 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadVerse: An Integrated Framework Aligning Visual-Physical Reality for Quadruped Simulation
Jun 05, 2026Simulation is central to robot learning, yet the sim-to-real gap remains a major bottleneck.Existing approaches often tackle visual or dynamic gaps separately, overlooking how these individual mismatches accumulate and propagate throughout the robot's state evolution.In this paper, we introduce QuadVerse, an integrated framework that uses reconstructed scenes as a calibration substrate for aligning visual perception, physical interaction, and actuator dynamics.From captured RGB videos, we reconstruct geometry-constrained 3D Gaussian Splatting (3DGS) scenes that support batched photorealistic ego-view rendering and collision-ready semantic mesh extraction. The meshes further enable contact calibration by initializing spatially varying friction priors and refining them through trajectory-based posterior search.To address remaining actuator discrepancies, QuadVerse trains a residual dynamics compensator by replaying real-world trajectories on the contact-calibrated terrain, reducing the entanglement between terrain-induced contact errors and actuator non-idealities.Experiments show that QuadVerse improves reconstruction quality and locomotion tracking over relevant baselines.Leveraging this foundation, we demonstrate robust zero-shot visual-navigation policy deployment without task-specific real-world rollouts.
GesVLA: Gesture-Aware Vision-Language-Action Model Embedded Representations
May 21, 2026Vision-Language-Action (VLA) models have shown strong potential for general-purpose robot manipulation by unifying perception and action. However, existing VLA systems primarily rely on textual instructions and struggle to resolve spatial ambiguity in complex scenes with multiple similar objects. To address this limitation, we introduce gesture as a parallel instruction modality and propose a Gesture-aware Vision-Language-Action model (GesVLA). Our approach encodes gesture features directly into the latent space, enabling them to participate in both high-level reasoning and low-level action generation, and adopts a dual-VLM architecture to achieve tight coupling between gesture representations and action policies. At the data level, we construct a scalable gesture data generation pipeline by rendering hand models onto real-world scene images. This reduces the sim-to-real visual gap while producing rich data with diverse motion patterns and corresponding pointing annotations. In addition, we employ a two-stage training strategy to equip the model with both gesture perception and action prediction capabilities. We evaluate our approach on multiple real-world robotic tasks, including a controlled block manipulation task for validation and more practical scenarios such as product and produce selection. Experimental results show that incorporating gesture consistently improves target grounding accuracy and human-robot interaction efficiency, especially in complex and cluttered environments. Project page: https://gwxuan.github.io/GesVLA/.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025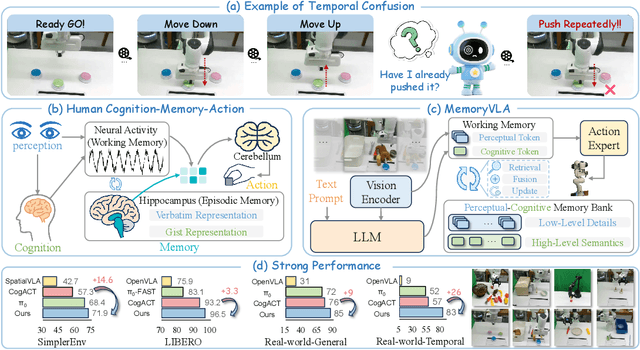
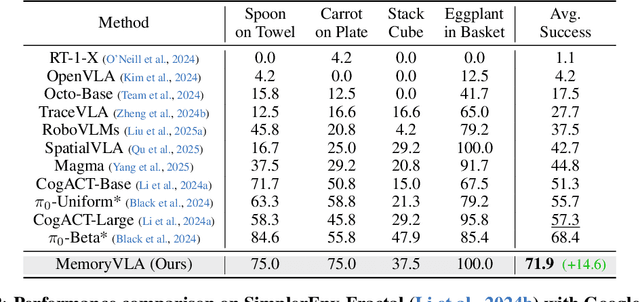
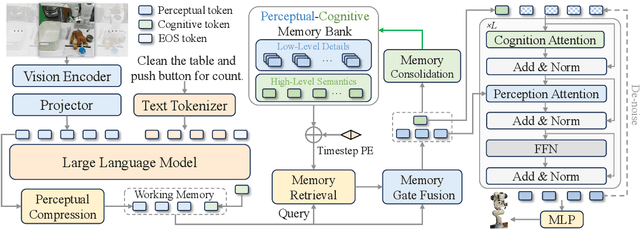
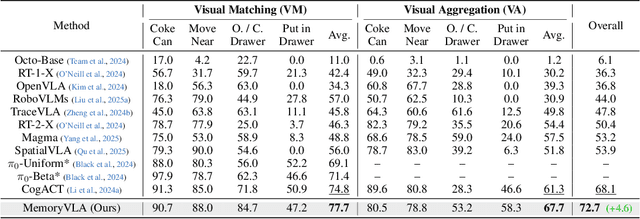
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024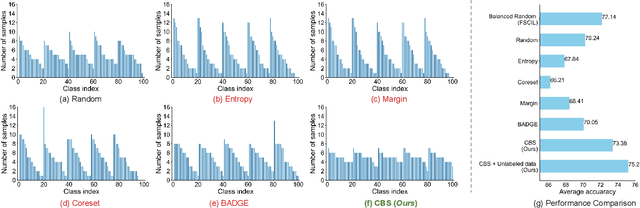
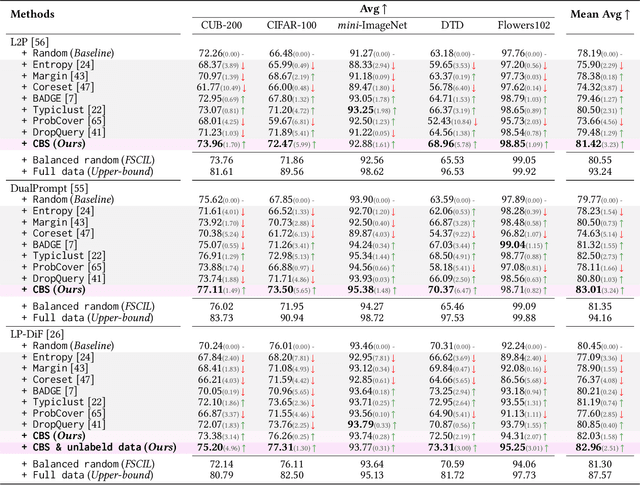

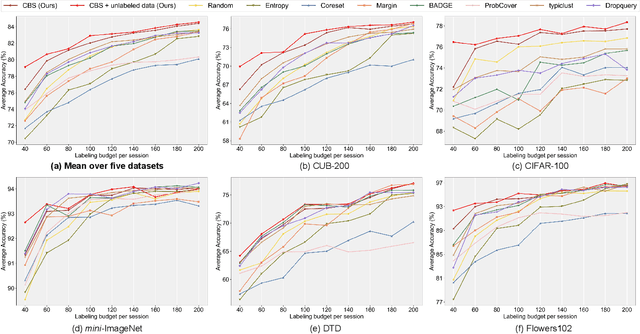
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
IMWA: Iterative Model Weight Averaging Benefits Class-Imbalanced Learning Tasks
Apr 25, 2024



Model Weight Averaging (MWA) is a technique that seeks to enhance model's performance by averaging the weights of multiple trained models. This paper first empirically finds that 1) the vanilla MWA can benefit the class-imbalanced learning, and 2) performing model averaging in the early epochs of training yields a greater performance improvement than doing that in later epochs. Inspired by these two observations, in this paper we propose a novel MWA technique for class-imbalanced learning tasks named Iterative Model Weight Averaging (IMWA). Specifically, IMWA divides the entire training stage into multiple episodes. Within each episode, multiple models are concurrently trained from the same initialized model weight, and subsequently averaged into a singular model. Then, the weight of this average model serves as a fresh initialization for the ensuing episode, thus establishing an iterative learning paradigm. Compared to vanilla MWA, IMWA achieves higher performance improvements with the same computational cost. Moreover, IMWA can further enhance the performance of those methods employing EMA strategy, demonstrating that IMWA and EMA can complement each other. Extensive experiments on various class-imbalanced learning tasks, i.e., class-imbalanced image classification, semi-supervised class-imbalanced image classification and semi-supervised object detection tasks showcase the effectiveness of our IMWA.
Learning Prompt with Distribution-Based Feature Replay for Few-Shot Class-Incremental Learning
Jan 03, 2024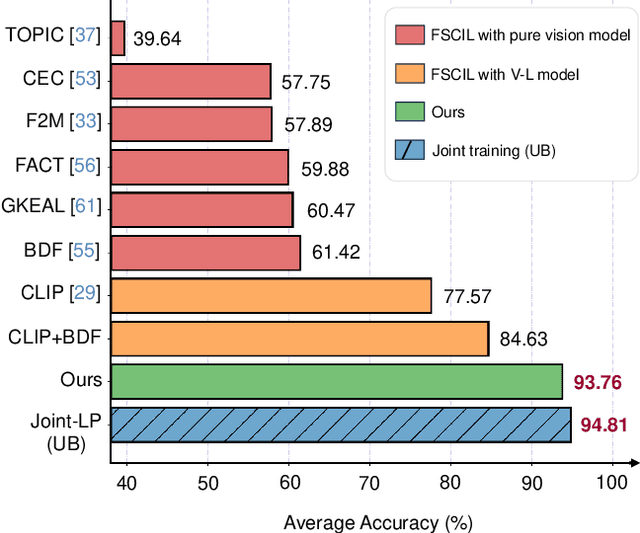



Few-shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes based on very limited training data without forgetting the old ones encountered. Existing studies solely relied on pure visual networks, while in this paper we solved FSCIL by leveraging the Vision-Language model (e.g., CLIP) and propose a simple yet effective framework, named Learning Prompt with Distribution-based Feature Replay (LP-DiF). We observe that simply using CLIP for zero-shot evaluation can substantially outperform the most influential methods. Then, prompt tuning technique is involved to further improve its adaptation ability, allowing the model to continually capture specific knowledge from each session. To prevent the learnable prompt from forgetting old knowledge in the new session, we propose a pseudo-feature replay approach. Specifically, we preserve the old knowledge of each class by maintaining a feature-level Gaussian distribution with a diagonal covariance matrix, which is estimated by the image features of training images and synthesized features generated from a VAE. When progressing to a new session, pseudo-features are sampled from old-class distributions combined with training images of the current session to optimize the prompt, thus enabling the model to learn new knowledge while retaining old knowledge. Experiments on three prevalent benchmarks, i.e., CIFAR100, mini-ImageNet, CUB-200, and two more challenging benchmarks, i.e., SUN-397 and CUB-200$^*$ proposed in this paper showcase the superiority of LP-DiF, achieving new state-of-the-art (SOTA) in FSCIL. Code is publicly available at https://github.com/1170300714/LP-DiF.
W2N:Switching From Weak Supervision to Noisy Supervision for Object Detection
Jul 25, 2022
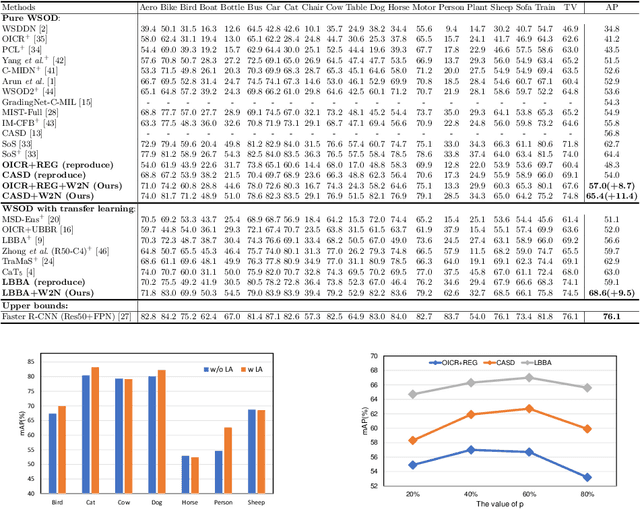
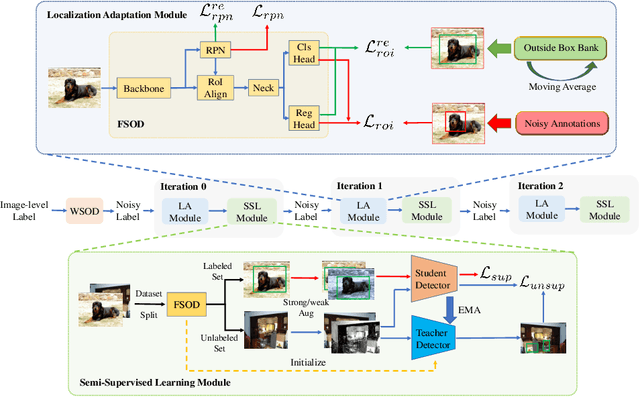
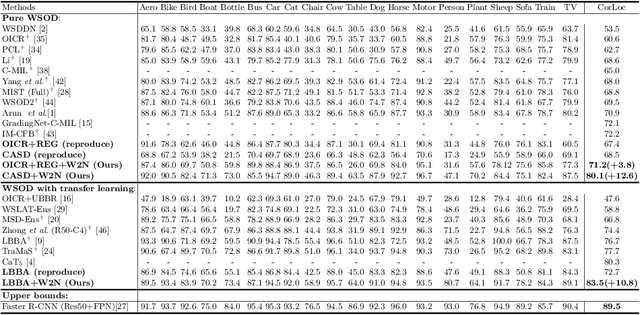
Weakly-supervised object detection (WSOD) aims to train an object detector only requiring the image-level annotations. Recently, some works have managed to select the accurate boxes generated from a well-trained WSOD network to supervise a semi-supervised detection framework for better performance. However, these approaches simply divide the training set into labeled and unlabeled sets according to the image-level criteria, such that sufficient mislabeled or wrongly localized box predictions are chosen as pseudo ground-truths, resulting in a sub-optimal solution of detection performance. To overcome this issue, we propose a novel WSOD framework with a new paradigm that switches from weak supervision to noisy supervision (W2N). Generally, with given pseudo ground-truths generated from the well-trained WSOD network, we propose a two-module iterative training algorithm to refine pseudo labels and supervise better object detector progressively. In the localization adaptation module, we propose a regularization loss to reduce the proportion of discriminative parts in original pseudo ground-truths, obtaining better pseudo ground-truths for further training. In the semi-supervised module, we propose a two tasks instance-level split method to select high-quality labels for training a semi-supervised detector. Experimental results on different benchmarks verify the effectiveness of W2N, and our W2N outperforms all existing pure WSOD methods and transfer learning methods. Our code is publicly available at https://github.com/1170300714/w2n_wsod.
Prototypical Contrastive Language Image Pretraining
Jun 22, 2022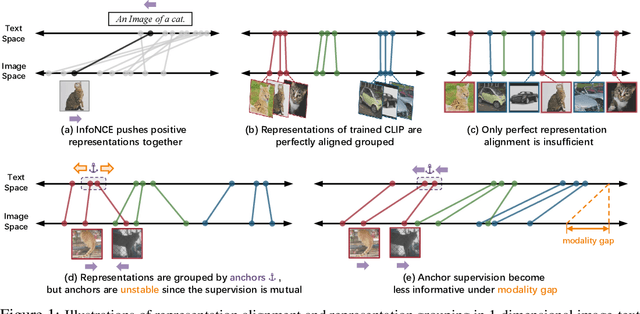
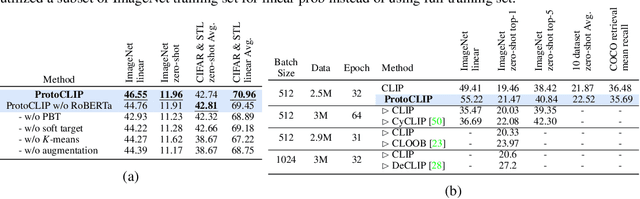

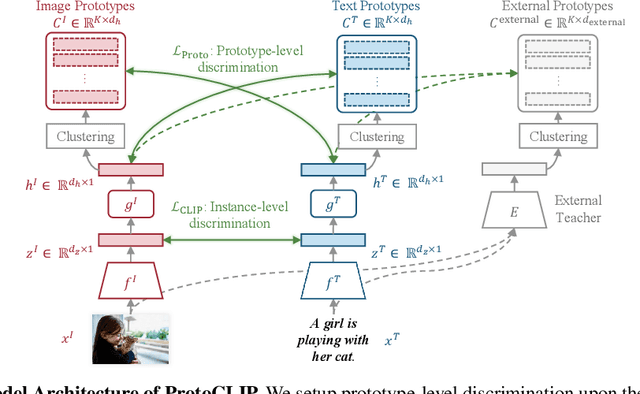
Contrastive Language Image Pretraining (CLIP) received widespread attention since its learned representations can be transferred well to various downstream tasks. During CLIP training, the InfoNCE objective aims to align positive image-text pairs and separate negative ones. In this paper, we show a representation grouping effect during this process: the InfoNCE objective indirectly groups semantically similar representations together via randomly emerged within-modal anchors. We introduce Prototypical Contrastive Language Image Pretraining (ProtoCLIP) to enhance such grouping by boosting its efficiency and increasing its robustness against modality gap. Specifically, ProtoCLIP sets up prototype-level discrimination between image and text spaces, which efficiently transfers higher-level structural knowledge. We further propose Prototypical Back Translation (PBT) to decouple representation grouping from representation alignment, resulting in effective learning of meaningful representations under large modality gap. PBT also enables us to introduce additional external teachers with richer prior knowledge. ProtoCLIP is trained with an online episodic training strategy, which makes it can be scaled up to unlimited amounts of data. Combining the above novel designs, we train our ProtoCLIP on Conceptual Captions and achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement. Codes are available at https://github.com/megvii-research/protoclip.
Attend to Who You Are: Supervising Self-Attention for Keypoint Detection and Instance-Aware Association
Nov 25, 2021
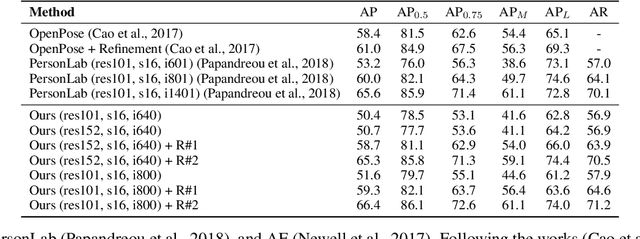
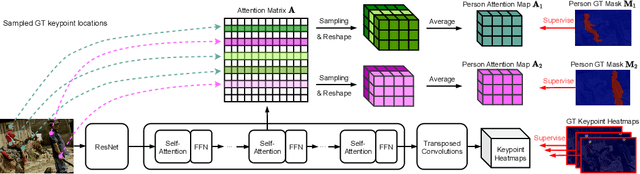
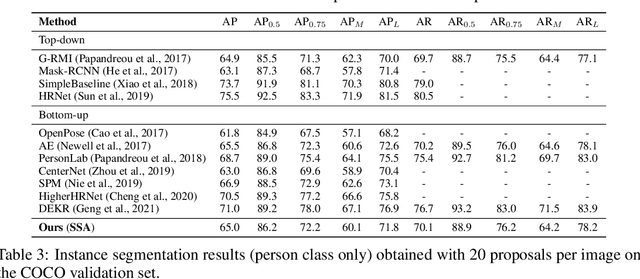
This paper presents a new method to solve keypoint detection and instance association by using Transformer. For bottom-up multi-person pose estimation models, they need to detect keypoints and learn associative information between keypoints. We argue that these problems can be entirely solved by Transformer. Specifically, the self-attention in Transformer measures dependencies between any pair of locations, which can provide association information for keypoints grouping. However, the naive attention patterns are still not subjectively controlled, so there is no guarantee that the keypoints will always attend to the instances to which they belong. To address it we propose a novel approach of supervising self-attention for multi-person keypoint detection and instance association. By using instance masks to supervise self-attention to be instance-aware, we can assign the detected keypoints to their corresponding instances based on the pairwise attention scores, without using pre-defined offset vector fields or embedding like CNN-based bottom-up models. An additional benefit of our method is that the instance segmentation results of any number of people can be directly obtained from the supervised attention matrix, thereby simplifying the pixel assignment pipeline. The experiments on the COCO multi-person keypoint detection challenge and person instance segmentation task demonstrate the effectiveness and simplicity of the proposed method and show a promising way to control self-attention behavior for specific purposes.