 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
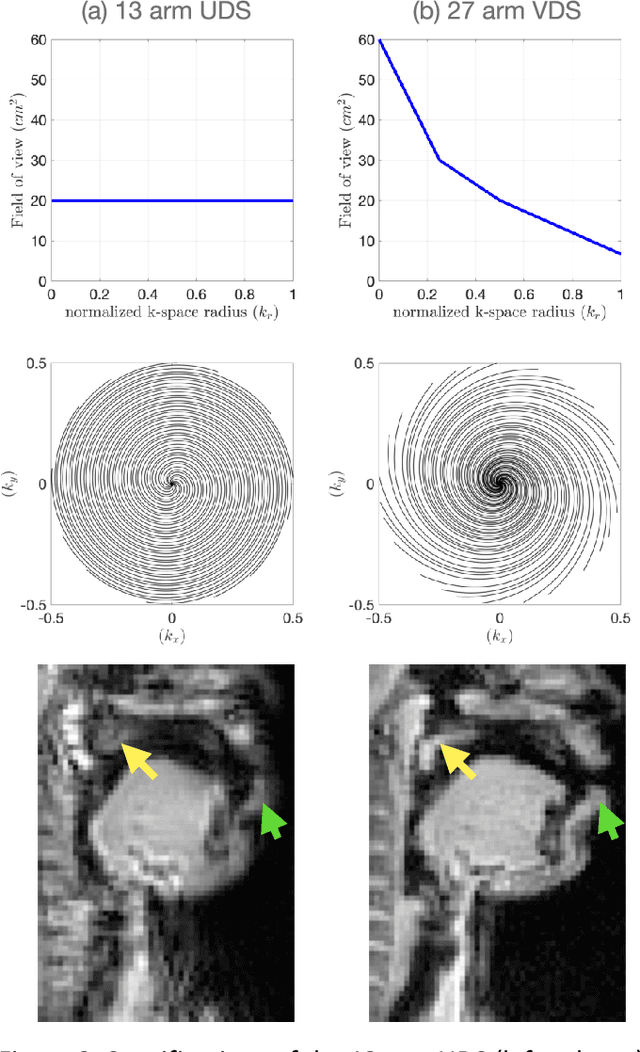
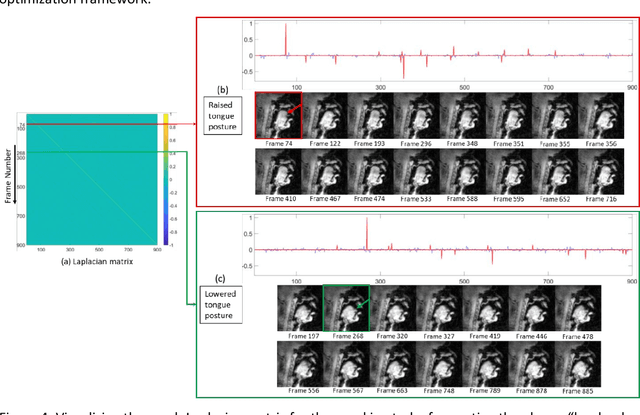
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
Dynamic imaging using a deep generative SToRM model
Feb 11, 2021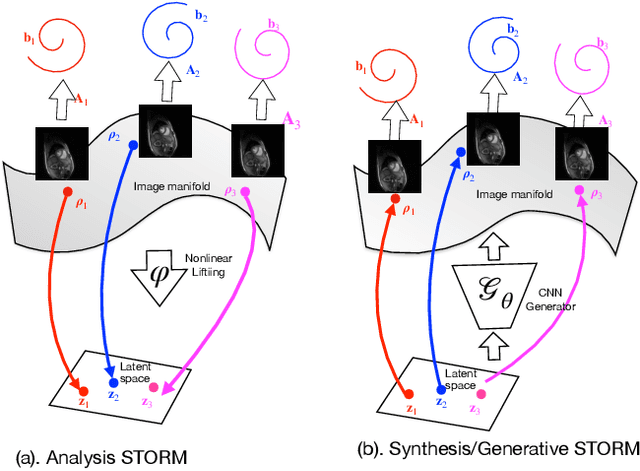
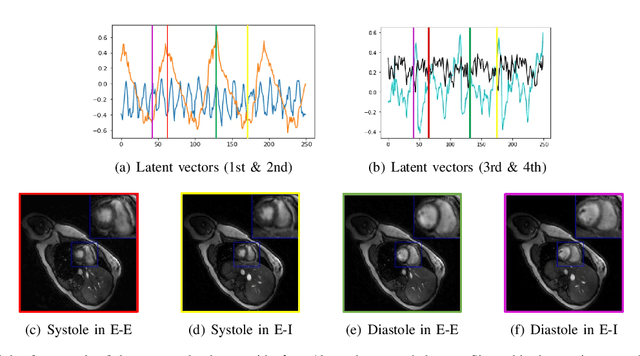
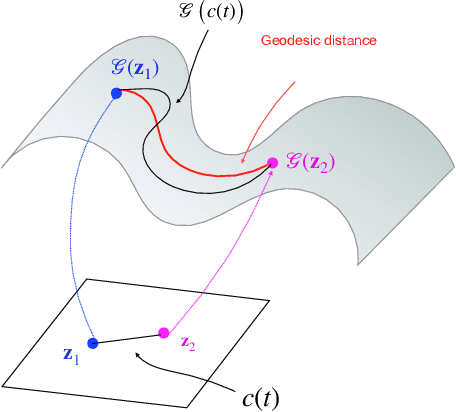
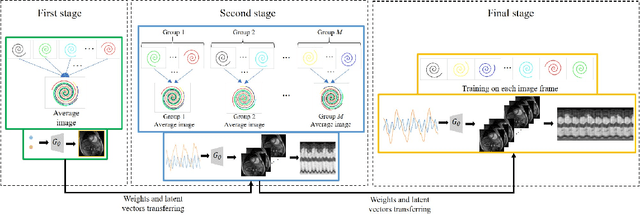
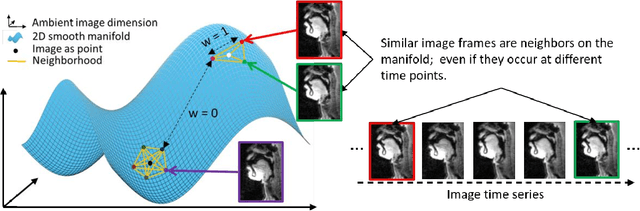
We introduce a generative smoothness regularization on manifolds (SToRM) model for the recovery of dynamic image data from highly undersampled measurements. The model assumes that the images in the dataset are non-linear mappings of low-dimensional latent vectors. We use the deep convolutional neural network (CNN) to represent the non-linear transformation. The parameters of the generator as well as the low-dimensional latent vectors are jointly estimated only from the undersampled measurements. This approach is different from traditional CNN approaches that require extensive fully sampled training data. We penalize the norm of the gradients of the non-linear mapping to constrain the manifold to be smooth, while temporal gradients of the latent vectors are penalized to obtain a smoothly varying time-series. The proposed scheme brings in the spatial regularization provided by the convolutional network. The main benefit of the proposed scheme is the improvement in image quality and the orders-of-magnitude reduction in memory demand compared to traditional manifold models. To minimize the computational complexity of the algorithm, we introduce an efficient progressive training-in-time approach and an approximate cost function. These approaches speed up the image reconstructions and offers better reconstruction performance.
Deep Generative SToRM model for dynamic imaging
Jan 29, 2021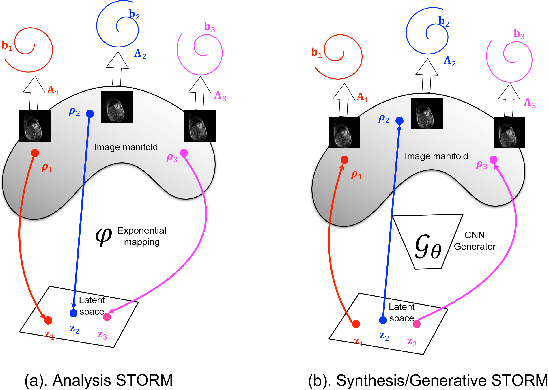
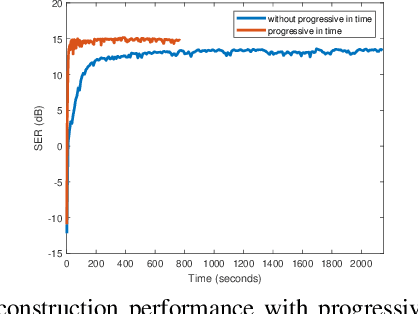
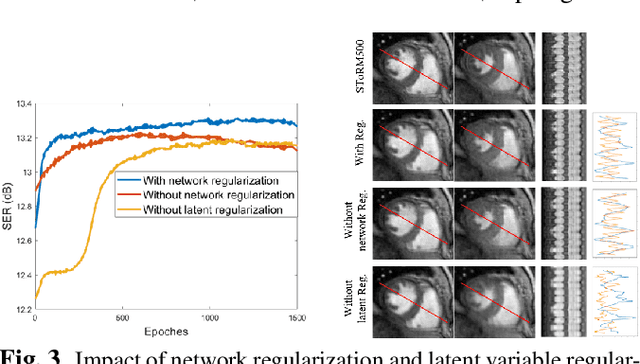
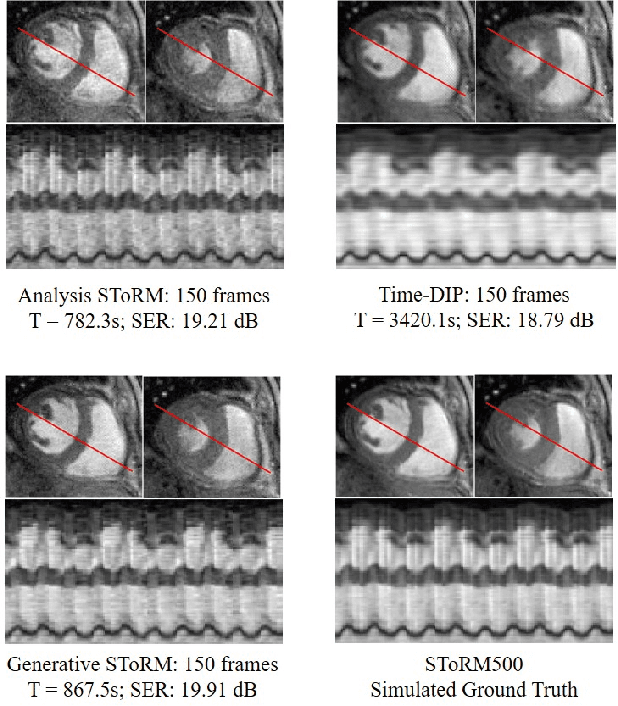
We introduce a novel generative smoothness regularization on manifolds (SToRM) model for the recovery of dynamic image data from highly undersampled measurements. The proposed generative framework represents the image time series as a smooth non-linear function of low-dimensional latent vectors that capture the cardiac and respiratory phases. The non-linear function is represented using a deep convolutional neural network (CNN). Unlike the popular CNN approaches that require extensive fully-sampled training data that is not available in this setting, the parameters of the CNN generator as well as the latent vectors are jointly estimated from the undersampled measurements using stochastic gradient descent. We penalize the norm of the gradient of the generator to encourage the learning of a smooth surface/manifold, while temporal gradients of the latent vectors are penalized to encourage the time series to be smooth. The main benefits of the proposed scheme are (a) the quite significant reduction in memory demand compared to the analysis based SToRM model, and (b) the spatial regularization brought in by the CNN model. We also introduce efficient progressive approaches to minimize the computational complexity of the algorithm.
Alignment & joint recovery of multi-slice dynamic MRI using deep generative manifold model
Jan 20, 2021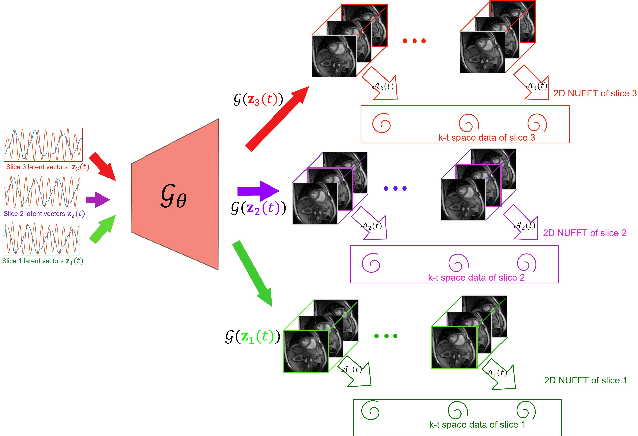
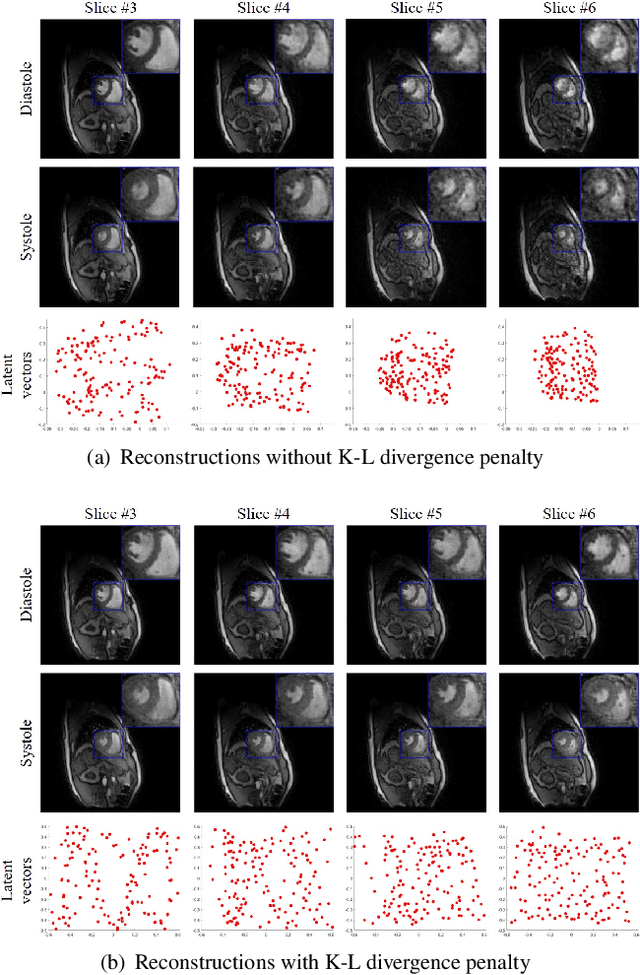
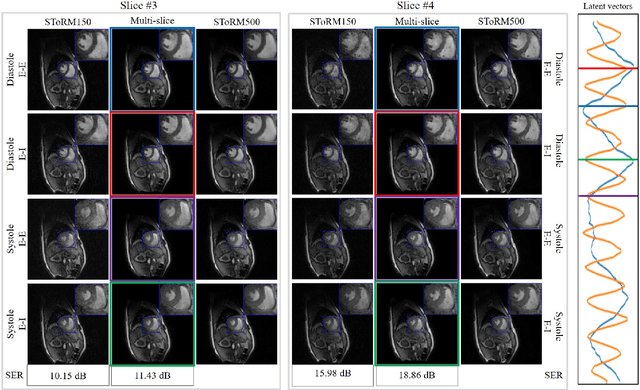
We introduce a novel unsupervised deep generative manifold model for the recovery of multi-slice free-breathing and ungated cardiac MRI from highly undersampled measurements. The proposed scheme represents the multi-slice volume at each time point as the output of a deep convolutional neural network (CNN) generator, which is driven by latent vectors that capture the cardiac and respiratory phase at the specific time point. The main difference between the proposed method and the traditional CNN approaches is that the proposed scheme learns the network parameters from only the highly undersampled data rather than the extensive fully-sampled training data. We also learn the latent codes from the undersampled data using the stochastic gradient descent. Regularizations on the network and the latent codes are introduced to encourage the learning of smooth image manifold and the latent codes for each slice have the same distribution. The main benefits of the proposed scheme are (a) the ability to align multi-slice data and capitalize on the redundancy between the slices; (b) the ability to estimate the gating information directly from the k-t space data; and (c) the unsupervised learning strategy that eliminates the need for extensive training data.