 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Adaptive Pseudo-Label Filtering for Semi-Supervised Learning
Sep 18, 2023Recent semi-supervised learning (SSL) methods typically include a filtering strategy to improve the quality of pseudo labels. However, these filtering strategies are usually hand-crafted and do not change as the model is updated, resulting in a lot of correct pseudo labels being discarded and incorrect pseudo labels being selected during the training process. In this work, we observe that the distribution gap between the confidence values of correct and incorrect pseudo labels emerges at the very beginning of the training, which can be utilized to filter pseudo labels. Based on this observation, we propose a Self-Adaptive Pseudo-Label Filter (SPF), which automatically filters noise in pseudo labels in accordance with model evolvement by modeling the confidence distribution throughout the training process. Specifically, with an online mixture model, we weight each pseudo-labeled sample by the posterior of it being correct, which takes into consideration the confidence distribution at that time. Unlike previous handcrafted filters, our SPF evolves together with the deep neural network without manual tuning. Extensive experiments demonstrate that incorporating SPF into the existing SSL methods can help improve the performance of SSL, especially when the labeled data is extremely scarce.
Referring Image Segmentation Using Text Supervision
Aug 28, 2023
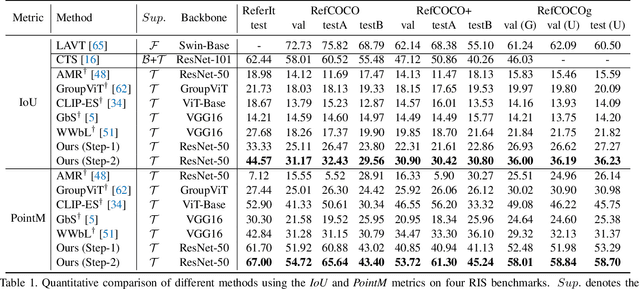
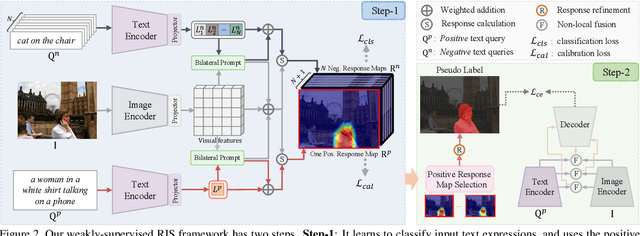

Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
BiFormer: Vision Transformer with Bi-Level Routing Attention
Mar 15, 2023



As the core building block of vision transformers, attention is a powerful tool to capture long-range dependency. However, such power comes at a cost: it incurs a huge computation burden and heavy memory footprint as pairwise token interaction across all spatial locations is computed. A series of works attempt to alleviate this problem by introducing handcrafted and content-agnostic sparsity into attention, such as restricting the attention operation to be inside local windows, axial stripes, or dilated windows. In contrast to these approaches, we propose a novel dynamic sparse attention via bi-level routing to enable a more flexible allocation of computations with content awareness. Specifically, for a query, irrelevant key-value pairs are first filtered out at a coarse region level, and then fine-grained token-to-token attention is applied in the union of remaining candidate regions (\ie, routed regions). We provide a simple yet effective implementation of the proposed bi-level routing attention, which utilizes the sparsity to save both computation and memory while involving only GPU-friendly dense matrix multiplications. Built with the proposed bi-level routing attention, a new general vision transformer, named BiFormer, is then presented. As BiFormer attends to a small subset of relevant tokens in a \textbf{query adaptive} manner without distraction from other irrelevant ones, it enjoys both good performance and high computational efficiency, especially in dense prediction tasks. Empirical results across several computer vision tasks such as image classification, object detection, and semantic segmentation verify the effectiveness of our design. Code is available at \url{https://github.com/rayleizhu/BiFormer}.
Laplacian Denoising Autoencoder
Mar 30, 2020
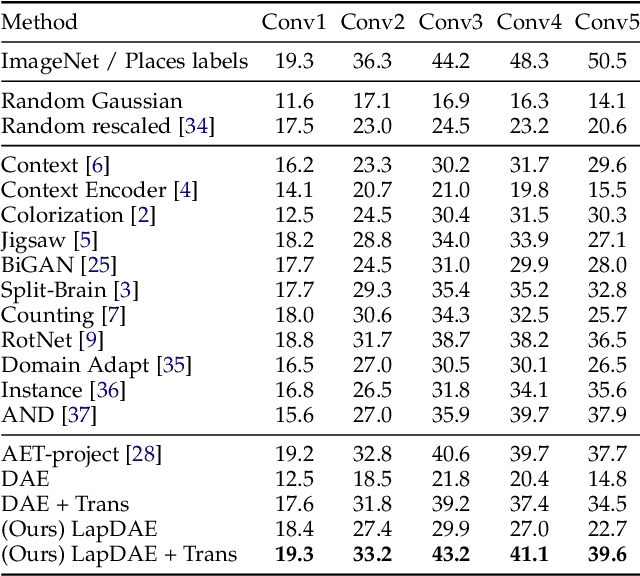

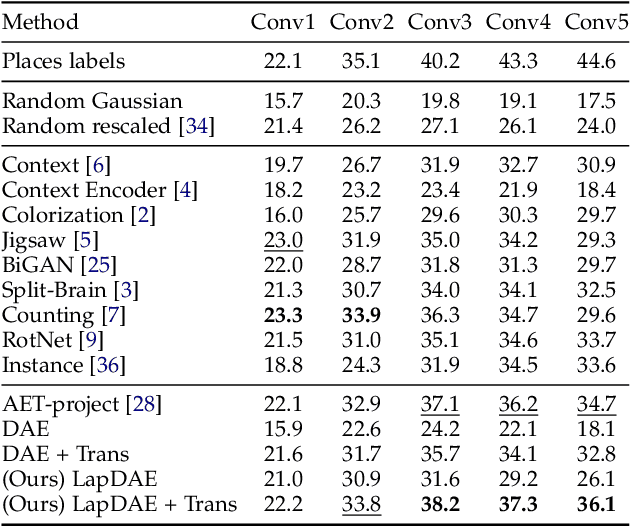
While deep neural networks have been shown to perform remarkably well in many machine learning tasks, labeling a large amount of ground truth data for supervised training is usually very costly to scale. Therefore, learning robust representations with unlabeled data is critical in relieving human effort and vital for many downstream tasks. Recent advances in unsupervised and self-supervised learning approaches for visual data have benefited greatly from domain knowledge. Here we are interested in a more generic unsupervised learning framework that can be easily generalized to other domains. In this paper, we propose to learn data representations with a novel type of denoising autoencoder, where the noisy input data is generated by corrupting latent clean data in the gradient domain. This can be naturally generalized to span multiple scales with a Laplacian pyramid representation of the input data. In this way, the agent learns more robust representations that exploit the underlying data structures across multiple scales. Experiments on several visual benchmarks demonstrate that better representations can be learned with the proposed approach, compared to its counterpart with single-scale corruption and other approaches. Furthermore, we also demonstrate that the learned representations perform well when transferring to other downstream vision tasks.
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset
Apr 02, 2019


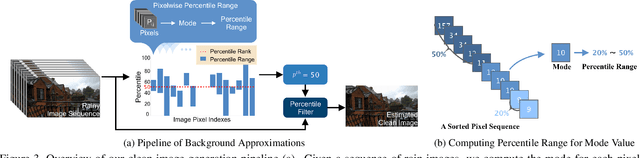
Removing rain streaks from a single image has been drawing considerable attention as rain streaks can severely degrade the image quality and affect the performance of existing outdoor vision tasks. While recent CNN-based derainers have reported promising performances, deraining remains an open problem for two reasons. First, existing synthesized rain datasets have only limited realism, in terms of modeling real rain characteristics such as rain shape, direction and intensity. Second, there are no public benchmarks for quantitative comparisons on real rain images, which makes the current evaluation less objective. The core challenge is that real world rain/clean image pairs cannot be captured at the same time. In this paper, we address the single image rain removal problem in two ways. First, we propose a semi-automatic method that incorporates temporal priors and human supervision to generate a high-quality clean image from each input sequence of real rain images. Using this method, we construct a large-scale dataset of $\sim$$29.5K$ rain/rain-free image pairs that covers a wide range of natural rain scenes. Second, to better cover the stochastic distribution of real rain streaks, we propose a novel SPatial Attentive Network (SPANet) to remove rain streaks in a local-to-global manner. Extensive experiments demonstrate that our network performs favorably against the state-of-the-art deraining methods.
Image Correction via Deep Reciprocating HDR Transformation
Apr 12, 2018
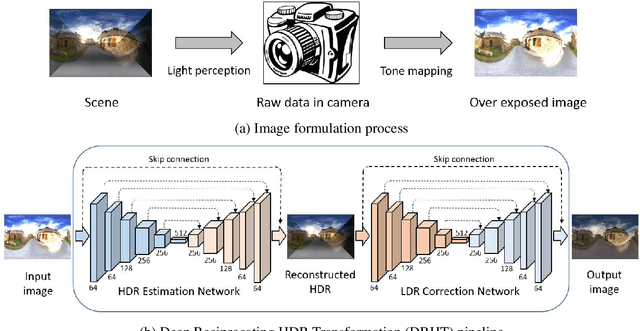

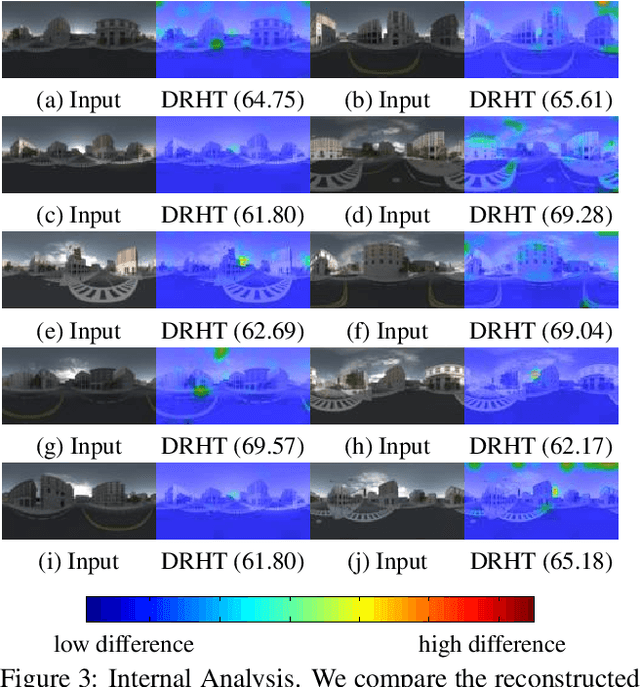
Image correction aims to adjust an input image into a visually pleasing one. Existing approaches are proposed mainly from the perspective of image pixel manipulation. They are not effective to recover the details in the under/over exposed regions. In this paper, we revisit the image formation procedure and notice that the missing details in these regions exist in the corresponding high dynamic range (HDR) data. These details are well perceived by the human eyes but diminished in the low dynamic range (LDR) domain because of the tone mapping process. Therefore, we formulate the image correction task as an HDR transformation process and propose a novel approach called Deep Reciprocating HDR Transformation (DRHT). Given an input LDR image, we first reconstruct the missing details in the HDR domain. We then perform tone mapping on the predicted HDR data to generate the output LDR image with the recovered details. To this end, we propose a united framework consisting of two CNNs for HDR reconstruction and tone mapping. They are integrated end-to-end for joint training and prediction. Experiments on the standard benchmarks demonstrate that the proposed method performs favorably against state-of-the-art image correction methods.
VITAL: VIsual Tracking via Adversarial Learning
Apr 12, 2018
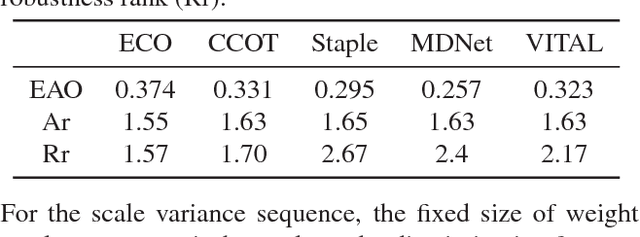

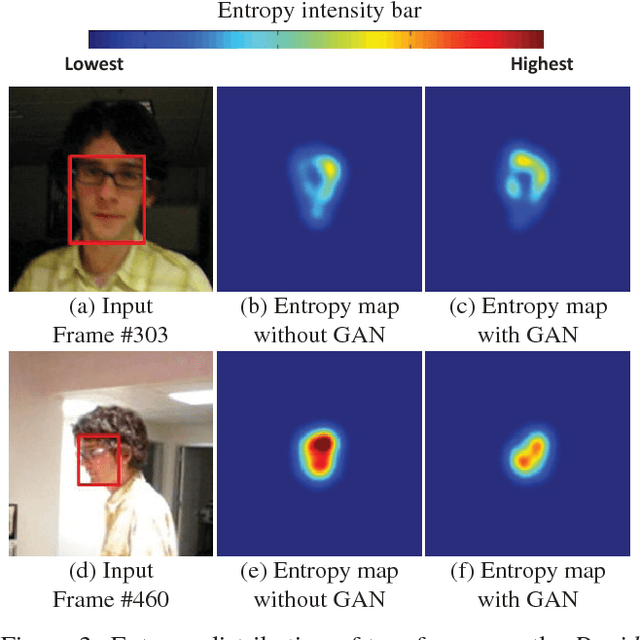
The tracking-by-detection framework consists of two stages, i.e., drawing samples around the target object in the first stage and classifying each sample as the target object or as background in the second stage. The performance of existing trackers using deep classification networks is limited by two aspects. First, the positive samples in each frame are highly spatially overlapped, and they fail to capture rich appearance variations. Second, there exists extreme class imbalance between positive and negative samples. This paper presents the VITAL algorithm to address these two problems via adversarial learning. To augment positive samples, we use a generative network to randomly generate masks, which are applied to adaptively dropout input features to capture a variety of appearance changes. With the use of adversarial learning, our network identifies the mask that maintains the most robust features of the target objects over a long temporal span. In addition, to handle the issue of class imbalance, we propose a high-order cost sensitive loss to decrease the effect of easy negative samples to facilitate training the classification network. Extensive experiments on benchmark datasets demonstrate that the proposed tracker performs favorably against state-of-the-art approaches.
CREST: Convolutional Residual Learning for Visual Tracking
Aug 01, 2017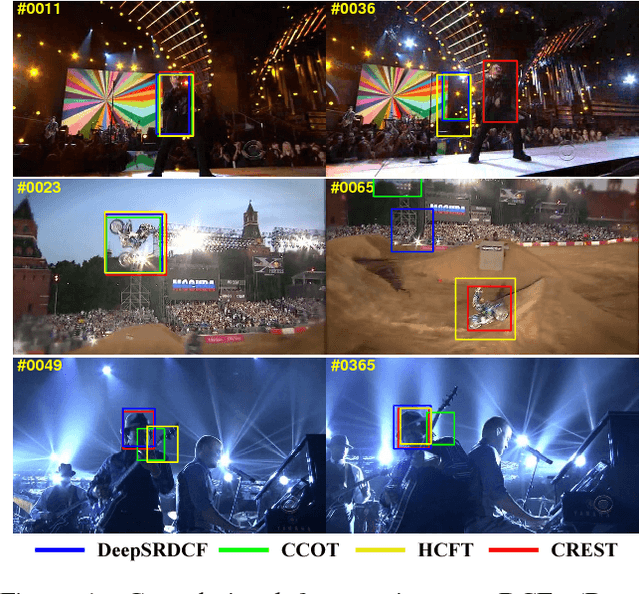
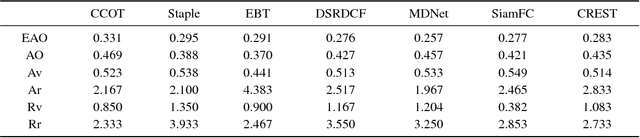
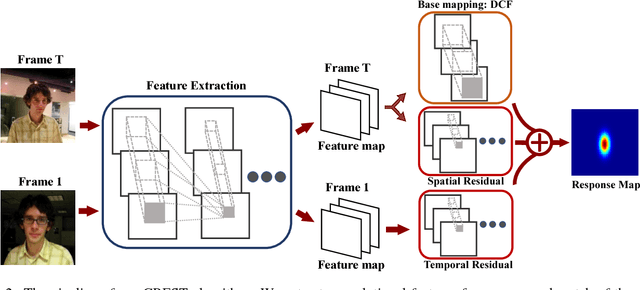
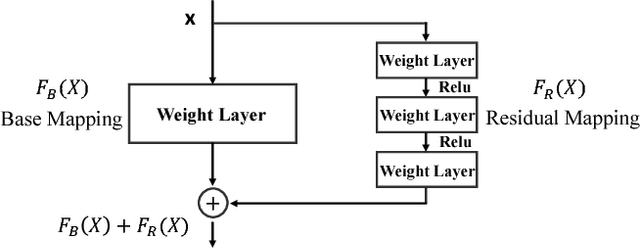
Discriminative correlation filters (DCFs) have been shown to perform superiorly in visual tracking. They only need a small set of training samples from the initial frame to generate an appearance model. However, existing DCFs learn the filters separately from feature extraction, and update these filters using a moving average operation with an empirical weight. These DCF trackers hardly benefit from the end-to-end training. In this paper, we propose the CREST algorithm to reformulate DCFs as a one-layer convolutional neural network. Our method integrates feature extraction, response map generation as well as model update into the neural networks for an end-to-end training. To reduce model degradation during online update, we apply residual learning to take appearance changes into account. Extensive experiments on the benchmark datasets demonstrate that our CREST tracker performs favorably against state-of-the-art trackers.
Learning Fully Convolutional Networks for Iterative Non-blind Deconvolution
Nov 20, 2016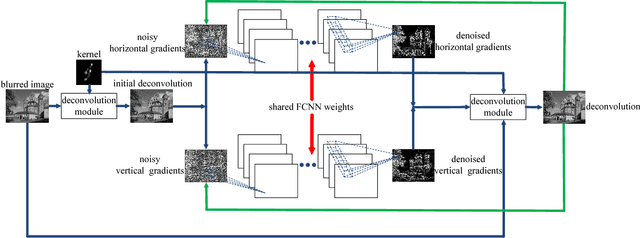

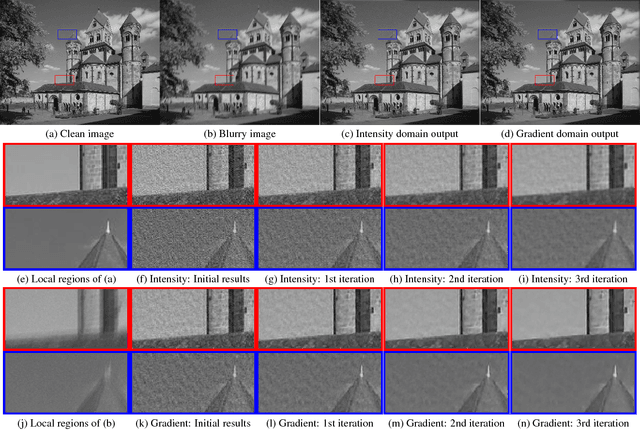
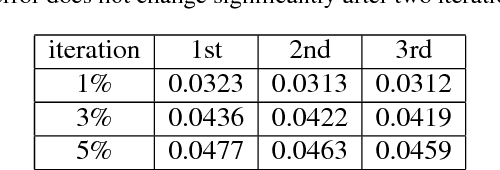
In this paper, we propose a fully convolutional networks for iterative non-blind deconvolution We decompose the non-blind deconvolution problem into image denoising and image deconvolution. We train a FCNN to remove noises in the gradient domain and use the learned gradients to guide the image deconvolution step. In contrast to the existing deep neural network based methods, we iteratively deconvolve the blurred images in a multi-stage framework. The proposed method is able to learn an adaptive image prior, which keeps both local (details) and global (structures) information. Both quantitative and qualitative evaluations on benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of quality and speed.