 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Person Re-Identification via Sub-space Consistency Regularization
Jul 13, 2022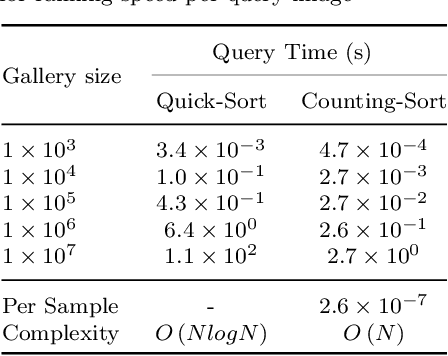
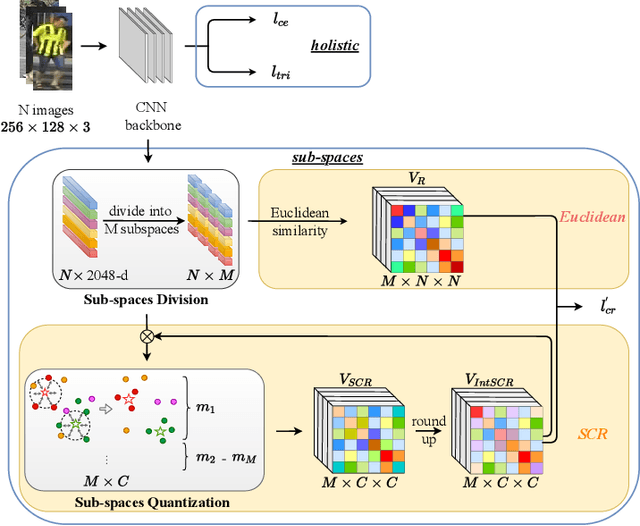
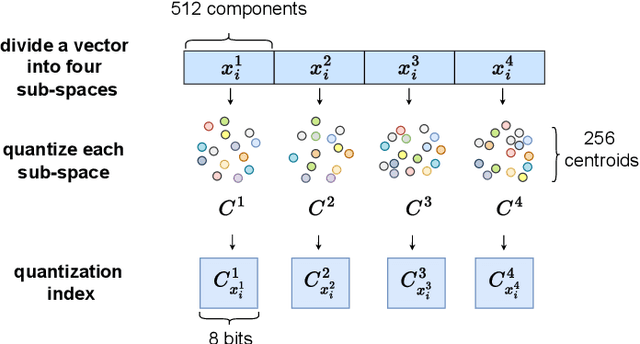
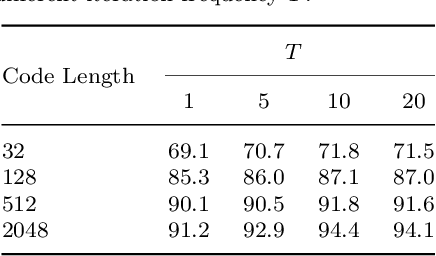
Person Re-Identification (ReID) matches pedestrians across disjoint cameras. Existing ReID methods adopting real-value feature descriptors have achieved high accuracy, but they are low in efficiency due to the slow Euclidean distance computation as well as complex quick-sort algorithms. Recently, some works propose to yield binary encoded person descriptors which instead only require fast Hamming distance computation and simple counting-sort algorithms. However, the performances of such binary encoded descriptors, especially with short code (e.g., 32 and 64 bits), are hardly satisfactory given the sparse binary space. To strike a balance between the model accuracy and efficiency, we propose a novel Sub-space Consistency Regularization (SCR) algorithm that can speed up the ReID procedure by $0.25$ times than real-value features under the same dimensions whilst maintaining a competitive accuracy, especially under short codes. SCR transforms real-value features vector (e.g., 2048 float32) with short binary codes (e.g., 64 bits) by first dividing real-value features vector into $M$ sub-spaces, each with $C$ clustered centroids. Thus the distance between two samples can be expressed as the summation of the respective distance to the centroids, which can be sped up by offline calculation and maintained via a look-up table. On the other side, these real-value centroids help to achieve significantly higher accuracy than using binary code. Lastly, we convert the distance look-up table to be integer and apply the counting-sort algorithm to speed up the ranking stage. We also propose a novel consistency regularization with an iterative framework. Experimental results on Market-1501 and DukeMTMC-reID show promising and exciting results. Under short code, our proposed SCR enjoys Real-value-level accuracy and Hashing-level speed.
Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
Dec 15, 2020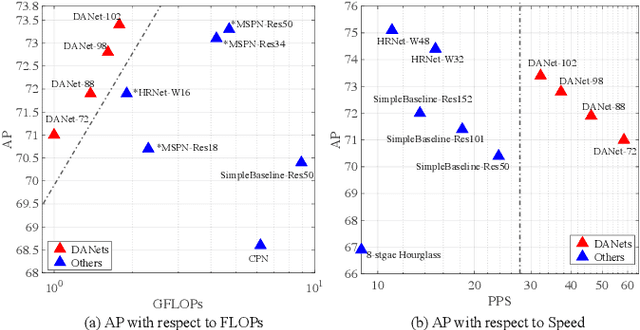

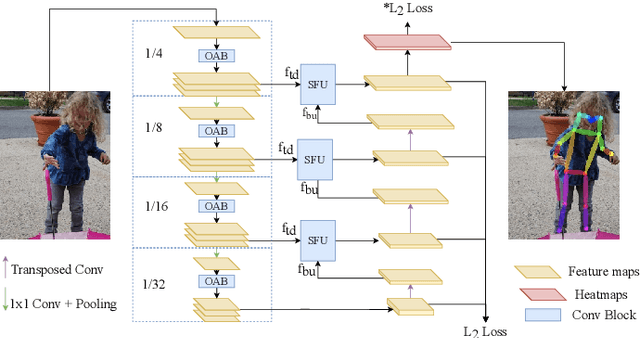
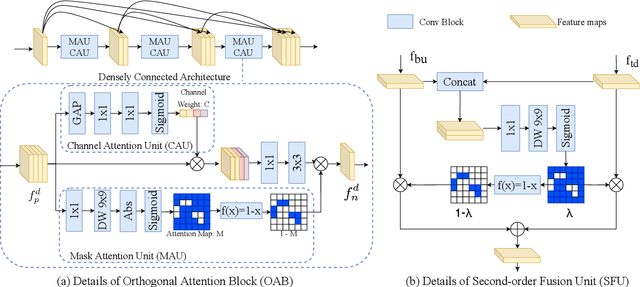
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).