 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Suffix Jailbreak attacks with Prefix-Shared KV-cache
Mar 12, 2026Suffix jailbreak attacks serve as a systematic method for red-teaming Large Language Models (LLMs) but suffer from prohibitive computational costs, as a large number of candidate suffixes need to be evaluated before identifying a jailbreak suffix. This paper presents Prefix-Shared KV Cache (PSKV), a plug-and-play inference optimization technique tailored for jailbreak suffix generation. Our method is motivated by a key observation that when performing suffix jailbreaking, while a large number of candidate prompts need to be evaluated, they share the same targeted harmful instruction as the prefix. Therefore, instead of performing redundant inference on the duplicated prefix, PSKV maintains a single KV cache for this prefix and shares it with every candidate prompt, enabling the parallel inference of diverse suffixes with minimal memory overhead. This design enables more aggressive batching strategies that would otherwise be limited by memory constraints. Extensive experiments on six widely used suffix attacks across five widely deployed LLMs demonstrate that PSKV reduces inference time by 40\% and peak memory usage by 50\%, while maintaining the original Attack Success Rate (ASR). The code has been submitted and will be released publicly.
MAGIC: A Co-Evolving Attacker-Defender Adversarial Game for Robust LLM Safety
Feb 02, 2026Ensuring robust safety alignment is crucial for Large Language Models (LLMs), yet existing defenses often lag behind evolving adversarial attacks due to their \textbf{reliance on static, pre-collected data distributions}. In this paper, we introduce \textbf{MAGIC}, a novel multi-turn multi-agent reinforcement learning framework that formulates LLM safety alignment as an adversarial asymmetric game. Specifically, an attacker agent learns to iteratively rewrite original queries into deceptive prompts, while a defender agent simultaneously optimizes its policy to recognize and refuse such inputs. This dynamic process triggers a \textbf{co-evolution}, where the attacker's ever-changing strategies continuously uncover long-tail vulnerabilities, driving the defender to generalize to unseen attack patterns. Remarkably, we observe that the attacker, endowed with initial reasoning ability, evolves \textbf{novel, previously unseen combinatorial strategies} through iterative RL training, underscoring our method's substantial potential. Theoretically, we provide insights into a more robust game equilibrium and derive safety guarantees. Extensive experiments validate our framework's effectiveness, demonstrating superior defense success rates without compromising the helpfulness of the model. Our code is available at https://github.com/BattleWen/MAGIC.
Attack-Resistant Watermarking for AIGC Image Forensics via Diffusion-based Semantic Deflection
Jan 10, 2026Protecting the copyright of user-generated AI images is an emerging challenge as AIGC becomes pervasive in creative workflows. Existing watermarking methods (1) remain vulnerable to real-world adversarial threats, often forced to trade off between defenses against spoofing and removal attacks; and (2) cannot support semantic-level tamper localization. We introduce PAI, a training-free inherent watermarking framework for AIGC copyright protection, plug-and-play with diffusion-based AIGC services. PAI simultaneously provides three key functionalities: robust ownership verification, attack detection, and semantic-level tampering localization. Unlike existing inherent watermark methods that only embed watermarks at noise initialization of diffusion models, we design a novel key-conditioned deflection mechanism that subtly steers the denoising trajectory according to the user key. Such trajectory-level coupling further strengthens the semantic entanglement of identity and content, thereby further enhancing robustness against real-world threats. Moreover, we also provide a theoretical analysis proving that only the valid key can pass verification. Experiments across 12 attack methods show that PAI achieves 98.43\% verification accuracy, improving over SOTA methods by 37.25\% on average, and retains strong tampering localization performance even against advanced AIGC edits. Our code is available at https://github.com/QingyuLiu/PAI.
DualBreach: Efficient Dual-Jailbreaking via Target-Driven Initialization and Multi-Target Optimization
Apr 21, 2025Recent research has focused on exploring the vulnerabilities of Large Language Models (LLMs), aiming to elicit harmful and/or sensitive content from LLMs. However, due to the insufficient research on dual-jailbreaking -- attacks targeting both LLMs and Guardrails, the effectiveness of existing attacks is limited when attempting to bypass safety-aligned LLMs shielded by guardrails. Therefore, in this paper, we propose DualBreach, a target-driven framework for dual-jailbreaking. DualBreach employs a Target-driven Initialization (TDI) strategy to dynamically construct initial prompts, combined with a Multi-Target Optimization (MTO) method that utilizes approximate gradients to jointly adapt the prompts across guardrails and LLMs, which can simultaneously save the number of queries and achieve a high dual-jailbreaking success rate. For black-box guardrails, DualBreach either employs a powerful open-sourced guardrail or imitates the target black-box guardrail by training a proxy model, to incorporate guardrails into the MTO process. We demonstrate the effectiveness of DualBreach in dual-jailbreaking scenarios through extensive evaluation on several widely-used datasets. Experimental results indicate that DualBreach outperforms state-of-the-art methods with fewer queries, achieving significantly higher success rates across all settings. More specifically, DualBreach achieves an average dual-jailbreaking success rate of 93.67% against GPT-4 with Llama-Guard-3 protection, whereas the best success rate achieved by other methods is 88.33%. Moreover, DualBreach only uses an average of 1.77 queries per successful dual-jailbreak, outperforming other state-of-the-art methods. For the purpose of defense, we propose an XGBoost-based ensemble defensive mechanism named EGuard, which integrates the strengths of multiple guardrails, demonstrating superior performance compared with Llama-Guard-3.
Nearly Optimal Differentially Private ReLU Regression
Mar 08, 2025In this paper, we investigate one of the most fundamental nonconvex learning problems, ReLU regression, in the Differential Privacy (DP) model. Previous studies on private ReLU regression heavily rely on stringent assumptions, such as constant bounded norms for feature vectors and labels. We relax these assumptions to a more standard setting, where data can be i.i.d. sampled from $O(1)$-sub-Gaussian distributions. We first show that when $\varepsilon = \tilde{O}(\sqrt{\frac{1}{N}})$ and there is some public data, it is possible to achieve an upper bound of $\Tilde{O}(\frac{d^2}{N^2 \varepsilon^2})$ for the excess population risk in $(\epsilon, \delta)$-DP, where $d$ is the dimension and $N$ is the number of data samples. Moreover, we relax the requirement of $\epsilon$ and public data by proposing and analyzing a one-pass mini-batch Generalized Linear Model Perceptron algorithm (DP-MBGLMtron). Additionally, using the tracing attack argument technique, we demonstrate that the minimax rate of the estimation error for $(\varepsilon, \delta)$-DP algorithms is lower bounded by $\Omega(\frac{d^2}{N^2 \varepsilon^2})$. This shows that DP-MBGLMtron achieves the optimal utility bound up to logarithmic factors. Experiments further support our theoretical results.
AdvAnchor: Enhancing Diffusion Model Unlearning with Adversarial Anchors
Dec 28, 2024Security concerns surrounding text-to-image diffusion models have driven researchers to unlearn inappropriate concepts through fine-tuning. Recent fine-tuning methods typically align the prediction distributions of unsafe prompts with those of predefined text anchors. However, these techniques exhibit a considerable performance trade-off between eliminating undesirable concepts and preserving other concepts. In this paper, we systematically analyze the impact of diverse text anchors on unlearning performance. Guided by this analysis, we propose AdvAnchor, a novel approach that generates adversarial anchors to alleviate the trade-off issue. These adversarial anchors are crafted to closely resemble the embeddings of undesirable concepts to maintain overall model performance, while selectively excluding defining attributes of these concepts for effective erasure. Extensive experiments demonstrate that AdvAnchor outperforms state-of-the-art methods. Our code is publicly available at https://anonymous.4open.science/r/AdvAnchor.
Faithful Interpretation for Graph Neural Networks
Oct 09, 2024Currently, attention mechanisms have garnered increasing attention in Graph Neural Networks (GNNs), such as Graph Attention Networks (GATs) and Graph Transformers (GTs). It is not only due to the commendable boost in performance they offer but also its capacity to provide a more lucid rationale for model behaviors, which are often viewed as inscrutable. However, Attention-based GNNs have demonstrated instability in interpretability when subjected to various sources of perturbations during both training and testing phases, including factors like additional edges or nodes. In this paper, we propose a solution to this problem by introducing a novel notion called Faithful Graph Attention-based Interpretation (FGAI). In particular, FGAI has four crucial properties regarding stability and sensitivity to interpretation and final output distribution. Built upon this notion, we propose an efficient methodology for obtaining FGAI, which can be viewed as an ad hoc modification to the canonical Attention-based GNNs. To validate our proposed solution, we introduce two novel metrics tailored for graph interpretation assessment. Experimental results demonstrate that FGAI exhibits superior stability and preserves the interpretability of attention under various forms of perturbations and randomness, which makes FGAI a more faithful and reliable explanation tool.
Pre-trained Encoder Inference: Revealing Upstream Encoders In Downstream Machine Learning Services
Aug 05, 2024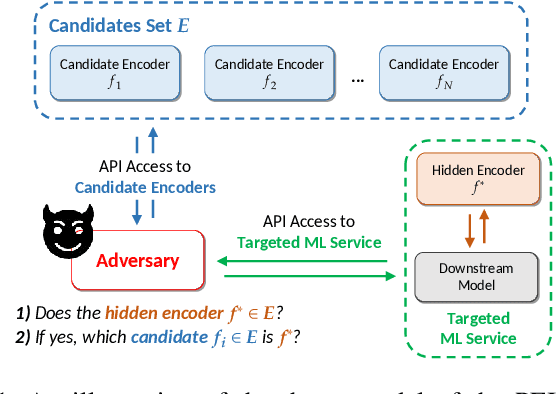

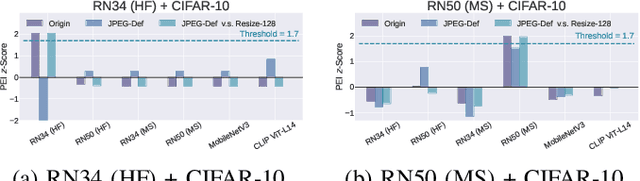
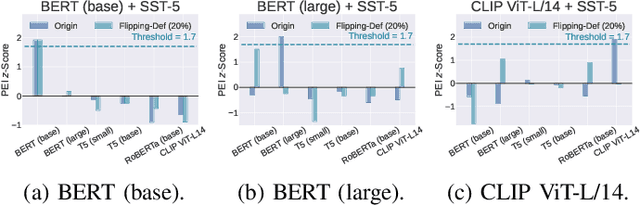
Though pre-trained encoders can be easily accessed online to build downstream machine learning (ML) services quickly, various attacks have been designed to compromise the security and privacy of these encoders. While most attacks target encoders on the upstream side, it remains unknown how an encoder could be threatened when deployed in a downstream ML service. This paper unveils a new vulnerability: the Pre-trained Encoder Inference (PEI) attack, which posts privacy threats toward encoders hidden behind downstream ML services. By only providing API accesses to a targeted downstream service and a set of candidate encoders, the PEI attack can infer which encoder is secretly used by the targeted service based on candidate ones. We evaluate the attack performance of PEI against real-world encoders on three downstream tasks: image classification, text classification, and text-to-image generation. Experiments show that the PEI attack succeeds in revealing the hidden encoder in most cases and seldom makes mistakes even when the hidden encoder is not in the candidate set. We also conducted a case study on one of the most recent vision-language models, LLaVA, to illustrate that the PEI attack is useful in assisting other ML attacks such as adversarial attacks. The code is available at https://github.com/fshp971/encoder-inference.
Poisoning with A Pill: Circumventing Detection in Federated Learning
Jul 22, 2024



Without direct access to the client's data, federated learning (FL) is well-known for its unique strength in data privacy protection among existing distributed machine learning techniques. However, its distributive and iterative nature makes FL inherently vulnerable to various poisoning attacks. To counteract these threats, extensive defenses have been proposed to filter out malicious clients, using various detection metrics. Based on our analysis of existing attacks and defenses, we find that there is a lack of attention to model redundancy. In neural networks, various model parameters contribute differently to the model's performance. However, existing attacks in FL manipulate all the model update parameters with the same strategy, making them easily detectable by common defenses. Meanwhile, the defenses also tend to analyze the overall statistical features of the entire model updates, leaving room for sophisticated attacks. Based on these observations, this paper proposes a generic and attack-agnostic augmentation approach designed to enhance the effectiveness and stealthiness of existing FL poisoning attacks against detection in FL, pointing out the inherent flaws of existing defenses and exposing the necessity of fine-grained FL security. Specifically, we employ a three-stage methodology that strategically constructs, generates, and injects poison (generated by existing attacks) into a pill (a tiny subnet with a novel structure) during the FL training, named as pill construction, pill poisoning, and pill injection accordingly. Extensive experimental results show that FL poisoning attacks enhanced by our method can bypass all the popular defenses, and can gain an up to 7x error rate increase, as well as on average a more than 2x error rate increase on both IID and non-IID data, in both cross-silo and cross-device FL systems.
Releasing Malevolence from Benevolence: The Menace of Benign Data on Machine Unlearning
Jul 06, 2024



Machine learning models trained on vast amounts of real or synthetic data often achieve outstanding predictive performance across various domains. However, this utility comes with increasing concerns about privacy, as the training data may include sensitive information. To address these concerns, machine unlearning has been proposed to erase specific data samples from models. While some unlearning techniques efficiently remove data at low costs, recent research highlights vulnerabilities where malicious users could request unlearning on manipulated data to compromise the model. Despite these attacks' effectiveness, perturbed data differs from original training data, failing hash verification. Existing attacks on machine unlearning also suffer from practical limitations and require substantial additional knowledge and resources. To fill the gaps in current unlearning attacks, we introduce the Unlearning Usability Attack. This model-agnostic, unlearning-agnostic, and budget-friendly attack distills data distribution information into a small set of benign data. These data are identified as benign by automatic poisoning detection tools due to their positive impact on model training. While benign for machine learning, unlearning these data significantly degrades model information. Our evaluation demonstrates that unlearning this benign data, comprising no more than 1% of the total training data, can reduce model accuracy by up to 50%. Furthermore, our findings show that well-prepared benign data poses challenges for recent unlearning techniques, as erasing these synthetic instances demands higher resources than regular data. These insights underscore the need for future research to reconsider "data poisoning" in the context of machine unlearning.