 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Contrastive Language Image Pretraining
Jun 22, 2022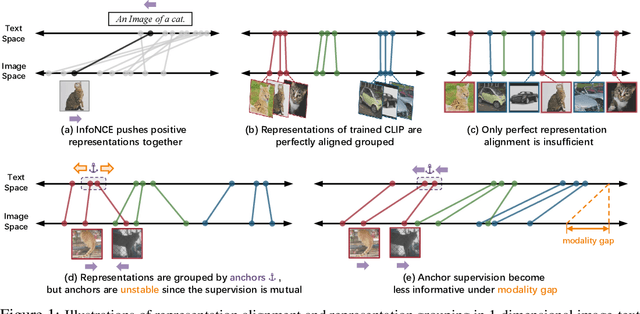
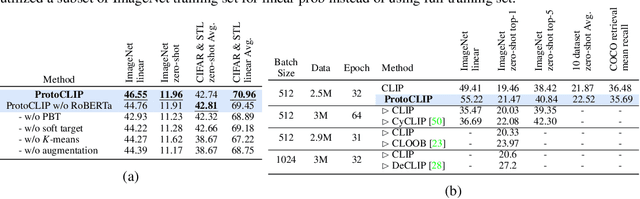

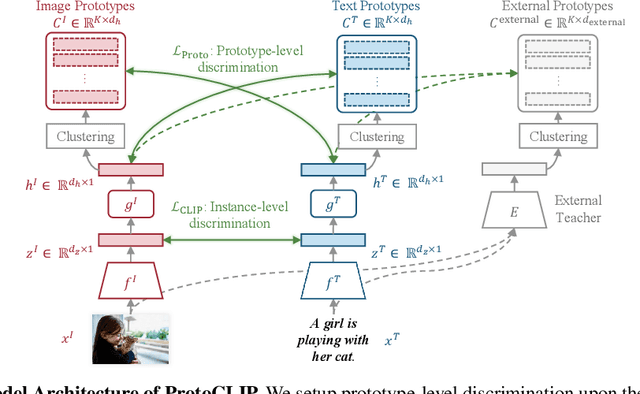
Contrastive Language Image Pretraining (CLIP) received widespread attention since its learned representations can be transferred well to various downstream tasks. During CLIP training, the InfoNCE objective aims to align positive image-text pairs and separate negative ones. In this paper, we show a representation grouping effect during this process: the InfoNCE objective indirectly groups semantically similar representations together via randomly emerged within-modal anchors. We introduce Prototypical Contrastive Language Image Pretraining (ProtoCLIP) to enhance such grouping by boosting its efficiency and increasing its robustness against modality gap. Specifically, ProtoCLIP sets up prototype-level discrimination between image and text spaces, which efficiently transfers higher-level structural knowledge. We further propose Prototypical Back Translation (PBT) to decouple representation grouping from representation alignment, resulting in effective learning of meaningful representations under large modality gap. PBT also enables us to introduce additional external teachers with richer prior knowledge. ProtoCLIP is trained with an online episodic training strategy, which makes it can be scaled up to unlimited amounts of data. Combining the above novel designs, we train our ProtoCLIP on Conceptual Captions and achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement. Codes are available at https://github.com/megvii-research/protoclip.
General Instance Distillation for Object Detection
Mar 03, 2021
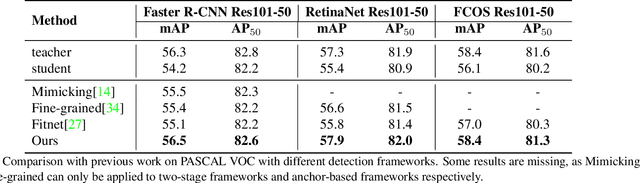
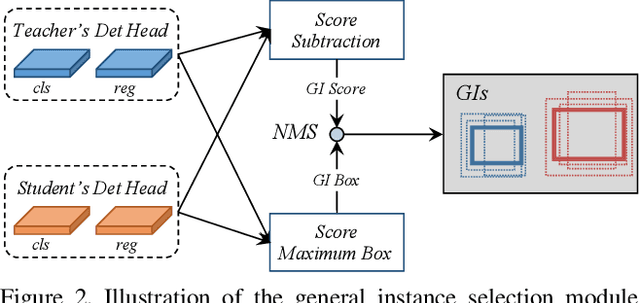
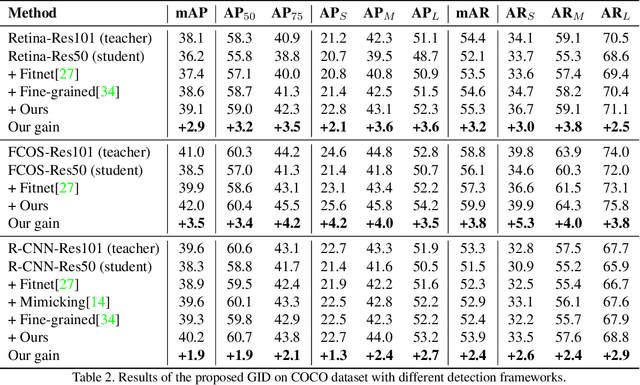
In recent years, knowledge distillation has been proved to be an effective solution for model compression. This approach can make lightweight student models acquire the knowledge extracted from cumbersome teacher models. However, previous distillation methods of detection have weak generalization for different detection frameworks and rely heavily on ground truth (GT), ignoring the valuable relation information between instances. Thus, we propose a novel distillation method for detection tasks based on discriminative instances without considering the positive or negative distinguished by GT, which is called general instance distillation (GID). Our approach contains a general instance selection module (GISM) to make full use of feature-based, relation-based and response-based knowledge for distillation. Extensive results demonstrate that the student model achieves significant AP improvement and even outperforms the teacher in various detection frameworks. Specifically, RetinaNet with ResNet-50 achieves 39.1% in mAP with GID on COCO dataset, which surpasses the baseline 36.2% by 2.9%, and even better than the ResNet-101 based teacher model with 38.1% AP.
Ansor : Generating High-Performance Tensor Programs for Deep Learning
Jun 15, 2020

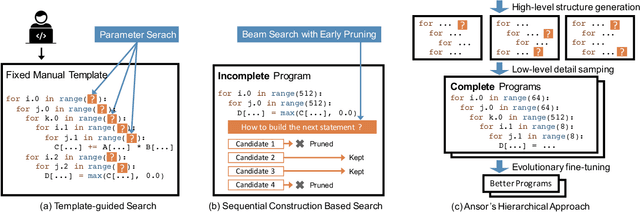
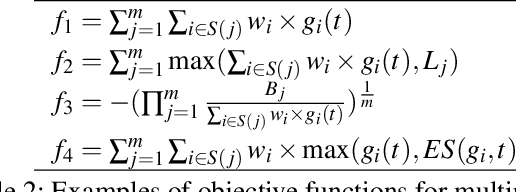
High-performance tensor programs are crucial to guarantee efficient execution of deep learning models. However, obtaining performant tensor programs for different operators on various hardware platforms is notoriously difficult. Currently, deep learning systems rely on vendor-provided kernel libraries or various search strategies to get performant tensor programs. These approaches either require significant engineering efforts in developing platform-specific optimization code or fall short in finding high-performance programs due to restricted search space and ineffective exploration strategy. We present Ansor, a tensor program generation framework for deep learning applications. Compared with existing search strategies, Ansor explores much more optimization combinations by sampling programs from a hierarchical representation of the search space. Ansor then fine-tunes the sampled programs with evolutionary search and a learned cost model to identify the best programs. Ansor can find high-performance programs that are outside the search space of existing state-of-the-art approaches. Besides, Ansor utilizes a scheduler to simultaneously optimize multiple subgraphs in a set of deep neural networks. Our evaluation shows that Ansor improves the execution performance of deep neural networks on the Intel CPU, ARM CPU, and NVIDIA GPU by up to $3.8\times$, $2.6\times$, and $1.7 \times$, respectively.