 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human Pose Estimation by Learning Deeply Aggregated Representations
Paper and Code
Dec 15, 2020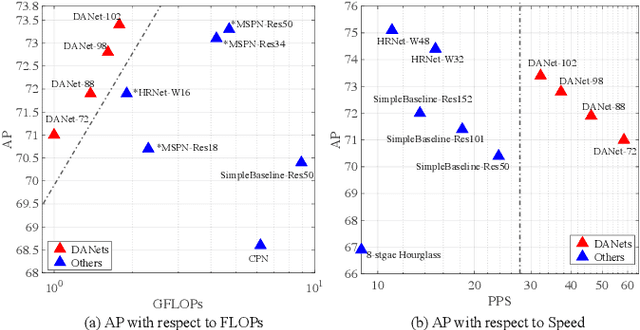

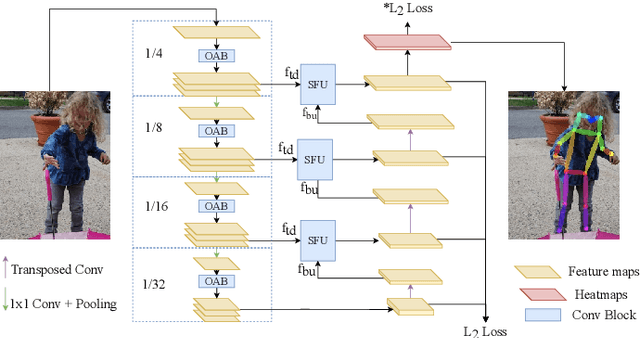
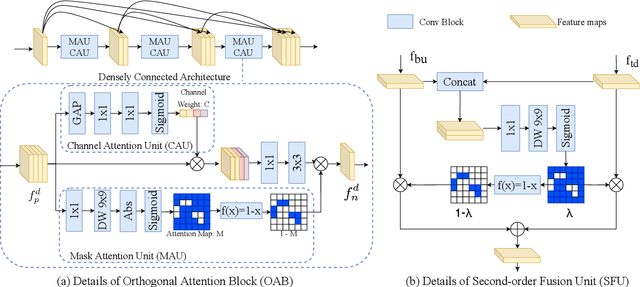
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).