 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Energy for Invariant and Independent Decoding in Diffusion Language Models
Jun 08, 2026Diffusion Language Models (DLMs) enable parallel text generation by iteratively denoising a full sequence, offering attractive flexibility compared to auto-regressive (AR) decoding. However, existing methods fail to fully capture token relationships, leading to a performance gap relative to AR baselines, especially as the degree of parallelism increases. In this paper, we give a systematic analysis of the gap, identifying three key factors: (i) model capacity, (ii) dependency, and (iii) invariance. To address these issues, we first propose an invariant energy (Inv-E) together with an effective sampling-based estimator to handle the invariance issue. By further combining with the independent energy (Ind-E), we obtain a unified energy (Uni-E), that accounts for all these factors. Uni-E enjoys a unique advantage: it can be computed exactly without sampling-based partition estimation. Besides, Uni-E is model agnostic and can therefore be scaled to models of arbitrary size. We further prove that Uni-E can correct the distribution shift caused by dependency and invariance. Extensive experiments across Diffusion Language Models (DLMs) and Diffusion Large Language Models (DLLMs) demonstrate the effectiveness of the proposed Uni-E.
Visual Enhanced Depth Scaling for Multimodal Latent Reasoning
Apr 12, 2026Multimodal latent reasoning has emerged as a promising paradigm that replaces explicit Chain-of-Thought (CoT) decoding with implicit feature propagation, simultaneously enhancing representation informativeness and reducing inference latency. By analyzing token-level gradient dynamics during latent training, we reveal two critical observations: (1) visual tokens exhibit significantly higher and more volatile gradient norms than their textual counterparts due to inherent language bias, resulting in systematic visual under-optimization; and (2) semantically simple tokens converge rapidly, whereas complex tokens exhibit persistent gradient instability constrained by fixed architectural depths. To address these limitations, we propose a visual replay module and routing depth scaling to collaboratively enhance visual perception and refine complicated latents for deeper contextual reasoning. The former module leverages causal self-attention to estimate token saliency, reinforcing fine-grained grounding through spatially-coherent constraints. Complementarily, the latter mechanism adaptively allocates additional reasoning steps to complex tokens, enabling deeper contextual refinement. Guided by a curriculum strategy that progressively internalizes explicit CoT into compact latent representations, our framework achieves state-of-the-art performance across diverse benchmarks while delivering substantial inference speedups over explicit CoT baselines.
Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
Sep 18, 2025Spatio-temporal video grounding (STVG) aims at localizing the spatio-temporal tube of a video, as specified by the input text query. In this paper, we utilize multimodal large language models (MLLMs) to explore a zero-shot solution in STVG. We reveal two key insights about MLLMs: (1) MLLMs tend to dynamically assign special tokens, referred to as \textit{grounding tokens}, for grounding the text query; and (2) MLLMs often suffer from suboptimal grounding due to the inability to fully integrate the cues in the text query (\textit{e.g.}, attributes, actions) for inference. Based on these insights, we propose a MLLM-based zero-shot framework for STVG, which includes novel decomposed spatio-temporal highlighting (DSTH) and temporal-augmented assembling (TAS) strategies to unleash the reasoning ability of MLLMs. The DSTH strategy first decouples the original query into attribute and action sub-queries for inquiring the existence of the target both spatially and temporally. It then uses a novel logit-guided re-attention (LRA) module to learn latent variables as spatial and temporal prompts, by regularizing token predictions for each sub-query. These prompts highlight attribute and action cues, respectively, directing the model's attention to reliable spatial and temporal related visual regions. In addition, as the spatial grounding by the attribute sub-query should be temporally consistent, we introduce the TAS strategy to assemble the predictions using the original video frames and the temporal-augmented frames as inputs to help improve temporal consistency. We evaluate our method on various MLLMs, and show that it outperforms SOTA methods on three common STVG benchmarks. The code will be available at https://github.com/zaiquanyang/LLaVA_Next_STVG.
Boosting Weakly-Supervised Referring Image Segmentation via Progressive Comprehension
Oct 02, 2024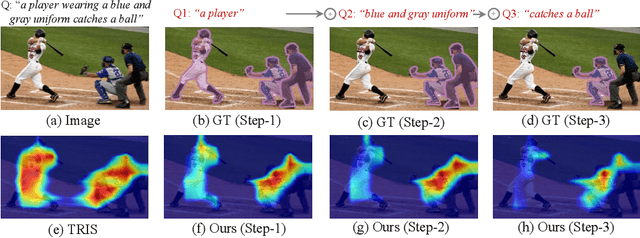
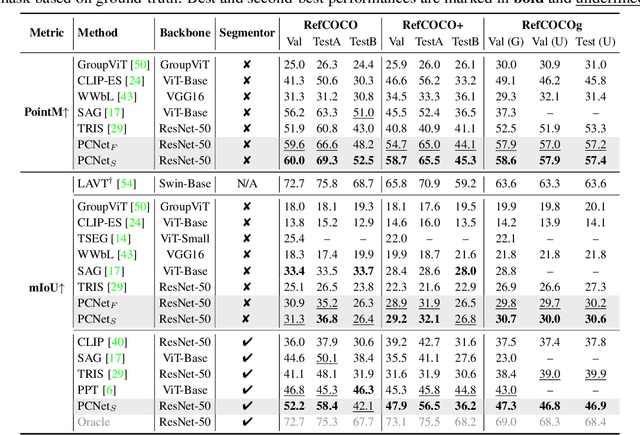
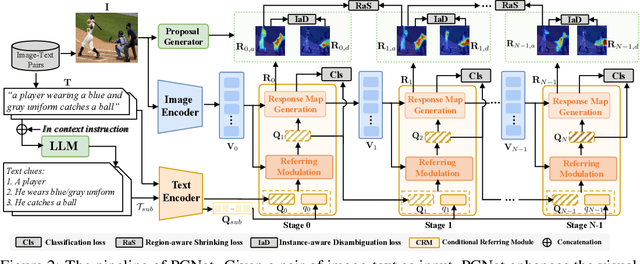
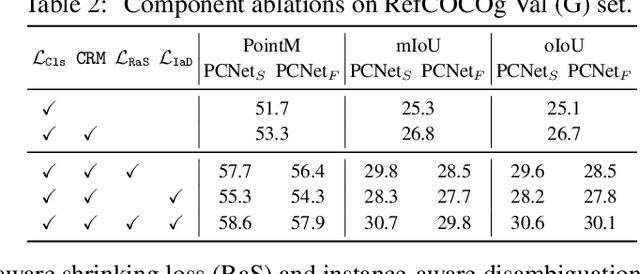
This paper explores the weakly-supervised referring image segmentation (WRIS) problem, and focuses on a challenging setup where target localization is learned directly from image-text pairs. We note that the input text description typically already contains detailed information on how to localize the target object, and we also observe that humans often follow a step-by-step comprehension process (\ie, progressively utilizing target-related attributes and relations as cues) to identify the target object. Hence, we propose a novel Progressive Comprehension Network (PCNet) to leverage target-related textual cues from the input description for progressively localizing the target object. Specifically, we first use a Large Language Model (LLM) to decompose the input text description into short phrases. These short phrases are taken as target-related cues and fed into a Conditional Referring Module (CRM) in multiple stages, to allow updating the referring text embedding and enhance the response map for target localization in a multi-stage manner. Based on the CRM, we then propose a Region-aware Shrinking (RaS) loss to constrain the visual localization to be conducted progressively in a coarse-to-fine manner across different stages. Finally, we introduce an Instance-aware Disambiguation (IaD) loss to suppress instance localization ambiguity by differentiating overlapping response maps generated by different referring texts on the same image. Extensive experiments show that our method outperforms SOTA methods on three common benchmarks.
Learning Prototype via Placeholder for Zero-shot Recognition
Jul 29, 2022Zero-shot learning (ZSL) aims to recognize unseen classes by exploiting semantic descriptions shared between seen classes and unseen classes. Current methods show that it is effective to learn visual-semantic alignment by projecting semantic embeddings into the visual space as class prototypes. However, such a projection function is only concerned with seen classes. When applied to unseen classes, the prototypes often perform suboptimally due to domain shift. In this paper, we propose to learn prototypes via placeholders, termed LPL, to eliminate the domain shift between seen and unseen classes. Specifically, we combine seen classes to hallucinate new classes which play as placeholders of the unseen classes in the visual and semantic space. Placed between seen classes, the placeholders encourage prototypes of seen classes to be highly dispersed. And more space is spared for the insertion of well-separated unseen ones. Empirically, well-separated prototypes help counteract visual-semantic misalignment caused by domain shift. Furthermore, we exploit a novel semantic-oriented fine-tuning to guarantee the semantic reliability of placeholders. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of LPL over the state-of-the-art methods. Code is available at https://github.com/zaiquanyang/LPL.
Prototypical Contrastive Language Image Pretraining
Jun 22, 2022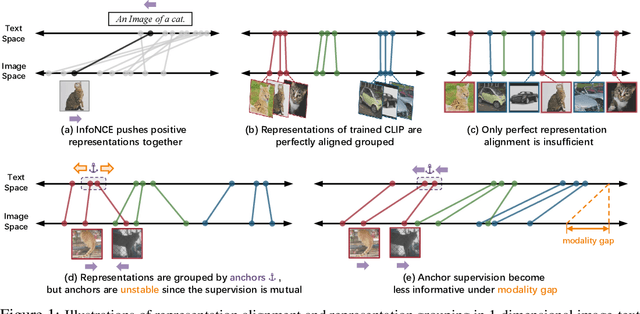
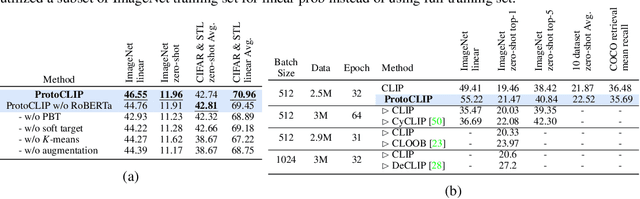

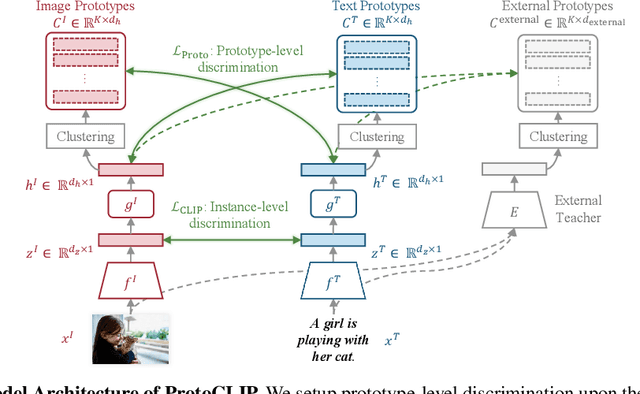
Contrastive Language Image Pretraining (CLIP) received widespread attention since its learned representations can be transferred well to various downstream tasks. During CLIP training, the InfoNCE objective aims to align positive image-text pairs and separate negative ones. In this paper, we show a representation grouping effect during this process: the InfoNCE objective indirectly groups semantically similar representations together via randomly emerged within-modal anchors. We introduce Prototypical Contrastive Language Image Pretraining (ProtoCLIP) to enhance such grouping by boosting its efficiency and increasing its robustness against modality gap. Specifically, ProtoCLIP sets up prototype-level discrimination between image and text spaces, which efficiently transfers higher-level structural knowledge. We further propose Prototypical Back Translation (PBT) to decouple representation grouping from representation alignment, resulting in effective learning of meaningful representations under large modality gap. PBT also enables us to introduce additional external teachers with richer prior knowledge. ProtoCLIP is trained with an online episodic training strategy, which makes it can be scaled up to unlimited amounts of data. Combining the above novel designs, we train our ProtoCLIP on Conceptual Captions and achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement. Codes are available at https://github.com/megvii-research/protoclip.