiasing effectiveness and recommendation accuracy. In this paper, we propose FairLRM, a novel framework that bridges the gap in the semantic understanding of popularity bias with Recommendation via Large Language Model (RecLLM). FairLRM decomposes popularity bias into item-side and user-side components, using structured instruction-based prompts to enhance the model's comprehension of both global item distributions and individual user preferences. Unlike traditional methods that rely on surface-level features such as "diversity" or "debiasing", FairLRM improves the model's ability to semantically interpret and address the underlying bias. Through empirical evaluation, we show that FairLRM significantly enhances both fairness and recommendation accuracy, providing a more semantically aware and trustworthy approach to enhance the semantic understanding of popularity bias. The implementation is available at https://github.com/LuoRenqiang/FairLRM.
PaperScout: An Autonomous Agent for Academic Paper Search with Process-Aware Sequence-Level Policy Optimization
Jan 15, 2026Academic paper search is a fundamental task in scientific research, yet most existing approaches rely on rigid, predefined workflows that struggle with complex, conditional queries. To address this limitation, we propose PaperScout, an autonomous agent that reformulates paper search as a sequential decision-making process. Unlike static workflows, PaperScout dynamically decides whether, when, and how to invoke search and expand tools based on accumulated retrieval context. However, training such agents presents a fundamental challenge: standard reinforcement learning methods, typically designed for single-turn tasks, suffer from a granularity mismatch when applied to multi-turn agentic tasks, where token-level optimization diverges from the granularity of sequence-level interactions, leading to noisy credit assignment. We introduce Proximal Sequence Policy Optimization (PSPO), a process-aware, sequence-level policy optimization method that aligns optimization with agent-environment interaction. Comprehensive experiments on both synthetic and real-world benchmarks demonstrate that PaperScout significantly outperforms strong workflow-driven and RL baselines in both recall and relevance, validating the effectiveness of our adaptive agentic framework and optimization strategy.
When to Invoke: Refining LLM Fairness with Toxicity Assessment
Jan 14, 2026Large Language Models (LLMs) are increasingly used for toxicity assessment in online moderation systems, where fairness across demographic groups is essential for equitable treatment. However, LLMs often produce inconsistent toxicity judgements for subtle expressions, particularly those involving implicit hate speech, revealing underlying biases that are difficult to correct through standard training. This raises a key question that existing approaches often overlook: when should corrective mechanisms be invoked to ensure fair and reliable assessments? To address this, we propose FairToT, an inference-time framework that enhances LLM fairness through prompt-guided toxicity assessment. FairToT identifies cases where demographic-related variation is likely to occur and determines when additional assessment should be applied. In addition, we introduce two interpretable fairness indicators that detect such cases and improve inference consistency without modifying model parameters. Experiments on benchmark datasets show that FairToT reduces group-level disparities while maintaining stable and reliable toxicity predictions, demonstrating that inference-time refinement offers an effective and practical approach for fairness improvement in LLM-based toxicity assessment systems. The source code can be found at https://aisuko.github.io/fair-tot/.
Mind2Report: A Cognitive Deep Research Agent for Expert-Level Commercial Report Synthesis
Jan 08, 2026Synthesizing informative commercial reports from massive and noisy web sources is critical for high-stakes business decisions. Although current deep research agents achieve notable progress, their reports still remain limited in terms of quality, reliability, and coverage. In this work, we propose Mind2Report, a cognitive deep research agent that emulates the commercial analyst to synthesize expert-level reports. Specifically, it first probes fine-grained intent, then searches web sources and records distilled information on the fly, and subsequently iteratively synthesizes the report. We design Mind2Report as a training-free agentic workflow that augments general large language models (LLMs) with dynamic memory to support these long-form cognitive processes. To rigorously evaluate Mind2Report, we further construct QRC-Eval comprising 200 real-world commercial tasks and establish a holistic evaluation strategy to assess report quality, reliability, and coverage. Experiments demonstrate that Mind2Report outperforms leading baselines, including OpenAI and Gemini deep research agents. Although this is a preliminary study, we expect it to serve as a foundation for advancing the future design of commercial deep research agents. Our code and data are available at https://github.com/Melmaphother/Mind2Report.
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.
MemWeaver: A Hierarchical Memory from Textual Interactive Behaviors for Personalized Generation
Oct 09, 2025
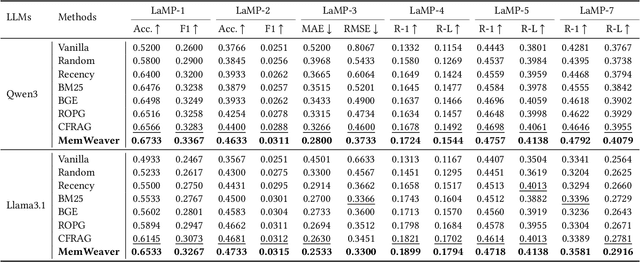
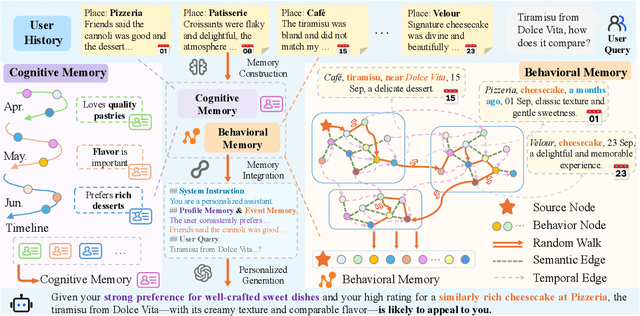
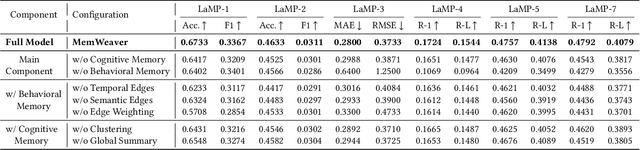
The primary form of user-internet engagement is shifting from leveraging implicit feedback signals, such as browsing and clicks, to harnessing the rich explicit feedback provided by textual interactive behaviors. This shift unlocks a rich source of user textual history, presenting a profound opportunity for a deeper form of personalization. However, prevailing approaches offer only a shallow form of personalization, as they treat user history as a flat list of texts for retrieval and fail to model the rich temporal and semantic structures reflecting dynamic nature of user interests. In this work, we propose \textbf{MemWeaver}, a framework that weaves the user's entire textual history into a hierarchical memory to power deeply personalized generation. The core innovation of our memory lies in its ability to capture both the temporal evolution of interests and the semantic relationships between different activities. To achieve this, MemWeaver builds two complementary memory components that both integrate temporal and semantic information, but at different levels of abstraction: behavioral memory, which captures specific user actions, and cognitive memory, which represents long-term preferences. This dual-component memory serves as a unified representation of the user, allowing large language models (LLMs) to reason over both concrete behaviors and abstracted traits. Experiments on the Language Model Personalization (LaMP) benchmark validate the efficacy of MemWeaver. Our code is available\footnote{https://github.com/fishsure/MemWeaver}.
HALO: Half Life-Based Outdated Fact Filtering in Temporal Knowledge Graphs
May 12, 2025Outdated facts in temporal knowledge graphs (TKGs) result from exceeding the expiration date of facts, which negatively impact reasoning performance on TKGs. However, existing reasoning methods primarily focus on positive importance of historical facts, neglecting adverse effects of outdated facts. Besides, training on these outdated facts yields extra computational cost. To address these challenges, we propose an outdated fact filtering framework named HALO, which quantifies the temporal validity of historical facts by exploring the half-life theory to filter outdated facts in TKGs. HALO consists of three modules: the temporal fact attention module, the dynamic relation-aware encoder module, and the outdated fact filtering module. Firstly, the temporal fact attention module captures the evolution of historical facts over time to identify relevant facts. Secondly, the dynamic relation-aware encoder module is designed for efficiently predicting the half life of each fact. Finally, we construct a time decay function based on the half-life theory to quantify the temporal validity of facts and filter outdated facts. Experimental results show that HALO outperforms the state-of-the-art TKG reasoning methods on three public datasets, demonstrating its effectiveness in detecting and filtering outdated facts (Codes are available at https://github.com/yushuowiki/K-Half/tree/main ).
Factor Graph-based Interpretable Neural Networks
Feb 20, 2025Comprehensible neural network explanations are foundations for a better understanding of decisions, especially when the input data are infused with malicious perturbations. Existing solutions generally mitigate the impact of perturbations through adversarial training, yet they fail to generate comprehensible explanations under unknown perturbations. To address this challenge, we propose AGAIN, a fActor GrAph-based Interpretable neural Network, which is capable of generating comprehensible explanations under unknown perturbations. Instead of retraining like previous solutions, the proposed AGAIN directly integrates logical rules by which logical errors in explanations are identified and rectified during inference. Specifically, we construct the factor graph to express logical rules between explanations and categories. By treating logical rules as exogenous knowledge, AGAIN can identify incomprehensible explanations that violate real-world logic. Furthermore, we propose an interactive intervention switch strategy rectifying explanations based on the logical guidance from the factor graph without learning perturbations, which overcomes the inherent limitation of adversarial training-based methods in defending only against known perturbations. Additionally, we theoretically demonstrate the effectiveness of employing factor graph by proving that the comprehensibility of explanations is strongly correlated with factor graph. Extensive experiments are conducted on three datasets and experimental results illustrate the superior performance of AGAIN compared to state-of-the-art baselines.