 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTARo: Once Tuning for All Precisions toward Robust On-Device LLMs
Nov 17, 2025Large Language Models (LLMs) fine-tuning techniques not only improve the adaptability to diverse downstream tasks, but also mitigate adverse effects of model quantization. Despite this, conventional quantization suffers from its structural limitation that hinders flexibility during the fine-tuning and deployment stages. Practical on-device tasks demand different quantization precisions (i.e. different bit-widths), e.g., understanding tasks tend to exhibit higher tolerance to reduced precision compared to generation tasks. Conventional quantization, typically relying on scaling factors that are incompatible across bit-widths, fails to support the on-device switching of precisions when confronted with complex real-world scenarios. To overcome the dilemma, we propose OTARo, a novel method that enables on-device LLMs to flexibly switch quantization precisions while maintaining performance robustness through once fine-tuning. OTARo introduces Shared Exponent Floating Point (SEFP), a distinct quantization mechanism, to produce different bit-widths through simple mantissa truncations of a single model. Moreover, to achieve bit-width robustness in downstream applications, OTARo performs a learning process toward losses induced by different bit-widths. The method involves two critical strategies: (1) Exploitation-Exploration Bit-Width Path Search (BPS), which iteratively updates the search path via a designed scoring mechanism; (2) Low-Precision Asynchronous Accumulation (LAA), which performs asynchronous gradient accumulations and delayed updates under low bit-widths. Experiments on popular LLMs, e.g., LLaMA3.2-1B, LLaMA3-8B, demonstrate that OTARo achieves consistently strong and robust performance for all precisions.
Federated Knowledge Transfer Fine-tuning Large Server Model with Resource-Constrained IoT Clients
Jul 07, 2024The training of large models, involving fine-tuning, faces the scarcity of high-quality data. Compared to the solutions based on centralized data centers, updating large models in the Internet of Things (IoT) faces challenges in coordinating knowledge from distributed clients by using their private and heterogeneous data. To tackle such a challenge, we propose KOALA (Federated Knowledge Transfer Fine-tuning Large Server Model with Resource-Constrained IoT Clients) to impel the training of large models in IoT. Since the resources obtained by IoT clients are limited and restricted, it is infeasible to locally execute large models and also update them in a privacy-preserving manner. Therefore, we leverage federated learning and knowledge distillation to update large models through collaboration with their small models, which can run locally at IoT clients to process their private data separately and enable large-small model knowledge transfer through iterative learning between the server and clients. Moreover, to support clients with similar or different computing capacities, KOALA is designed with two kinds of large-small model joint learning modes, namely to be homogeneous or heterogeneous. Experimental results demonstrate that compared to the conventional approach, our method can not only achieve similar training performance but also significantly reduce the need for local storage and computing power resources.
Efficient and Economic Large Language Model Inference with Attention Offloading
May 03, 2024
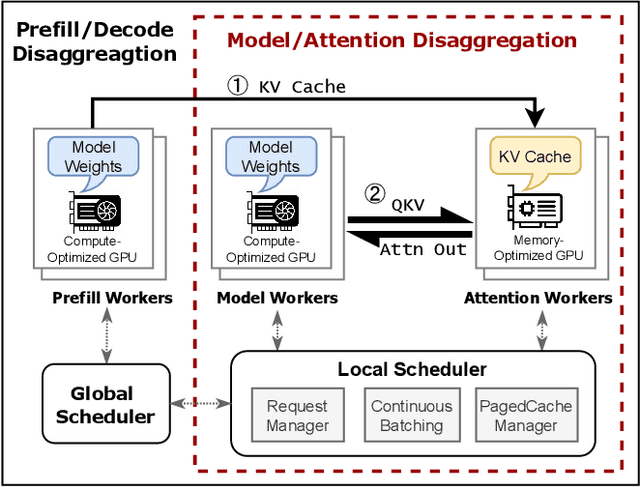


Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.