 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
SpecQuant: Spectral Decomposition and Adaptive Truncation for Ultra-Low-Bit LLMs Quantization
Nov 11, 2025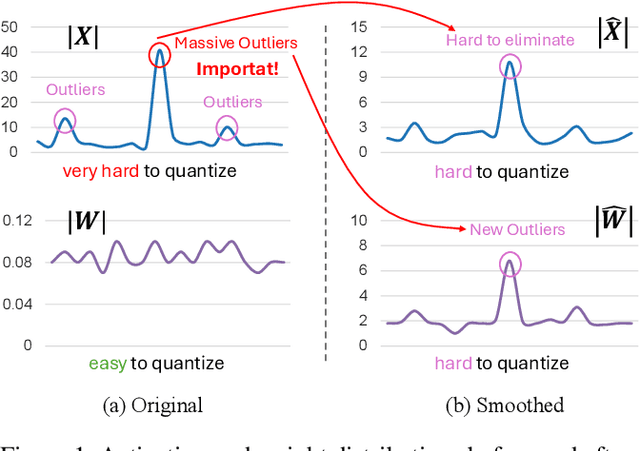
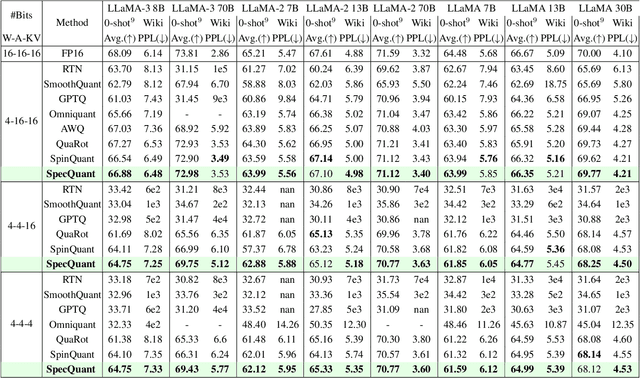
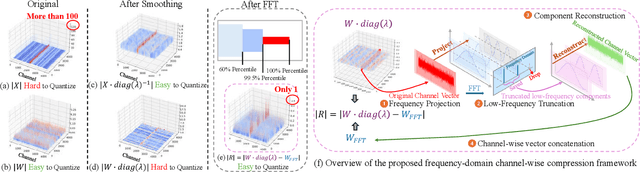
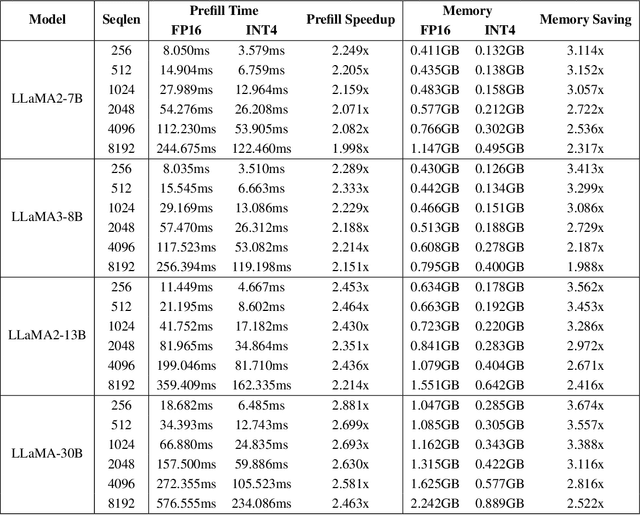
The emergence of accurate open large language models (LLMs) has sparked a push for advanced quantization techniques to enable efficient deployment on end-user devices. In this paper, we revisit the challenge of extreme LLM compression -- targeting ultra-low-bit quantization for both activations and weights -- from a Fourier frequency domain perspective. We propose SpecQuant, a two-stage framework that tackles activation outliers and cross-channel variance. In the first stage, activation outliers are smoothed and transferred into the weight matrix to simplify downstream quantization. In the second stage, we apply channel-wise low-frequency Fourier truncation to suppress high-frequency components while preserving essential signal energy, improving quantization robustness. Our method builds on the principle that most of the weight energy is concentrated in low-frequency components, which can be retained with minimal impact on model accuracy. To enable runtime adaptability, we introduce a lightweight truncation module during inference that adjusts truncation thresholds based on channel characteristics. On LLaMA-3 8B, SpecQuant achieves 4-bit quantization for both weights and activations, narrowing the zero-shot accuracy gap to only 1.5% compared to full precision, while delivering 2 times faster inference and 3times lower memory usage.
QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations
Nov 10, 2025Transformer-based models have revolutionized computer vision (CV) and natural language processing (NLP) by achieving state-of-the-art performance across a range of benchmarks. However, nonlinear operations in models significantly contribute to inference latency, presenting unique challenges for efficient hardware acceleration. To this end, we propose QUARK, a quantization-enabled FPGA acceleration framework that leverages common patterns in nonlinear operations to enable efficient circuit sharing, thereby reducing hardware resource requirements. QUARK targets all nonlinear operations within Transformer-based models, achieving high-performance approximation through a novel circuit-sharing design tailored to accelerate these operations. Our evaluation demonstrates that QUARK significantly reduces the computational overhead of nonlinear operators in mainstream Transformer architectures, achieving up to a 1.96 times end-to-end speedup over GPU implementations. Moreover, QUARK lowers the hardware overhead of nonlinear modules by more than 50% compared to prior approaches, all while maintaining high model accuracy -- and even substantially boosting accuracy under ultra-low-bit quantization.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025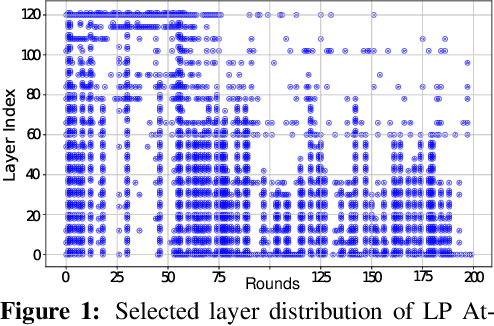



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
Dissecting the Impact of Mobile DVFS Governors on LLM Inference Performance and Energy Efficiency
Jul 02, 2025Large Language Models (LLMs) are increasingly being integrated into various applications and services running on billions of mobile devices. However, deploying LLMs on resource-limited mobile devices faces a significant challenge due to their high demand for computation, memory, and ultimately energy. While current LLM frameworks for mobile use three power-hungry components-CPU, GPU, and Memory-even when running primarily-GPU LLM models, optimized DVFS governors for CPU, GPU, and memory featured in modern mobile devices operate independently and are oblivious of each other. Motivated by the above observation, in this work, we first measure the energy-efficiency of a SOTA LLM framework consisting of various LLM models on mobile phones which showed the triplet mobile governors result in up to 40.4% longer prefilling and decoding latency compared to optimal combinations of CPU, GPU, and memory frequencies with the same energy consumption for sampled prefill and decode lengths. Second, we conduct an in-depth measurement study to uncover how the intricate interplay (or lack of) among the mobile governors cause the above inefficiency in LLM inference. Finally, based on these insights, we design FUSE - a unified energy-aware governor for optimizing the energy efficiency of LLM inference on mobile devices. Our evaluation using a ShareGPT dataset shows FUSE reduces the time-to-first-token and time-per-output-token latencies by 7.0%-16.9% and 25.4%-36.8% on average with the same energy-per-token for various mobile LLM models.
DASH: Input-Aware Dynamic Layer Skipping for Efficient LLM Inference with Markov Decision Policies
May 23, 2025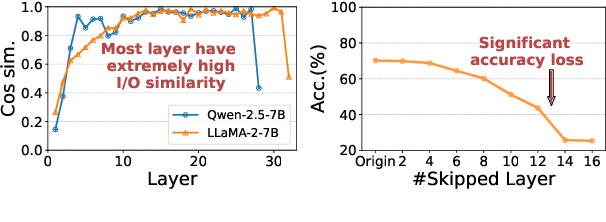
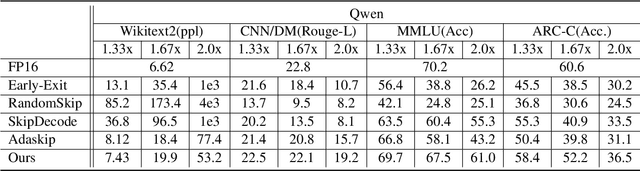
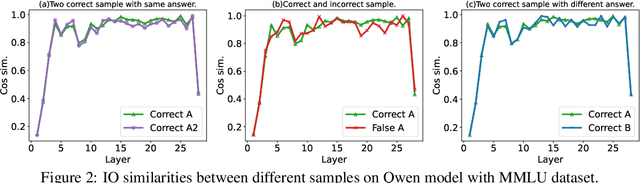
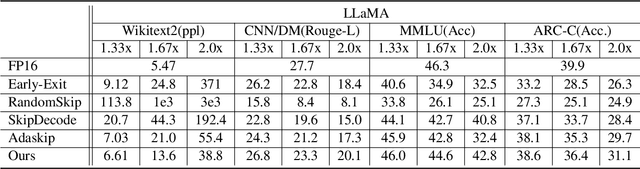
Large language models (LLMs) have achieved remarkable performance across a wide range of NLP tasks. However, their substantial inference cost poses a major barrier to real-world deployment, especially in latency-sensitive scenarios. To address this challenge, we propose \textbf{DASH}, an adaptive layer-skipping framework that dynamically selects computation paths conditioned on input characteristics. We model the skipping process as a Markov Decision Process (MDP), enabling fine-grained token-level decisions based on intermediate representations. To mitigate potential performance degradation caused by skipping, we introduce a lightweight compensation mechanism that injects differential rewards into the decision process. Furthermore, we design an asynchronous execution strategy that overlaps layer computation with policy evaluation to minimize runtime overhead. Experiments on multiple LLM architectures and NLP benchmarks show that our method achieves significant inference acceleration while maintaining competitive task performance, outperforming existing methods.
Samoyeds: Accelerating MoE Models with Structured Sparsity Leveraging Sparse Tensor Cores
Mar 13, 2025The escalating size of Mixture-of-Experts (MoE) based Large Language Models (LLMs) presents significant computational and memory challenges, necessitating innovative solutions to enhance efficiency without compromising model accuracy. Structured sparsity emerges as a compelling strategy to address these challenges by leveraging the emerging sparse computing hardware. Prior works mainly focus on the sparsity in model parameters, neglecting the inherent sparse patterns in activations. This oversight can lead to additional computational costs associated with activations, potentially resulting in suboptimal performance. This paper presents Samoyeds, an innovative acceleration system for MoE LLMs utilizing Sparse Tensor Cores (SpTCs). Samoyeds is the first to apply sparsity simultaneously to both activations and model parameters. It introduces a bespoke sparse data format tailored for MoE computation and develops a specialized sparse-sparse matrix multiplication kernel. Furthermore, Samoyeds incorporates systematic optimizations specifically designed for the execution of dual-side structured sparse MoE LLMs on SpTCs, further enhancing system performance. Evaluations show that Samoyeds outperforms SOTA works by up to 1.99$\times$ at the kernel level and 1.58$\times$ at the model level. Moreover, it enhances memory efficiency, increasing maximum supported batch sizes by 4.41$\times$ on average. Additionally, Samoyeds surpasses existing SOTA structured sparse solutions in both model accuracy and hardware portability.
Poisoning with A Pill: Circumventing Detection in Federated Learning
Jul 22, 2024



Without direct access to the client's data, federated learning (FL) is well-known for its unique strength in data privacy protection among existing distributed machine learning techniques. However, its distributive and iterative nature makes FL inherently vulnerable to various poisoning attacks. To counteract these threats, extensive defenses have been proposed to filter out malicious clients, using various detection metrics. Based on our analysis of existing attacks and defenses, we find that there is a lack of attention to model redundancy. In neural networks, various model parameters contribute differently to the model's performance. However, existing attacks in FL manipulate all the model update parameters with the same strategy, making them easily detectable by common defenses. Meanwhile, the defenses also tend to analyze the overall statistical features of the entire model updates, leaving room for sophisticated attacks. Based on these observations, this paper proposes a generic and attack-agnostic augmentation approach designed to enhance the effectiveness and stealthiness of existing FL poisoning attacks against detection in FL, pointing out the inherent flaws of existing defenses and exposing the necessity of fine-grained FL security. Specifically, we employ a three-stage methodology that strategically constructs, generates, and injects poison (generated by existing attacks) into a pill (a tiny subnet with a novel structure) during the FL training, named as pill construction, pill poisoning, and pill injection accordingly. Extensive experimental results show that FL poisoning attacks enhanced by our method can bypass all the popular defenses, and can gain an up to 7x error rate increase, as well as on average a more than 2x error rate increase on both IID and non-IID data, in both cross-silo and cross-device FL systems.
Exploring Diffusion Models' Corruption Stage in Few-Shot Fine-tuning and Mitigating with Bayesian Neural Networks
May 30, 2024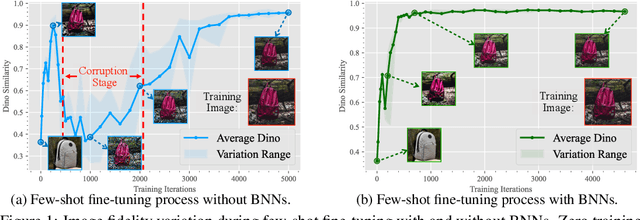
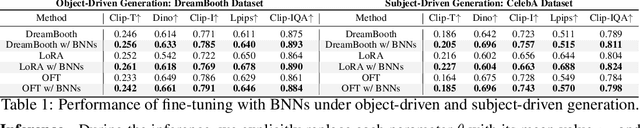
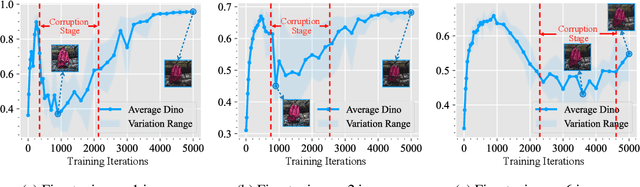
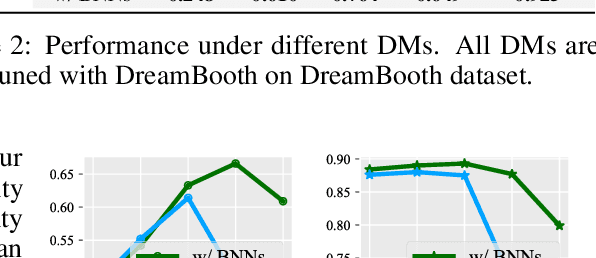
Few-shot fine-tuning of Diffusion Models (DMs) is a key advancement, significantly reducing training costs and enabling personalized AI applications. However, we explore the training dynamics of DMs and observe an unanticipated phenomenon: during the training process, image fidelity initially improves, then unexpectedly deteriorates with the emergence of noisy patterns, only to recover later with severe overfitting. We term the stage with generated noisy patterns as corruption stage. To understand this corruption stage, we begin by theoretically modeling the one-shot fine-tuning scenario, and then extend this modeling to more general cases. Through this modeling, we identify the primary cause of this corruption stage: a narrowed learning distribution inherent in the nature of few-shot fine-tuning. To tackle this, we apply Bayesian Neural Networks (BNNs) on DMs with variational inference to implicitly broaden the learned distribution, and present that the learning target of the BNNs can be naturally regarded as an expectation of the diffusion loss and a further regularization with the pretrained DMs. This approach is highly compatible with current few-shot fine-tuning methods in DMs and does not introduce any extra inference costs. Experimental results demonstrate that our method significantly mitigates corruption, and improves the fidelity, quality and diversity of the generated images in both object-driven and subject-driven generation tasks.
CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
Mar 17, 2024


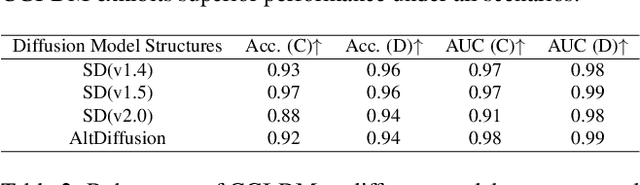
Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot generation where a pretrained model is fine-tuned on a small set of images to capture a specific style or object. Despite their success, concerns exist about potential copyright violations stemming from the use of unauthorized data in this process. In response, we present Contrasting Gradient Inversion for Diffusion Models (CGI-DM), a novel method featuring vivid visual representations for digital copyright authentication. Our approach involves removing partial information of an image and recovering missing details by exploiting conceptual differences between the pretrained and fine-tuned models. We formulate the differences as KL divergence between latent variables of the two models when given the same input image, which can be maximized through Monte Carlo sampling and Projected Gradient Descent (PGD). The similarity between original and recovered images serves as a strong indicator of potential infringements. Extensive experiments on the WikiArt and Dreambooth datasets demonstrate the high accuracy of CGI-DM in digital copyright authentication, surpassing alternative validation techniques. Code implementation is available at https://github.com/Nicholas0228/Revelio.