 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFusion: Accelerating MoE Training via Federated Knowledge Distillation from Heterogeneous Edge Devices
Feb 15, 2026Recent Mixture-of-Experts (MoE)-based large language models (LLMs) such as Qwen-MoE and DeepSeek-MoE are transforming generative AI in natural language processing. However, these models require vast and diverse training data. Federated learning (FL) addresses this challenge by leveraging private data from heterogeneous edge devices for privacy-preserving MoE training. Nonetheless, traditional FL approaches require devices to host local MoE models, which is impractical for resource-constrained devices due to large model sizes. To address this, we propose DeepFusion, the first scalable federated MoE training framework that enables the fusion of heterogeneous on-device LLM knowledge via federated knowledge distillation, yielding a knowledge-abundant global MoE model. Specifically, DeepFusion features each device to independently configure and train an on-device LLM tailored to its own needs and hardware limitations. Furthermore, we propose a novel View-Aligned Attention (VAA) module that integrates multi-stage feature representations from the global MoE model to construct a predictive perspective aligned with on-device LLMs, thereby enabling effective cross-architecture knowledge distillation. By explicitly aligning predictive perspectives, VAA resolves the view-mismatch problem in traditional federated knowledge distillation, which arises from heterogeneity in model architectures and prediction behaviors between on-device LLMs and the global MoE model. Experiments with industry-level MoE models (Qwen-MoE and DeepSeek-MoE) and real-world datasets (medical and finance) demonstrate that DeepFusion achieves performance close to centralized MoE training. Compared with key federated MoE baselines, DeepFusion reduces communication costs by up to 71% and improves token perplexity by up to 5.28%.
Domain-Agnostic Causal-Aware Audio Transformer for Infant Cry Classification
Dec 18, 2025Accurate and interpretable classification of infant cry paralinguistics is essential for early detection of neonatal distress and clinical decision support. However, many existing deep learning methods rely on correlation-driven acoustic representations, which makes them vulnerable to noise, spurious cues, and domain shifts across recording environments. We propose DACH-TIC, a Domain-Agnostic Causal-Aware Hierarchical Audio Transformer for robust infant cry classification. The model integrates causal attention, hierarchical representation learning, multi-task supervision, and adversarial domain generalization within a unified framework. DACH-TIC employs a structured transformer backbone with local token-level and global semantic encoders, augmented by causal attention masking and controlled perturbation training to approximate counterfactual acoustic variations. A domain-adversarial objective promotes environment-invariant representations, while multi-task learning jointly optimizes cry type recognition, distress intensity estimation, and causal relevance prediction. The model is evaluated on the Baby Chillanto and Donate-a-Cry datasets, with ESC-50 environmental noise overlays for domain augmentation. Experimental results show that DACH-TIC outperforms state-of-the-art baselines, including HTS-AT and SE-ResNet Transformer, achieving improvements of 2.6 percent in accuracy and 2.2 points in macro-F1 score, alongside enhanced causal fidelity. The model generalizes effectively to unseen acoustic environments, with a domain performance gap of only 2.4 percent, demonstrating its suitability for real-world neonatal acoustic monitoring systems.
Benchmarking Mutual Information-based Loss Functions in Federated Learning
Apr 16, 2025Federated Learning (FL) has attracted considerable interest due to growing privacy concerns and regulations like the General Data Protection Regulation (GDPR), which stresses the importance of privacy-preserving and fair machine learning approaches. In FL, model training takes place on decentralized data, so as to allow clients to upload a locally trained model and receive a globally aggregated model without exposing sensitive information. However, challenges related to fairness-such as biases, uneven performance among clients, and the "free rider" issue complicates its adoption. In this paper, we examine the use of Mutual Information (MI)-based loss functions to address these concerns. MI has proven to be a powerful method for measuring dependencies between variables and optimizing deep learning models. By leveraging MI to extract essential features and minimize biases, we aim to improve both the fairness and effectiveness of FL systems. Through extensive benchmarking, we assess the impact of MI-based losses in reducing disparities among clients while enhancing the overall performance of FL.
Query-based Knowledge Transfer for Heterogeneous Learning Environments
Apr 12, 2025Decentralized collaborative learning under data heterogeneity and privacy constraints has rapidly advanced. However, existing solutions like federated learning, ensembles, and transfer learning, often fail to adequately serve the unique needs of clients, especially when local data representation is limited. To address this issue, we propose a novel framework called Query-based Knowledge Transfer (QKT) that enables tailored knowledge acquisition to fulfill specific client needs without direct data exchange. QKT employs a data-free masking strategy to facilitate communication-efficient query-focused knowledge transfer while refining task-specific parameters to mitigate knowledge interference and forgetting. Our experiments, conducted on both standard and clinical benchmarks, show that QKT significantly outperforms existing collaborative learning methods by an average of 20.91\% points in single-class query settings and an average of 14.32\% points in multi-class query scenarios. Further analysis and ablation studies reveal that QKT effectively balances the learning of new and existing knowledge, showing strong potential for its application in decentralized learning.
Mitigating Malicious Attacks in Federated Learning via Confidence-aware Defense
Aug 05, 2024


Federated Learning (FL) is an emerging distributed machine learning paradigm that allows multiple clients to collaboratively train a global model without sharing private local data. However, FL systems are vulnerable to attacks from malicious clients, who can degrade the global model performance through data poisoning and model poisoning. Existing defense methods typically focus on a single type of attack, such as Byzantine attacks or backdoor attacks, and are often ineffective against potential data poisoning attacks like label flipping and label shuffling. Additionally, these methods often lack accuracy and robustness in detecting and handling malicious updates. To address these issues, we propose a novel method based on model confidence scores, which evaluates the uncertainty of client model updates to detect and defend against malicious clients. Our approach is comprehensively effective for both model poisoning and data poisoning attacks and is capable of accurately identifying and mitigating potential malicious updates from being aggregated. Experimental results demonstrate that our method significantly improves the robustness of FL systems against various types of attacks, also achieving higher model accuracy and stability across various scenarios.
Federated Knowledge Transfer Fine-tuning Large Server Model with Resource-Constrained IoT Clients
Jul 07, 2024The training of large models, involving fine-tuning, faces the scarcity of high-quality data. Compared to the solutions based on centralized data centers, updating large models in the Internet of Things (IoT) faces challenges in coordinating knowledge from distributed clients by using their private and heterogeneous data. To tackle such a challenge, we propose KOALA (Federated Knowledge Transfer Fine-tuning Large Server Model with Resource-Constrained IoT Clients) to impel the training of large models in IoT. Since the resources obtained by IoT clients are limited and restricted, it is infeasible to locally execute large models and also update them in a privacy-preserving manner. Therefore, we leverage federated learning and knowledge distillation to update large models through collaboration with their small models, which can run locally at IoT clients to process their private data separately and enable large-small model knowledge transfer through iterative learning between the server and clients. Moreover, to support clients with similar or different computing capacities, KOALA is designed with two kinds of large-small model joint learning modes, namely to be homogeneous or heterogeneous. Experimental results demonstrate that compared to the conventional approach, our method can not only achieve similar training performance but also significantly reduce the need for local storage and computing power resources.
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024
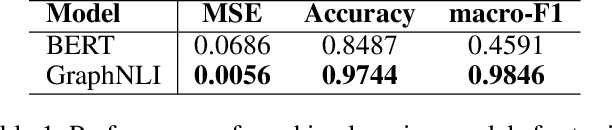

The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.
Flashback: Understanding and Mitigating Forgetting in Federated Learning
Feb 08, 2024In Federated Learning (FL), forgetting, or the loss of knowledge across rounds, hampers algorithm convergence, particularly in the presence of severe data heterogeneity among clients. This study explores the nuances of this issue, emphasizing the critical role of forgetting in FL's inefficient learning within heterogeneous data contexts. Knowledge loss occurs in both client-local updates and server-side aggregation steps; addressing one without the other fails to mitigate forgetting. We introduce a metric to measure forgetting granularly, ensuring distinct recognition amid new knowledge acquisition. Leveraging these insights, we propose Flashback, an FL algorithm with a dynamic distillation approach that is used to regularize the local models, and effectively aggregate their knowledge. Across different benchmarks, Flashback outperforms other methods, mitigates forgetting, and achieves faster round-to-target-accuracy, by converging in 6 to 16 rounds.
An Empirical Study of Efficiency and Privacy of Federated Learning Algorithms
Dec 24, 2023In today's world, the rapid expansion of IoT networks and the proliferation of smart devices in our daily lives, have resulted in the generation of substantial amounts of heterogeneous data. These data forms a stream which requires special handling. To handle this data effectively, advanced data processing technologies are necessary to guarantee the preservation of both privacy and efficiency. Federated learning emerged as a distributed learning method that trains models locally and aggregates them on a server to preserve data privacy. This paper showcases two illustrative scenarios that highlight the potential of federated learning (FL) as a key to delivering efficient and privacy-preserving machine learning within IoT networks. We first give the mathematical foundations for key aggregation algorithms in federated learning, i.e., FedAvg and FedProx. Then, we conduct simulations, using Flower Framework, to show the \textit{efficiency} of these algorithms by training deep neural networks on common datasets and show a comparison between the accuracy and loss metrics of FedAvg and FedProx. Then, we present the results highlighting the trade-off between maintaining privacy versus accuracy via simulations - involving the implementation of the differential privacy (DP) method - in Pytorch and Opacus ML frameworks on common FL datasets and data distributions for both FedAvg and FedProx strategies.
Stock Market Price Prediction: A Hybrid LSTM and Sequential Self-Attention based Approach
Aug 07, 2023One of the most enticing research areas is the stock market, and projecting stock prices may help investors profit by making the best decisions at the correct time. Deep learning strategies have emerged as a critical technique in the field of the financial market. The stock market is impacted due to two aspects, one is the geo-political, social and global events on the bases of which the price trends could be affected. Meanwhile, the second aspect purely focuses on historical price trends and seasonality, allowing us to forecast stock prices. In this paper, our aim is to focus on the second aspect and build a model that predicts future prices with minimal errors. In order to provide better prediction results of stock price, we propose a new model named Long Short-Term Memory (LSTM) with Sequential Self-Attention Mechanism (LSTM-SSAM). Finally, we conduct extensive experiments on the three stock datasets: SBIN, HDFCBANK, and BANKBARODA. The experimental results prove the effectiveness and feasibility of the proposed model compared to existing models. The experimental findings demonstrate that the root-mean-squared error (RMSE), and R-square (R2) evaluation indicators are giving the best results.