 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiva-DiT: Residual-Based Differentiable Top-$k$ Selection for Efficient Diffusion Transformers
Feb 05, 2026Diffusion Transformers (DiTs) incur prohibitive computational costs due to the quadratic scaling of self-attention. Existing pruning methods fail to simultaneously satisfy differentiability, efficiency, and the strict static budgets required for hardware overhead. To address this, we propose Shiva-DiT, which effectively reconciles these conflicting requirements via Residual-Based Differentiable Top-$k$ Selection. By leveraging a residual-aware straight-through estimator, our method enforces deterministic token counts for static compilation while preserving end-to-end learnability through residual gradient estimation. Furthermore, we introduce a Context-Aware Router and Adaptive Ratio Policy to autonomously learn an adaptive pruning schedule. Experiments on mainstream models, including SD3.5, demonstrate that Shiva-DiT establishes a new Pareto frontier, achieving a 1.54$\times$ wall-clock speedup with superior fidelity compared to existing baselines, effectively eliminating ragged tensor overheads.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
InstGenIE: Generative Image Editing Made Efficient with Mask-aware Caching and Scheduling
May 27, 2025
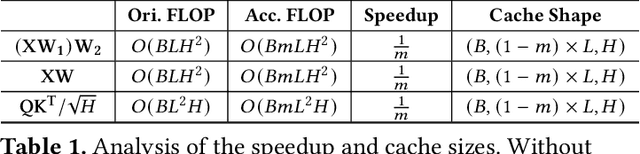
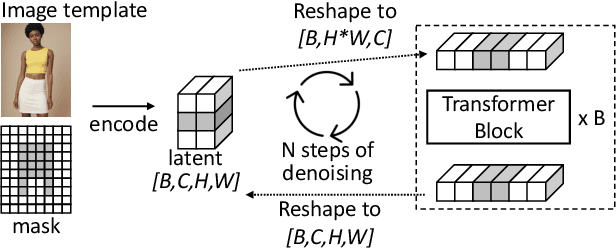
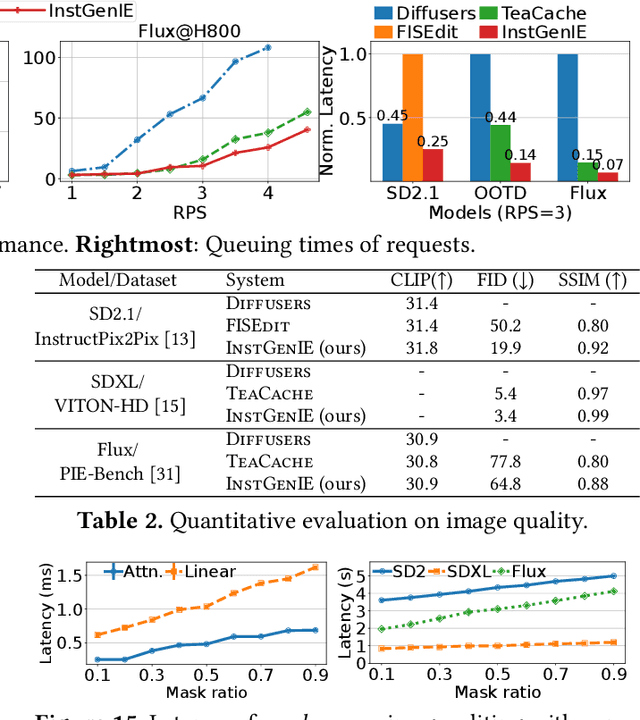
Generative image editing using diffusion models has become a prevalent application in today's AI cloud services. In production environments, image editing typically involves a mask that specifies the regions of an image template to be edited. The use of masks provides direct control over the editing process and introduces sparsity in the model inference. In this paper, we present InstGenIE, a system that efficiently serves image editing requests. The key insight behind InstGenIE is that image editing only modifies the masked regions of image templates while preserving the original content in the unmasked areas. Driven by this insight, InstGenIE judiciously skips redundant computations associated with the unmasked areas by reusing cached intermediate activations from previous inferences. To mitigate the high cache loading overhead, InstGenIE employs a bubble-free pipeline scheme that overlaps computation with cache loading. Additionally, to reduce queuing latency in online serving while improving the GPU utilization, InstGenIE proposes a novel continuous batching strategy for diffusion model serving, allowing newly arrived requests to join the running batch in just one step of denoising computation, without waiting for the entire batch to complete. As heterogeneous masks induce imbalanced loads, InstGenIE also develops a load balancing strategy that takes into account the loads of both computation and cache loading. Collectively, InstGenIE outperforms state-of-the-art diffusion serving systems for image editing, achieving up to 3x higher throughput and reducing average request latency by up to 14.7x while ensuring image quality.
DASH: Input-Aware Dynamic Layer Skipping for Efficient LLM Inference with Markov Decision Policies
May 23, 2025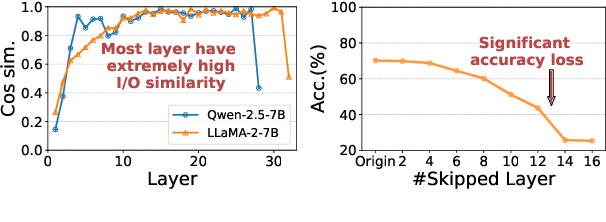
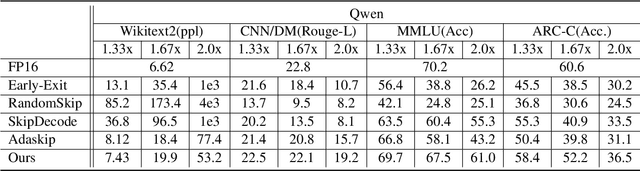
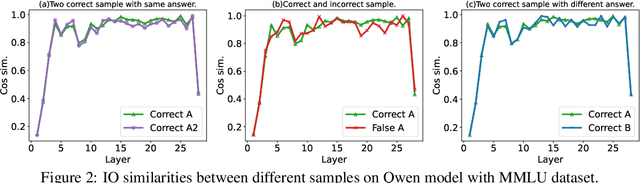
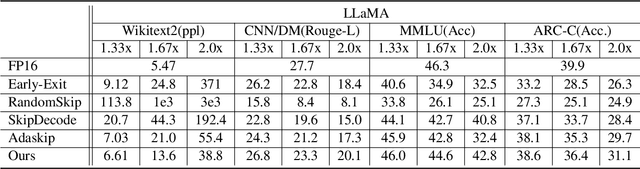
Large language models (LLMs) have achieved remarkable performance across a wide range of NLP tasks. However, their substantial inference cost poses a major barrier to real-world deployment, especially in latency-sensitive scenarios. To address this challenge, we propose \textbf{DASH}, an adaptive layer-skipping framework that dynamically selects computation paths conditioned on input characteristics. We model the skipping process as a Markov Decision Process (MDP), enabling fine-grained token-level decisions based on intermediate representations. To mitigate potential performance degradation caused by skipping, we introduce a lightweight compensation mechanism that injects differential rewards into the decision process. Furthermore, we design an asynchronous execution strategy that overlaps layer computation with policy evaluation to minimize runtime overhead. Experiments on multiple LLM architectures and NLP benchmarks show that our method achieves significant inference acceleration while maintaining competitive task performance, outperforming existing methods.
Denoising Diffusions in Latent Space for Medical Image Segmentation
Jul 17, 2024Diffusion models (DPMs) have demonstrated remarkable performance in image generation, often times outperforming other generative models. Since their introduction, the powerful noise-to-image denoising pipeline has been extended to various discriminative tasks, including image segmentation. In case of medical imaging, often times the images are large 3D scans, where segmenting one image using DPMs become extremely inefficient due to large memory consumption and time consuming iterative sampling process. In this work, we propose a novel conditional generative modeling framework (LDSeg) that performs diffusion in latent space for medical image segmentation. Our proposed framework leverages the learned inherent low-dimensional latent distribution of the target object shapes and source image embeddings. The conditional diffusion in latent space not only ensures accurate n-D image segmentation for multi-label objects, but also mitigates the major underlying problems of the traditional DPM based segmentation: (1) large memory consumption, (2) time consuming sampling process and (3) unnatural noise injection in forward/reverse process. LDSeg achieved state-of-the-art segmentation accuracy on three medical image datasets with different imaging modalities. Furthermore, we show that our proposed model is significantly more robust to noises, compared to the traditional deterministic segmentation models, which can be potential in solving the domain shift problems in the medical imaging domain. Codes are available at: https://github.com/LDSeg/LDSeg.
SwiftDiffusion: Efficient Diffusion Model Serving with Add-on Modules
Jul 02, 2024



This paper documents our characterization study and practices for serving text-to-image requests with stable diffusion models in production. We first comprehensively analyze inference request traces for commercial text-to-image applications. It commences with our observation that add-on modules, i.e., ControlNets and LoRAs, that augment the base stable diffusion models, are ubiquitous in generating images for commercial applications. Despite their efficacy, these add-on modules incur high loading overhead, prolong the serving latency, and swallow up expensive GPU resources. Driven by our characterization study, we present SwiftDiffusion, a system that efficiently generates high-quality images using stable diffusion models and add-on modules. To achieve this, SwiftDiffusion reconstructs the existing text-to-image serving workflow by identifying the opportunities for parallel computation and distributing ControlNet computations across multiple GPUs. Further, SwiftDiffusion thoroughly analyzes the dynamics of image generation and develops techniques to eliminate the overhead associated with LoRA loading and patching while preserving the image quality. Last, SwiftDiffusion proposes specialized optimizations in the backbone architecture of the stable diffusion models, which are also compatible with the efficient serving of add-on modules. Compared to state-of-the-art text-to-image serving systems, SwiftDiffusion reduces serving latency by up to 5x and improves serving throughput by up to 2x without compromising image quality.
Surf-CDM: Score-Based Surface Cold-Diffusion Model For Medical Image Segmentation
Dec 19, 2023Diffusion models have shown impressive performance for image generation, often times outperforming other generative models. Since their introduction, researchers have extended the powerful noise-to-image denoising pipeline to discriminative tasks, including image segmentation. In this work we propose a conditional score-based generative modeling framework for medical image segmentation which relies on a parametric surface representation for the segmentation masks. The surface re-parameterization allows the direct application of standard diffusion theory, as opposed to when the mask is represented as a binary mask. Moreover, we adapted an extended variant of the diffusion technique known as the "cold-diffusion" where the diffusion model can be constructed with deterministic perturbations instead of Gaussian noise, which facilitates significantly faster convergence in the reverse diffusion. We evaluated our method on the segmentation of the left ventricle from 65 transthoracic echocardiogram videos (2230 echo image frames) and compared its performance to the most popular and widely used image segmentation models. Our proposed model not only outperformed the compared methods in terms of segmentation accuracy, but also showed potential in estimating segmentation uncertainties for further downstream analyses due to its inherent generative nature.
Diagnosis Of Takotsubo Syndrome By Robust Feature Selection From The Complex Latent Space Of DL-based Segmentation Network
Dec 19, 2023Researchers have shown significant correlations among segmented objects in various medical imaging modalities and disease related pathologies. Several studies showed that using hand crafted features for disease prediction neglects the immense possibility to use latent features from deep learning (DL) models which may reduce the overall accuracy of differential diagnosis. However, directly using classification or segmentation models on medical to learn latent features opt out robust feature selection and may lead to overfitting. To fill this gap, we propose a novel feature selection technique using the latent space of a segmentation model that can aid diagnosis. We evaluated our method in differentiating a rare cardiac disease: Takotsubo Syndrome (TTS) from the ST elevation myocardial infarction (STEMI) using echocardiogram videos (echo). TTS can mimic clinical features of STEMI in echo and extremely hard to distinguish. Our approach shows promising results in differential diagnosis of TTS with 82% diagnosis accuracy beating the previous state-of-the-art (SOTA) approach. Moreover, the robust feature selection technique using LASSO algorithm shows great potential in reducing the redundant features and creates a robust pipeline for short- and long-term disease prognoses in the downstream analysis.
Equitability of Dependence Measure
Jul 11, 2018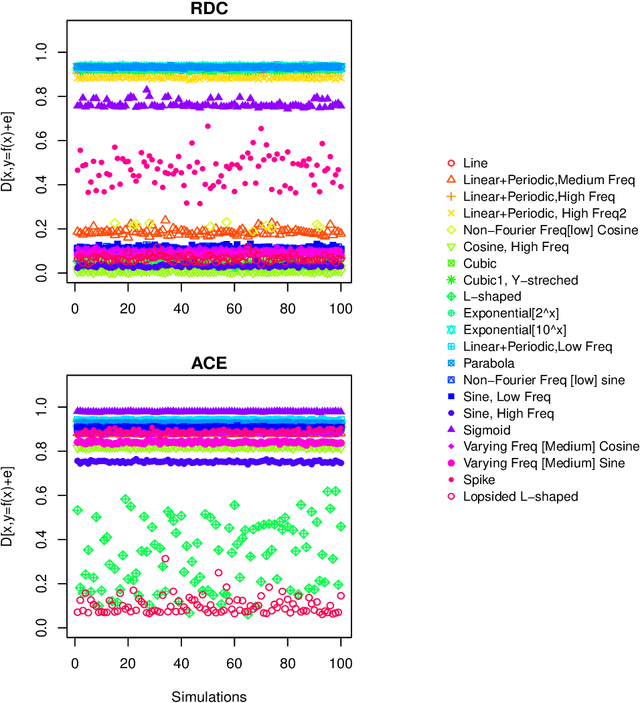
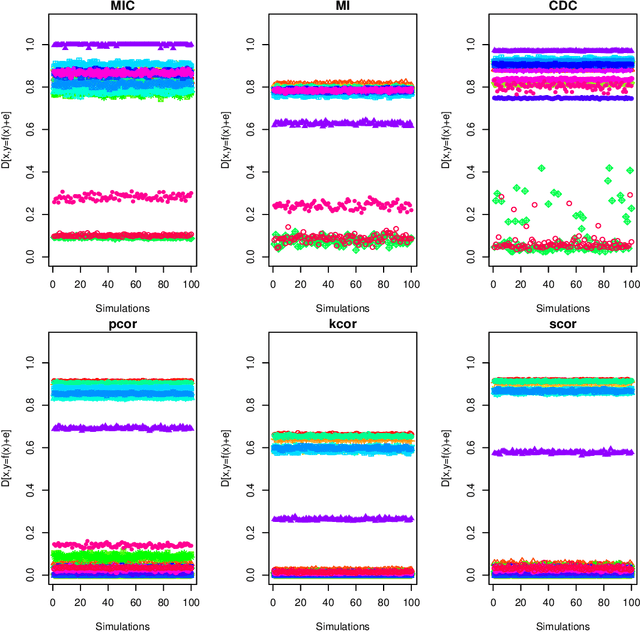
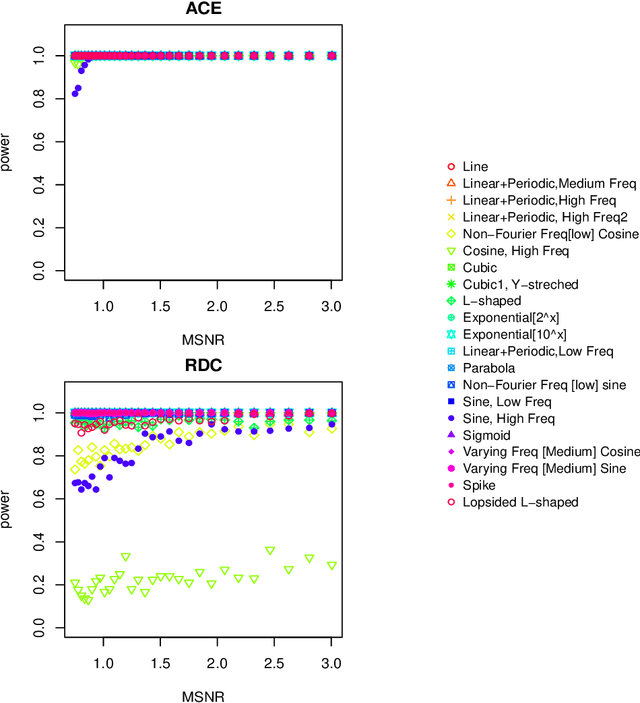
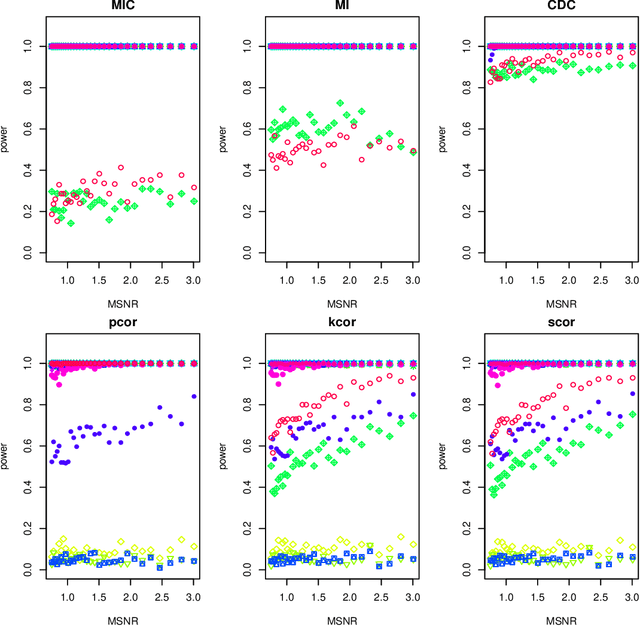
Measuring dependence between two random variables is very important, and critical in many applied areas such as variable selection, brain network analysis. However, we do not know what kind of functional relationship is between two covariates, which requires the dependence measure to be equitable. That is, it gives similar scores to equally noisy relationship of different types. In fact, the dependence score is a continuous random variable taking values in $[0,1]$, thus it is theoretically impossible to give similar scores. In this paper, we introduce a new definition of equitability of a dependence measure, i.e, power-equitable (weak-equitable) and show by simulation that HHG and Copula Dependence Coefficient (CDC) are weak-equitable.
Learning Compact Appearance Representation for Video-based Person Re-Identification
Feb 21, 2017



This paper presents a novel approach for video-based person re-identification using multiple Convolutional Neural Networks (CNNs). Unlike previous work, we intend to extract a compact yet discriminative appearance representation from several frames rather than the whole sequence. Specifically, given a video, the representative frames are selected based on the walking profile of consecutive frames. A multiple CNN architecture incorporated with feature pooling is proposed to learn and compile the features of the selected representative frames into a compact description about the pedestrian for identification. Experiments are conducted on benchmark datasets to demonstrate the superiority of the proposed method over existing person re-identification approaches.