 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosis Of Takotsubo Syndrome By Robust Feature Selection From The Complex Latent Space Of DL-based Segmentation Network
Dec 19, 2023Researchers have shown significant correlations among segmented objects in various medical imaging modalities and disease related pathologies. Several studies showed that using hand crafted features for disease prediction neglects the immense possibility to use latent features from deep learning (DL) models which may reduce the overall accuracy of differential diagnosis. However, directly using classification or segmentation models on medical to learn latent features opt out robust feature selection and may lead to overfitting. To fill this gap, we propose a novel feature selection technique using the latent space of a segmentation model that can aid diagnosis. We evaluated our method in differentiating a rare cardiac disease: Takotsubo Syndrome (TTS) from the ST elevation myocardial infarction (STEMI) using echocardiogram videos (echo). TTS can mimic clinical features of STEMI in echo and extremely hard to distinguish. Our approach shows promising results in differential diagnosis of TTS with 82% diagnosis accuracy beating the previous state-of-the-art (SOTA) approach. Moreover, the robust feature selection technique using LASSO algorithm shows great potential in reducing the redundant features and creates a robust pipeline for short- and long-term disease prognoses in the downstream analysis.
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
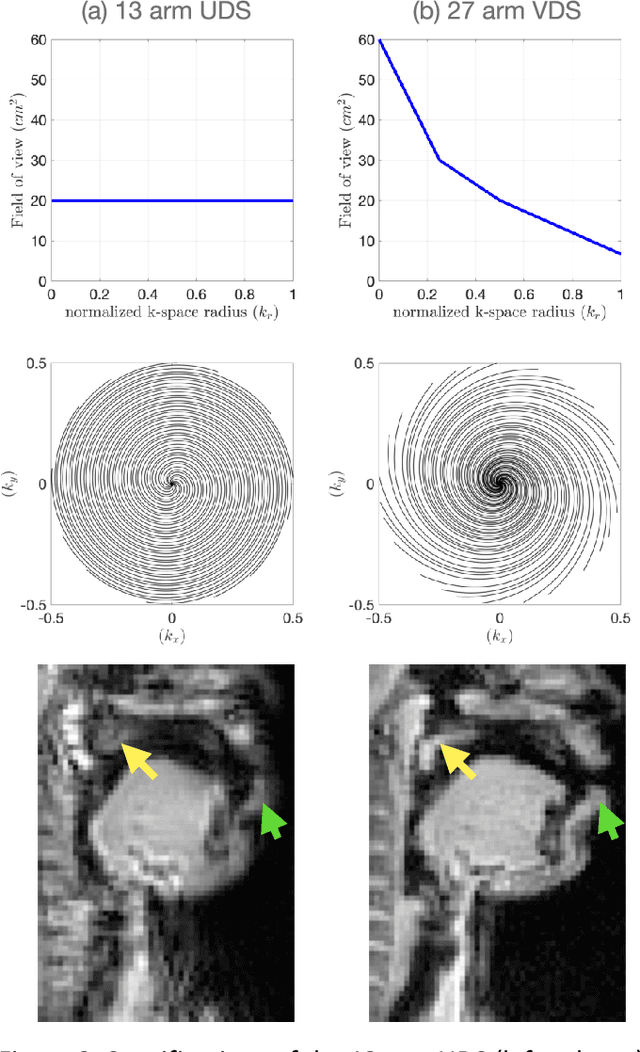
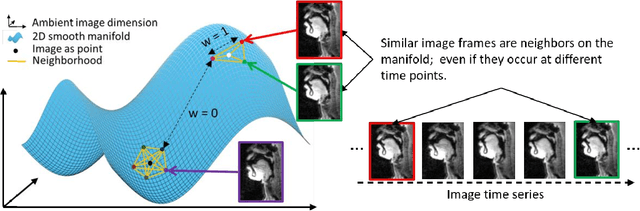
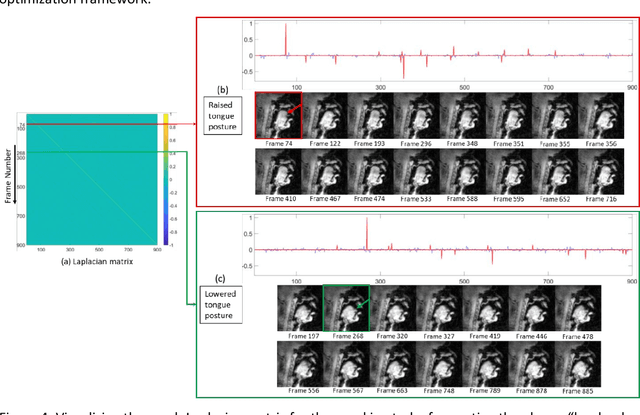
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
Fast Low Rank column-wise Compressive Sensing for Accelerated Dynamic MRI
Jun 27, 2022



This work develops a fast, memory-efficient, and general algorithm for accelerated/undersampled dynamic MRI by assuming an approximate LR model on the matrix formed by the vectorized images of the sequence. By general, we mean that our algorithm can be used for multiple accelerated dynamic MRI applications and multiple sampling rates (acceleration rates) without any parameter changes. We show that our proposed algorithm, alternating Gradient Descent (GD) and minimization for MRI (altGDmin-MRI), outperforms many existing approaches on 6 different dynamic MRI applications, while also being faster (or much faster) than all of them. Our second contribution is a fully online and mini-batch extensions of this algorithm that can process new measurements and return reconstructions either as soon as measurements of a new image frame arrive, or after a short mini-batch of measurement vectors arrives.