 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatastrophic Overfitting: A Potential Blessing in Disguise
Feb 28, 2024Fast Adversarial Training (FAT) has gained increasing attention within the research community owing to its efficacy in improving adversarial robustness. Particularly noteworthy is the challenge posed by catastrophic overfitting (CO) in this field. Although existing FAT approaches have made strides in mitigating CO, the ascent of adversarial robustness occurs with a non-negligible decline in classification accuracy on clean samples. To tackle this issue, we initially employ the feature activation differences between clean and adversarial examples to analyze the underlying causes of CO. Intriguingly, our findings reveal that CO can be attributed to the feature coverage induced by a few specific pathways. By intentionally manipulating feature activation differences in these pathways with well-designed regularization terms, we can effectively mitigate and induce CO, providing further evidence for this observation. Notably, models trained stably with these terms exhibit superior performance compared to prior FAT work. On this basis, we harness CO to achieve `attack obfuscation', aiming to bolster model performance. Consequently, the models suffering from CO can attain optimal classification accuracy on both clean and adversarial data when adding random noise to inputs during evaluation. We also validate their robustness against transferred adversarial examples and the necessity of inducing CO to improve robustness. Hence, CO may not be a problem that has to be solved.
Separable Multi-Concept Erasure from Diffusion Models
Feb 03, 2024



Large-scale diffusion models, known for their impressive image generation capabilities, have raised concerns among researchers regarding social impacts, such as the imitation of copyrighted artistic styles. In response, existing approaches turn to machine unlearning techniques to eliminate unsafe concepts from pre-trained models. However, these methods compromise the generative performance and neglect the coupling among multi-concept erasures, as well as the concept restoration problem. To address these issues, we propose a Separable Multi-concept Eraser (SepME), which mainly includes two parts: the generation of concept-irrelevant representations and the weight decoupling. The former aims to avoid unlearning substantial information that is irrelevant to forgotten concepts. The latter separates optimizable model weights, making each weight increment correspond to a specific concept erasure without affecting generative performance on other concepts. Specifically, the weight increment for erasing a specified concept is formulated as a linear combination of solutions calculated based on other known undesirable concepts. Extensive experiments indicate the efficacy of our approach in eliminating concepts, preserving model performance, and offering flexibility in the erasure or recovery of various concepts.
EipFormer: Emphasizing Instance Positions in 3D Instance Segmentation
Dec 09, 2023



3D instance segmentation plays a crucial role in comprehending 3D scenes. Despite recent advancements in this field, existing approaches exhibit certain limitations. These methods often rely on fixed instance positions obtained from sampled representative points in vast 3D point clouds, using center prediction or farthest point sampling. However, these selected positions may deviate from actual instance centers, posing challenges in precisely grouping instances. Moreover, the common practice of grouping candidate instances from a single type of coordinates introduces difficulties in identifying neighboring instances or incorporating edge points. To tackle these issues, we present a novel Transformer-based architecture, EipFormer, which comprises progressive aggregation and dual position embedding. The progressive aggregation mechanism leverages instance positions to refine instance proposals. It enhances the initial instance positions through weighted farthest point sampling and further refines the instance positions and proposals using aggregation averaging and center matching. Additionally, dual position embedding superposes the original and centralized position embeddings, thereby enhancing the model performance in distinguishing adjacent instances. Extensive experiments on popular datasets demonstrate that EipFormer achieves superior or comparable performance compared to state-of-the-art approaches.
Referring Image Segmentation Using Text Supervision
Aug 28, 2023
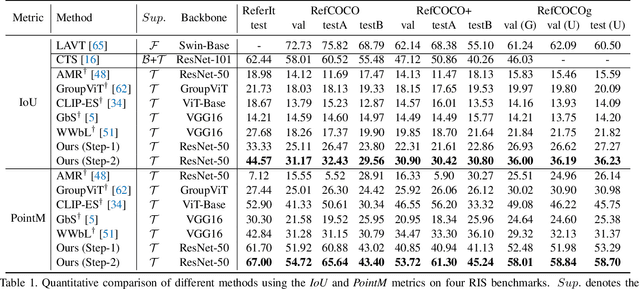
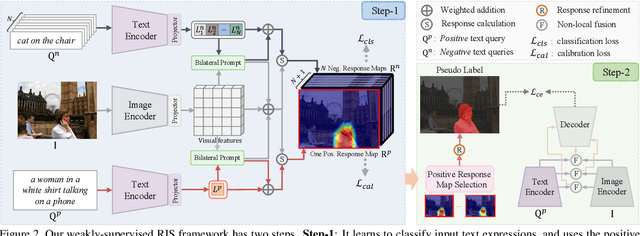

Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
Fast Adversarial Training with Smooth Convergence
Aug 24, 2023Fast adversarial training (FAT) is beneficial for improving the adversarial robustness of neural networks. However, previous FAT work has encountered a significant issue known as catastrophic overfitting when dealing with large perturbation budgets, \ie the adversarial robustness of models declines to near zero during training. To address this, we analyze the training process of prior FAT work and observe that catastrophic overfitting is accompanied by the appearance of loss convergence outliers. Therefore, we argue a moderately smooth loss convergence process will be a stable FAT process that solves catastrophic overfitting. To obtain a smooth loss convergence process, we propose a novel oscillatory constraint (dubbed ConvergeSmooth) to limit the loss difference between adjacent epochs. The convergence stride of ConvergeSmooth is introduced to balance convergence and smoothing. Likewise, we design weight centralization without introducing additional hyperparameters other than the loss balance coefficient. Our proposed methods are attack-agnostic and thus can improve the training stability of various FAT techniques. Extensive experiments on popular datasets show that the proposed methods efficiently avoid catastrophic overfitting and outperform all previous FAT methods. Code is available at \url{https://github.com/FAT-CS/ConvergeSmooth}.
Temporal Knowledge Graph Reasoning Triggered by Memories
Nov 03, 2021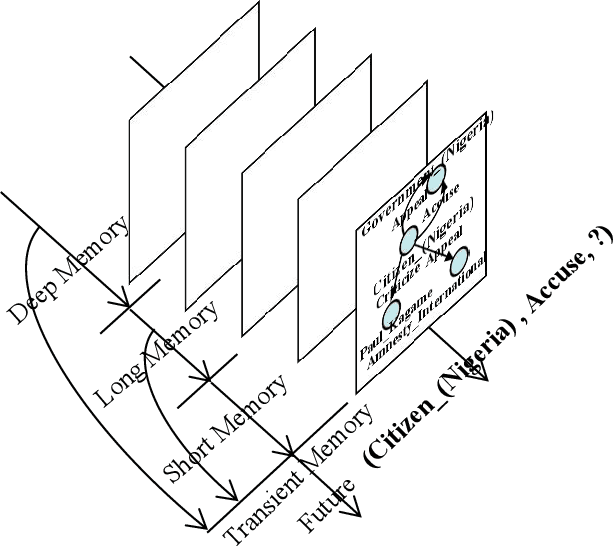
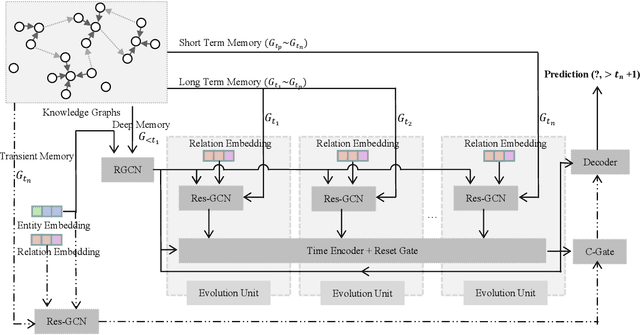
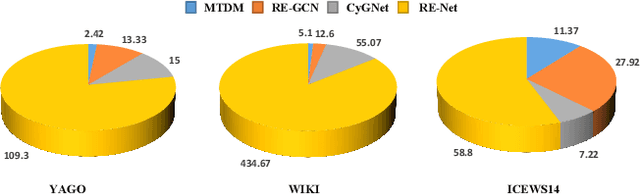
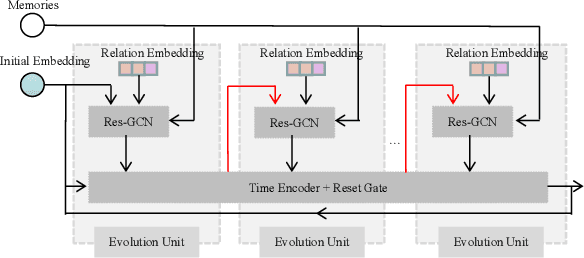
Inferring missing facts in temporal knowledge graphs is a critical task and has been widely explored. Extrapolation in temporal reasoning tasks is more challenging and gradually attracts the attention of researchers since no direct history facts for prediction. Previous works attempted to apply evolutionary representation learning to solve the extrapolation problem. However, these techniques do not explicitly leverage various time-aware attribute representations, i.e. the reasoning performance is significantly affected by the history length. To alleviate the time dependence when reasoning future missing facts, we propose a memory-triggered decision-making (MTDM) network, which incorporates transient memories, long-short-term memories, and deep memories. Specifically, the transient learning network considers transient memories as a static knowledge graph, and the time-aware recurrent evolution network learns representations through a sequence of recurrent evolution units from long-short-term memories. Each evolution unit consists of a structural encoder to aggregate edge information, a time encoder with a gating unit to update attribute representations of entities. MTDM utilizes the crafted residual multi-relational aggregator as the structural encoder to solve the multi-hop coverage problem. We also introduce the dissolution learning constraint for better understanding the event dissolution process. Extensive experiments demonstrate the MTDM alleviates the history dependence and achieves state-of-the-art prediction performance. Moreover, compared with the most advanced baseline, MTDM shows a faster convergence speed and training speed.