 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLaMix: Residual Latency-Aware Mixing for Delay-Robust Financial Time-Series Forecasting
Mar 21, 2026Financial time-series forecasting in real-world high-frequency markets is often hindered by delayed or partially stale observations caused by asynchronous data acquisition and transmission latency. To better reflect such practical conditions, we investigate a simulated delay setting where a portion of historical signals is corrupted by a Zero-Order Hold (ZOH) mechanism, significantly increasing forecasting difficulty through stepwise stagnation artifacts. In this paper, we propose ReLaMix (Residual Latency-Aware Mixing Network), a lightweight extension of TimeMixer that integrates learnable bottleneck compression with residual refinement for robust signal recovery under delayed observations. ReLaMix explicitly suppresses redundancy from repeated stale values while preserving informative market dynamics via residual mixing enhancement. Experiments on a large-scale second-resolution PAXGUSDT benchmark demonstrate that ReLaMix consistently achieves state-of-the-art accuracy across multiple delay ratios and prediction horizons, outperforming strong mixer and Transformer baselines with substantially fewer parameters. Moreover, additional evaluations on BTCUSDT confirm the cross-asset generalization ability of the proposed framework. These results highlight the effectiveness of residual bottleneck mixing for high-frequency financial forecasting under realistic latency-induced staleness.
Boosting Neural Video Representation via Online Structural Reparameterization
Nov 14, 2025Neural Video Representation~(NVR) is a promising paradigm for video compression, showing great potential in improving video storage and transmission efficiency. While recent advances have made efforts in architectural refinements to improve representational capability, these methods typically involve complex designs, which may incur increased computational overhead and lack the flexibility to integrate into other frameworks. Moreover, the inherent limitation in model capacity restricts the expressiveness of NVR networks, resulting in a performance bottleneck. To overcome these limitations, we propose Online-RepNeRV, a NVR framework based on online structural reparameterization. Specifically, we propose a universal reparameterization block named ERB, which incorporates multiple parallel convolutional paths to enhance the model capacity. To mitigate the overhead, an online reparameterization strategy is adopted to dynamically fuse the parameters during training, and the multi-branch structure is equivalently converted into a single-branch structure after training. As a result, the additional computational and parameter complexity is confined to the encoding stage, without affecting the decoding efficiency. Extensive experiments on mainstream video datasets demonstrate that our method achieves an average PSNR gain of 0.37-2.7 dB over baseline methods, while maintaining comparable training time and decoding speed.
* 15 pages, 7 figures
Benchmarking Mutual Information-based Loss Functions in Federated Learning
Apr 16, 2025



Federated Learning (FL) has attracted considerable interest due to growing privacy concerns and regulations like the General Data Protection Regulation (GDPR), which stresses the importance of privacy-preserving and fair machine learning approaches. In FL, model training takes place on decentralized data, so as to allow clients to upload a locally trained model and receive a globally aggregated model without exposing sensitive information. However, challenges related to fairness-such as biases, uneven performance among clients, and the "free rider" issue complicates its adoption. In this paper, we examine the use of Mutual Information (MI)-based loss functions to address these concerns. MI has proven to be a powerful method for measuring dependencies between variables and optimizing deep learning models. By leveraging MI to extract essential features and minimize biases, we aim to improve both the fairness and effectiveness of FL systems. Through extensive benchmarking, we assess the impact of MI-based losses in reducing disparities among clients while enhancing the overall performance of FL.
Hierarchical Knowledge Structuring for Effective Federated Learning in Heterogeneous Environments
Apr 04, 2025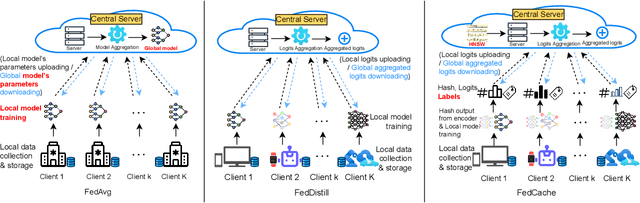
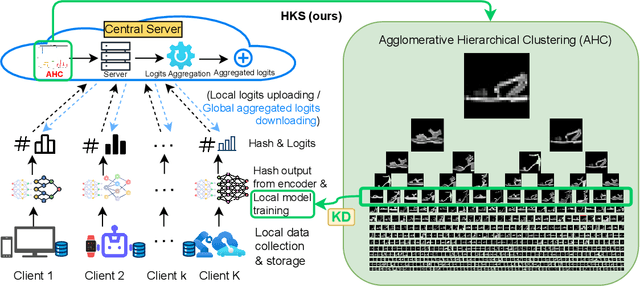
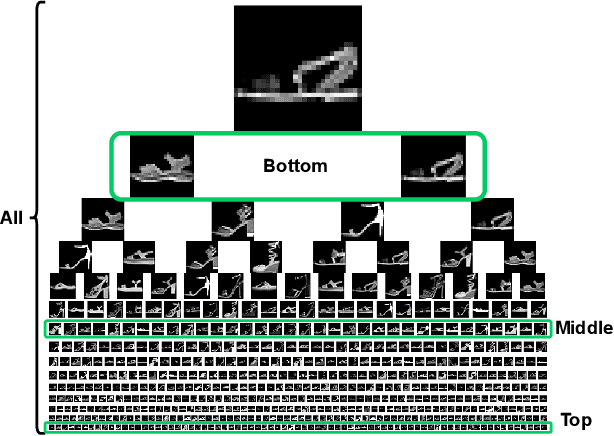
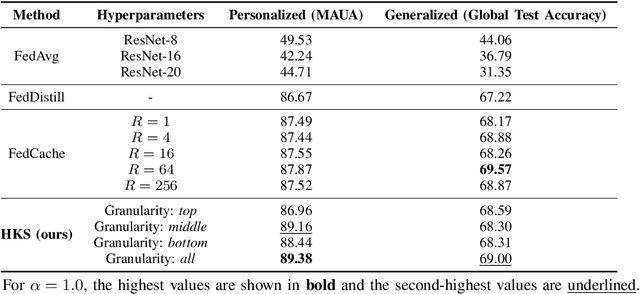
Federated learning enables collaborative model training across distributed entities while maintaining individual data privacy. A key challenge in federated learning is balancing the personalization of models for local clients with generalization for the global model. Recent efforts leverage logit-based knowledge aggregation and distillation to overcome these issues. However, due to the non-IID nature of data across diverse clients and the imbalance in the client's data distribution, directly aggregating the logits often produces biased knowledge that fails to apply to individual clients and obstructs the convergence of local training. To solve this issue, we propose a Hierarchical Knowledge Structuring (HKS) framework that formulates sample logits into a multi-granularity codebook to represent logits from personalized per-sample insights to globalized per-class knowledge. The unsupervised bottom-up clustering method is leveraged to enable the global server to provide multi-granularity responses to local clients. These responses allow local training to integrate supervised learning objectives with global generalization constraints, which results in more robust representations and improved knowledge sharing in subsequent training rounds. The proposed framework's effectiveness is validated across various benchmarks and model architectures.
* 9 pages, 3 figures, IJCNN 2025
Mitigating Malicious Attacks in Federated Learning via Confidence-aware Defense
Aug 05, 2024


Federated Learning (FL) is an emerging distributed machine learning paradigm that allows multiple clients to collaboratively train a global model without sharing private local data. However, FL systems are vulnerable to attacks from malicious clients, who can degrade the global model performance through data poisoning and model poisoning. Existing defense methods typically focus on a single type of attack, such as Byzantine attacks or backdoor attacks, and are often ineffective against potential data poisoning attacks like label flipping and label shuffling. Additionally, these methods often lack accuracy and robustness in detecting and handling malicious updates. To address these issues, we propose a novel method based on model confidence scores, which evaluates the uncertainty of client model updates to detect and defend against malicious clients. Our approach is comprehensively effective for both model poisoning and data poisoning attacks and is capable of accurately identifying and mitigating potential malicious updates from being aggregated. Experimental results demonstrate that our method significantly improves the robustness of FL systems against various types of attacks, also achieving higher model accuracy and stability across various scenarios.
Mitigate Domain Shift by Primary-Auxiliary Objectives Association for Generalizing Person ReID
Oct 24, 2023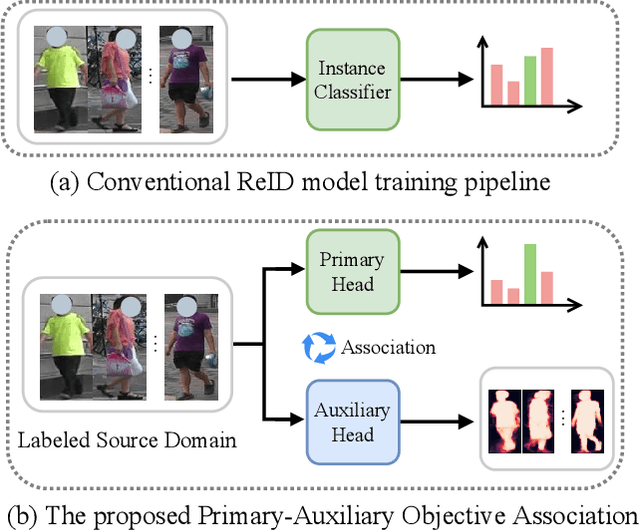
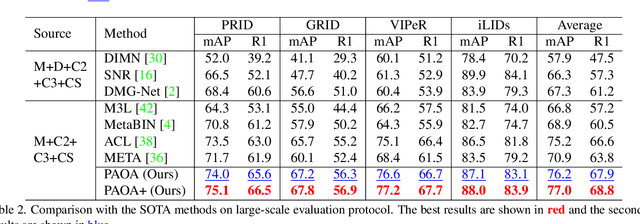
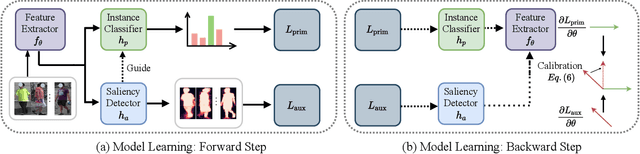
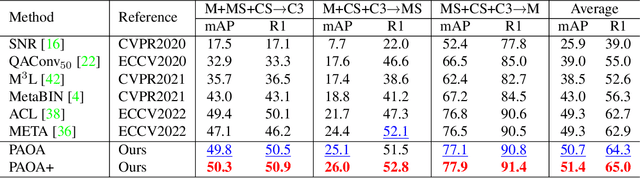
While deep learning has significantly improved ReID model accuracy under the independent and identical distribution (IID) assumption, it has also become clear that such models degrade notably when applied to an unseen novel domain due to unpredictable/unknown domain shift. Contemporary domain generalization (DG) ReID models struggle in learning domain-invariant representation solely through training on an instance classification objective. We consider that a deep learning model is heavily influenced and therefore biased towards domain-specific characteristics, e.g., background clutter, scale and viewpoint variations, limiting the generalizability of the learned model, and hypothesize that the pedestrians are domain invariant owning they share the same structural characteristics. To enable the ReID model to be less domain-specific from these pure pedestrians, we introduce a method that guides model learning of the primary ReID instance classification objective by a concurrent auxiliary learning objective on weakly labeled pedestrian saliency detection. To solve the problem of conflicting optimization criteria in the model parameter space between the two learning objectives, we introduce a Primary-Auxiliary Objectives Association (PAOA) mechanism to calibrate the loss gradients of the auxiliary task towards the primary learning task gradients. Benefiting from the harmonious multitask learning design, our model can be extended with the recent test-time diagram to form the PAOA+, which performs on-the-fly optimization against the auxiliary objective in order to maximize the model's generative capacity in the test target domain. Experiments demonstrate the superiority of the proposed PAOA model.
Rapid Person Re-Identification via Sub-space Consistency Regularization
Jul 13, 2022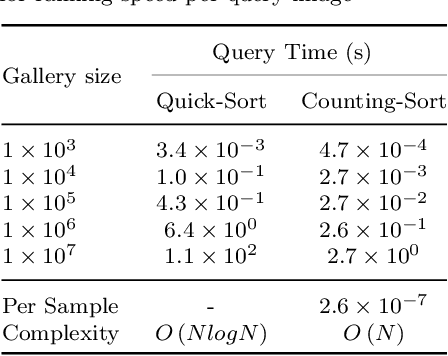
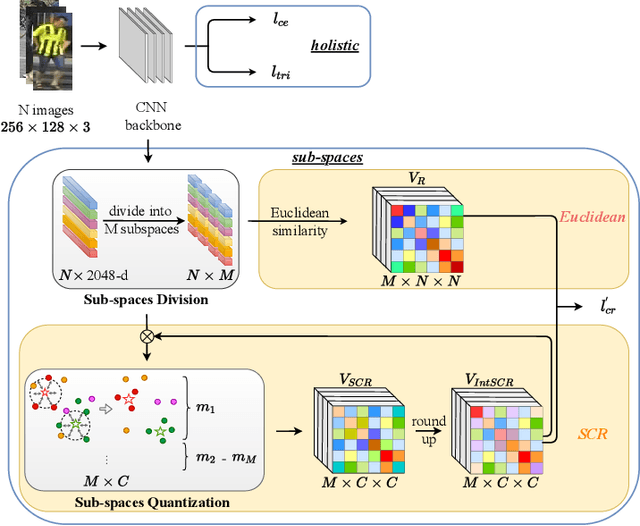
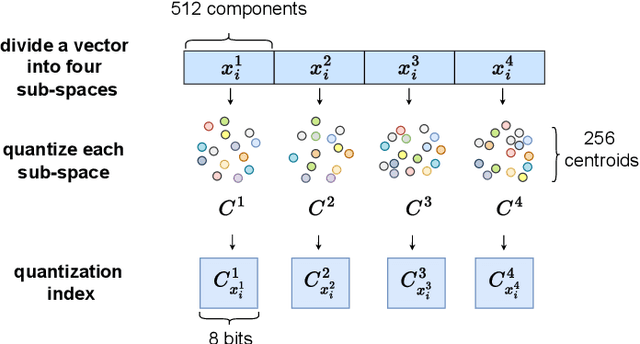
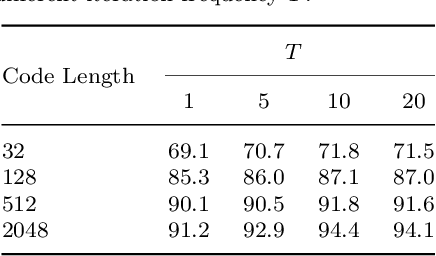
Person Re-Identification (ReID) matches pedestrians across disjoint cameras. Existing ReID methods adopting real-value feature descriptors have achieved high accuracy, but they are low in efficiency due to the slow Euclidean distance computation as well as complex quick-sort algorithms. Recently, some works propose to yield binary encoded person descriptors which instead only require fast Hamming distance computation and simple counting-sort algorithms. However, the performances of such binary encoded descriptors, especially with short code (e.g., 32 and 64 bits), are hardly satisfactory given the sparse binary space. To strike a balance between the model accuracy and efficiency, we propose a novel Sub-space Consistency Regularization (SCR) algorithm that can speed up the ReID procedure by $0.25$ times than real-value features under the same dimensions whilst maintaining a competitive accuracy, especially under short codes. SCR transforms real-value features vector (e.g., 2048 float32) with short binary codes (e.g., 64 bits) by first dividing real-value features vector into $M$ sub-spaces, each with $C$ clustered centroids. Thus the distance between two samples can be expressed as the summation of the respective distance to the centroids, which can be sped up by offline calculation and maintained via a look-up table. On the other side, these real-value centroids help to achieve significantly higher accuracy than using binary code. Lastly, we convert the distance look-up table to be integer and apply the counting-sort algorithm to speed up the ranking stage. We also propose a novel consistency regularization with an iterative framework. Experimental results on Market-1501 and DukeMTMC-reID show promising and exciting results. Under short code, our proposed SCR enjoys Real-value-level accuracy and Hashing-level speed.
Feature-Distribution Perturbation and Calibration for Generalized Person ReID
May 23, 2022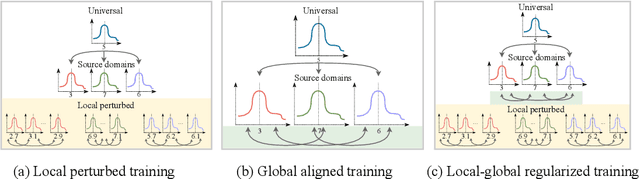
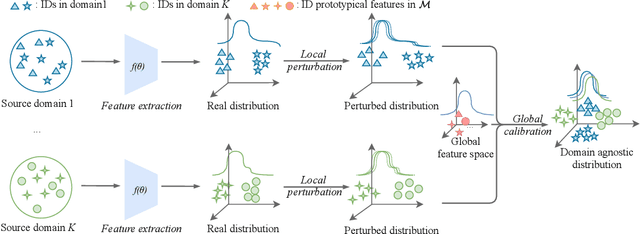
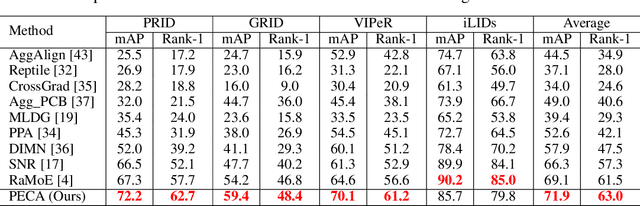
Person Re-identification (ReID) has been advanced remarkably over the last 10 years along with the rapid development of deep learning for visual recognition. However, the i.i.d. (independent and identically distributed) assumption commonly held in most deep learning models is somewhat non-applicable to ReID considering its objective to identify images of the same pedestrian across cameras at different locations often of variable and independent domain characteristics that are also subject to view-biased data distribution. In this work, we propose a Feature-Distribution Perturbation and Calibration (PECA) method to derive generic feature representations for person ReID, which is not only discriminative across cameras but also agnostic and deployable to arbitrary unseen target domains. Specifically, we perform per-domain feature-distribution perturbation to refrain the model from overfitting to the domain-biased distribution of each source (seen) domain by enforcing feature invariance to distribution shifts caused by perturbation. Furthermore, we design a global calibration mechanism to align feature distributions across all the source domains to improve the model generalization capacity by eliminating domain bias. These local perturbation and global calibration are conducted simultaneously, which share the same principle to avoid models overfitting by regularization respectively on the perturbed and the original distributions. Extensive experiments were conducted on eight person ReID datasets and the proposed PECA model outperformed the state-of-the-art competitors by significant margins.
Local-Global Associative Frame Assemble in Video Re-ID
Oct 22, 2021
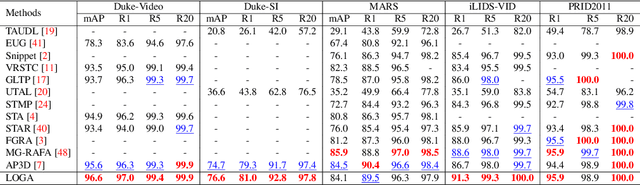
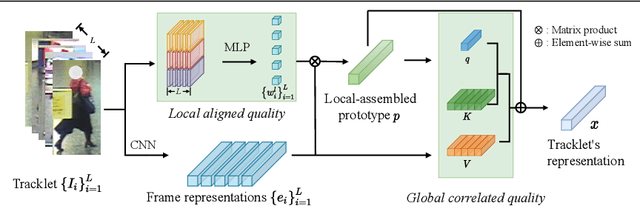

Noisy and unrepresentative frames in automatically generated object bounding boxes from video sequences cause significant challenges in learning discriminative representations in video re-identification (Re-ID). Most existing methods tackle this problem by assessing the importance of video frames according to either their local part alignments or global appearance correlations separately. However, given the diverse and unknown sources of noise which usually co-exist in captured video data, existing methods have not been effective satisfactorily. In this work, we explore jointly both local alignments and global correlations with further consideration of their mutual promotion/reinforcement so to better assemble complementary discriminative Re-ID information within all the relevant frames in video tracklets. Specifically, we concurrently optimise a local aligned quality (LAQ) module that distinguishes the quality of each frame based on local alignments, and a global correlated quality (GCQ) module that estimates global appearance correlations. With the help of a local-assembled global appearance prototype, we associate LAQ and GCQ to exploit their mutual complement. Extensive experiments demonstrate the superiority of the proposed model against state-of-the-art methods on five Re-ID benchmarks, including MARS, Duke-Video, Duke-SI, iLIDS-VID, and PRID2011.
Gated Multiple Feedback Network for Image Super-Resolution
Jul 10, 2019

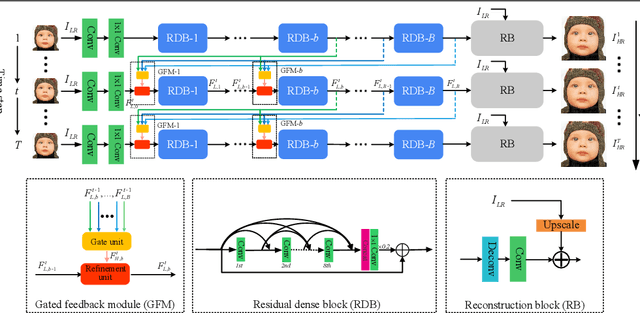
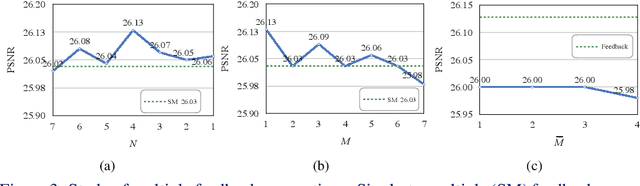
The rapid development of deep learning (DL) has driven single image super-resolution (SR) into a new era. However, in most existing DL based image SR networks, the information flows are solely feedforward, and the high-level features cannot be fully explored. In this paper, we propose the gated multiple feedback network (GMFN) for accurate image SR, in which the representation of low-level features are efficiently enriched by rerouting multiple high-level features. We cascade multiple residual dense blocks (RDBs) and recurrently unfolds them across time. The multiple feedback connections between two adjacent time steps in the proposed GMFN exploits multiple high-level features captured under large receptive fields to refine the low-level features lacking enough contextual information. The elaborately designed gated feedback module (GFM) efficiently selects and further enhances useful information from multiple rerouted high-level features, and then refine the low-level features with the enhanced high-level information. Extensive experiments demonstrate the superiority of our proposed GMFN against state-of-the-art SR methods in terms of both quantitative metrics and visual quality. Code is available at https://github.com/liqilei/GMFN.