 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
Sep 18, 2025Spatio-temporal video grounding (STVG) aims at localizing the spatio-temporal tube of a video, as specified by the input text query. In this paper, we utilize multimodal large language models (MLLMs) to explore a zero-shot solution in STVG. We reveal two key insights about MLLMs: (1) MLLMs tend to dynamically assign special tokens, referred to as \textit{grounding tokens}, for grounding the text query; and (2) MLLMs often suffer from suboptimal grounding due to the inability to fully integrate the cues in the text query (\textit{e.g.}, attributes, actions) for inference. Based on these insights, we propose a MLLM-based zero-shot framework for STVG, which includes novel decomposed spatio-temporal highlighting (DSTH) and temporal-augmented assembling (TAS) strategies to unleash the reasoning ability of MLLMs. The DSTH strategy first decouples the original query into attribute and action sub-queries for inquiring the existence of the target both spatially and temporally. It then uses a novel logit-guided re-attention (LRA) module to learn latent variables as spatial and temporal prompts, by regularizing token predictions for each sub-query. These prompts highlight attribute and action cues, respectively, directing the model's attention to reliable spatial and temporal related visual regions. In addition, as the spatial grounding by the attribute sub-query should be temporally consistent, we introduce the TAS strategy to assemble the predictions using the original video frames and the temporal-augmented frames as inputs to help improve temporal consistency. We evaluate our method on various MLLMs, and show that it outperforms SOTA methods on three common STVG benchmarks. The code will be available at https://github.com/zaiquanyang/LLaVA_Next_STVG.
StyleSculptor: Zero-Shot Style-Controllable 3D Asset Generation with Texture-Geometry Dual Guidance
Sep 16, 2025Creating 3D assets that follow the texture and geometry style of existing ones is often desirable or even inevitable in practical applications like video gaming and virtual reality. While impressive progress has been made in generating 3D objects from text or images, creating style-controllable 3D assets remains a complex and challenging problem. In this work, we propose StyleSculptor, a novel training-free approach for generating style-guided 3D assets from a content image and one or more style images. Unlike previous works, StyleSculptor achieves style-guided 3D generation in a zero-shot manner, enabling fine-grained 3D style control that captures the texture, geometry, or both styles of user-provided style images. At the core of StyleSculptor is a novel Style Disentangled Attention (SD-Attn) module, which establishes a dynamic interaction between the input content image and style image for style-guided 3D asset generation via a cross-3D attention mechanism, enabling stable feature fusion and effective style-guided generation. To alleviate semantic content leakage, we also introduce a style-disentangled feature selection strategy within the SD-Attn module, which leverages the variance of 3D feature patches to disentangle style- and content-significant channels, allowing selective feature injection within the attention framework. With SD-Attn, the network can dynamically compute texture-, geometry-, or both-guided features to steer the 3D generation process. Built upon this, we further propose the Style Guided Control (SGC) mechanism, which enables exclusive geometry- or texture-only stylization, as well as adjustable style intensity control. Extensive experiments demonstrate that StyleSculptor outperforms existing baseline methods in producing high-fidelity 3D assets.
Boosting Weakly-Supervised Referring Image Segmentation via Progressive Comprehension
Oct 02, 2024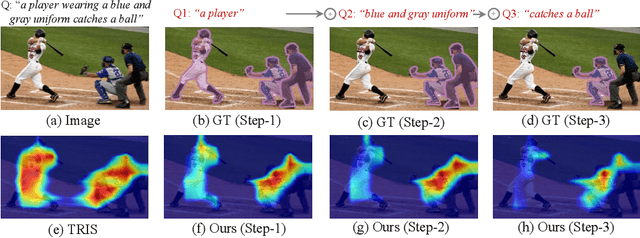
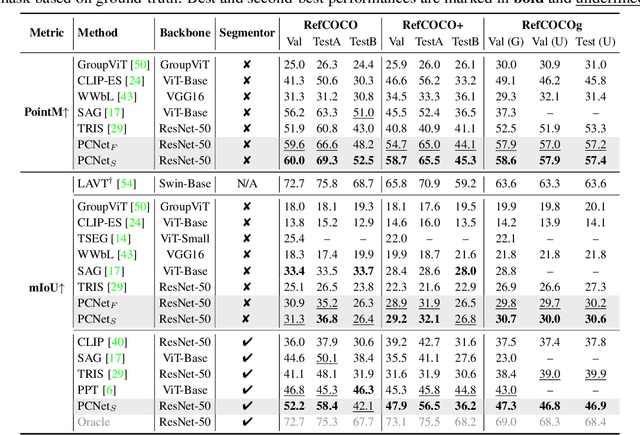
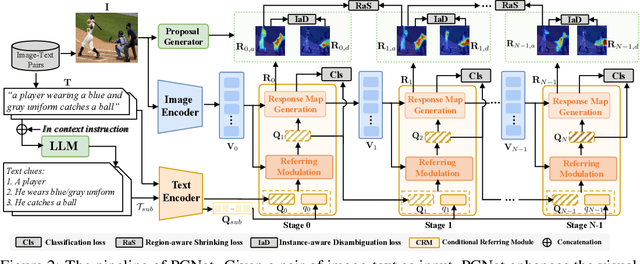
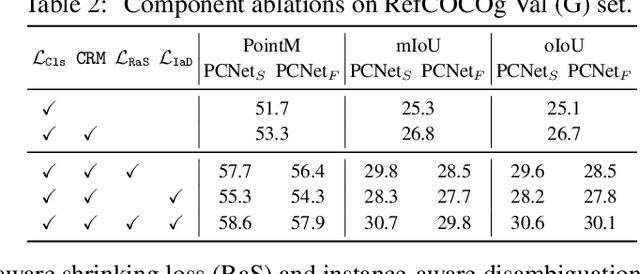
This paper explores the weakly-supervised referring image segmentation (WRIS) problem, and focuses on a challenging setup where target localization is learned directly from image-text pairs. We note that the input text description typically already contains detailed information on how to localize the target object, and we also observe that humans often follow a step-by-step comprehension process (\ie, progressively utilizing target-related attributes and relations as cues) to identify the target object. Hence, we propose a novel Progressive Comprehension Network (PCNet) to leverage target-related textual cues from the input description for progressively localizing the target object. Specifically, we first use a Large Language Model (LLM) to decompose the input text description into short phrases. These short phrases are taken as target-related cues and fed into a Conditional Referring Module (CRM) in multiple stages, to allow updating the referring text embedding and enhance the response map for target localization in a multi-stage manner. Based on the CRM, we then propose a Region-aware Shrinking (RaS) loss to constrain the visual localization to be conducted progressively in a coarse-to-fine manner across different stages. Finally, we introduce an Instance-aware Disambiguation (IaD) loss to suppress instance localization ambiguity by differentiating overlapping response maps generated by different referring texts on the same image. Extensive experiments show that our method outperforms SOTA methods on three common benchmarks.
Phidias: A Generative Model for Creating 3D Content from Text, Image, and 3D Conditions with Reference-Augmented Diffusion
Sep 17, 2024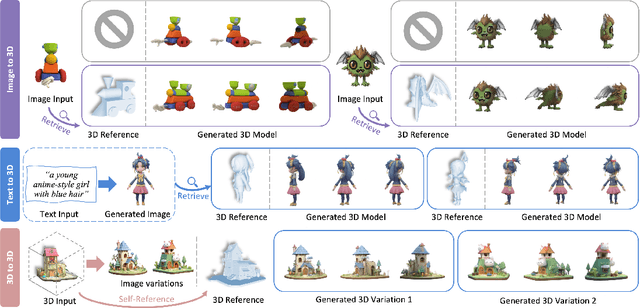
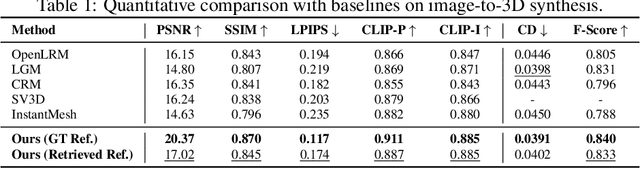
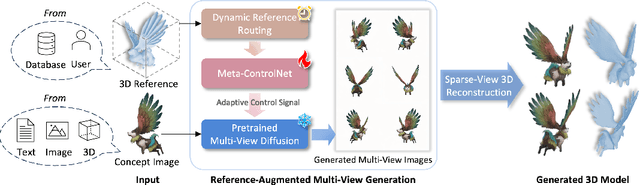
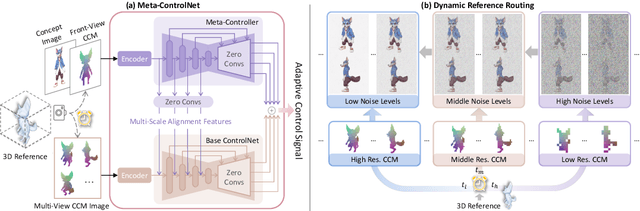
In 3D modeling, designers often use an existing 3D model as a reference to create new ones. This practice has inspired the development of Phidias, a novel generative model that uses diffusion for reference-augmented 3D generation. Given an image, our method leverages a retrieved or user-provided 3D reference model to guide the generation process, thereby enhancing the generation quality, generalization ability, and controllability. Our model integrates three key components: 1) meta-ControlNet that dynamically modulates the conditioning strength, 2) dynamic reference routing that mitigates misalignment between the input image and 3D reference, and 3) self-reference augmentations that enable self-supervised training with a progressive curriculum. Collectively, these designs result in a clear improvement over existing methods. Phidias establishes a unified framework for 3D generation using text, image, and 3D conditions with versatile applications.
ThemeStation: Generating Theme-Aware 3D Assets from Few Exemplars
Mar 22, 2024Real-world applications often require a large gallery of 3D assets that share a consistent theme. While remarkable advances have been made in general 3D content creation from text or image, synthesizing customized 3D assets following the shared theme of input 3D exemplars remains an open and challenging problem. In this work, we present ThemeStation, a novel approach for theme-aware 3D-to-3D generation. ThemeStation synthesizes customized 3D assets based on given few exemplars with two goals: 1) unity for generating 3D assets that thematically align with the given exemplars and 2) diversity for generating 3D assets with a high degree of variations. To this end, we design a two-stage framework that draws a concept image first, followed by a reference-informed 3D modeling stage. We propose a novel dual score distillation (DSD) loss to jointly leverage priors from both the input exemplars and the synthesized concept image. Extensive experiments and user studies confirm that ThemeStation surpasses prior works in producing diverse theme-aware 3D models with impressive quality. ThemeStation also enables various applications such as controllable 3D-to-3D generation.
Referring Image Segmentation Using Text Supervision
Aug 28, 2023
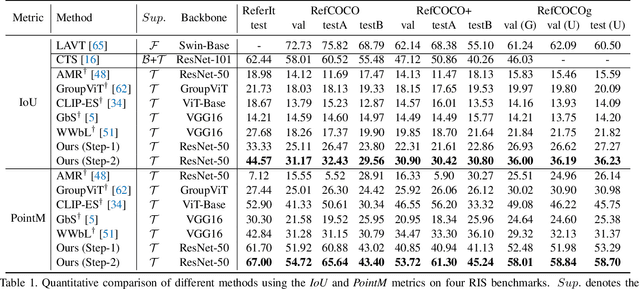
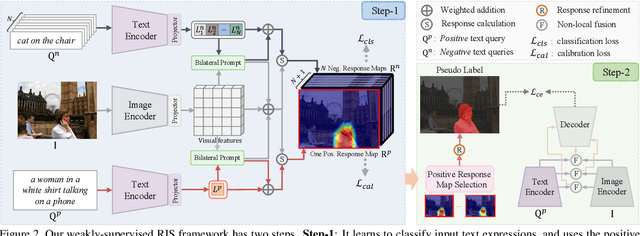

Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
Language-based Photo Color Adjustment for Graphic Designs
Aug 06, 2023Adjusting the photo color to associate with some design elements is an essential way for a graphic design to effectively deliver its message and make it aesthetically pleasing. However, existing tools and previous works face a dilemma between the ease of use and level of expressiveness. To this end, we introduce an interactive language-based approach for photo recoloring, which provides an intuitive system that can assist both experts and novices on graphic design. Given a graphic design containing a photo that needs to be recolored, our model can predict the source colors and the target regions, and then recolor the target regions with the source colors based on the given language-based instruction. The multi-granularity of the instruction allows diverse user intentions. The proposed novel task faces several unique challenges, including: 1) color accuracy for recoloring with exactly the same color from the target design element as specified by the user; 2) multi-granularity instructions for parsing instructions correctly to generate a specific result or multiple plausible ones; and 3) locality for recoloring in semantically meaningful local regions to preserve original image semantics. To address these challenges, we propose a model called LangRecol with two main components: the language-based source color prediction module and the semantic-palette-based photo recoloring module. We also introduce an approach for generating a synthetic graphic design dataset with instructions to enable model training. We evaluate our model via extensive experiments and user studies. We also discuss several practical applications, showing the effectiveness and practicality of our approach. Code and data for this paper are at: https://zhenwwang.github.io/langrecol.