 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Paper and Code

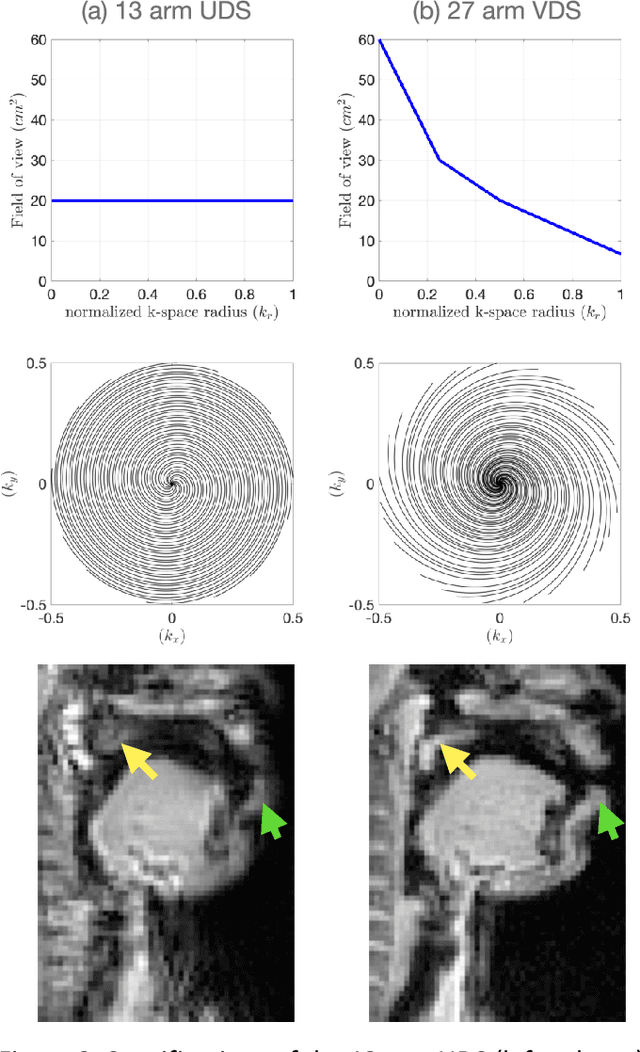
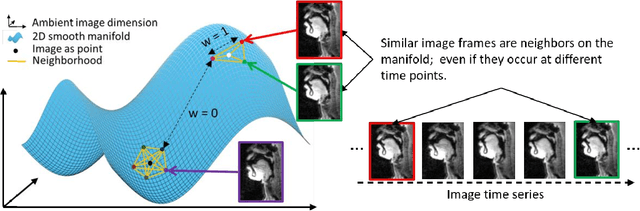
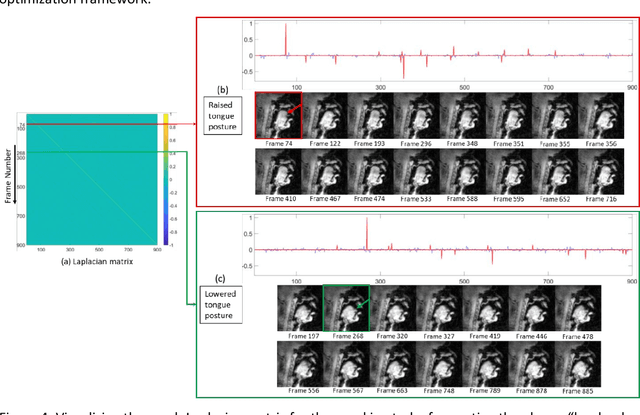
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.