 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shot Alternating GD and Minimization for Generalizable Real-Time MRI
Feb 26, 2025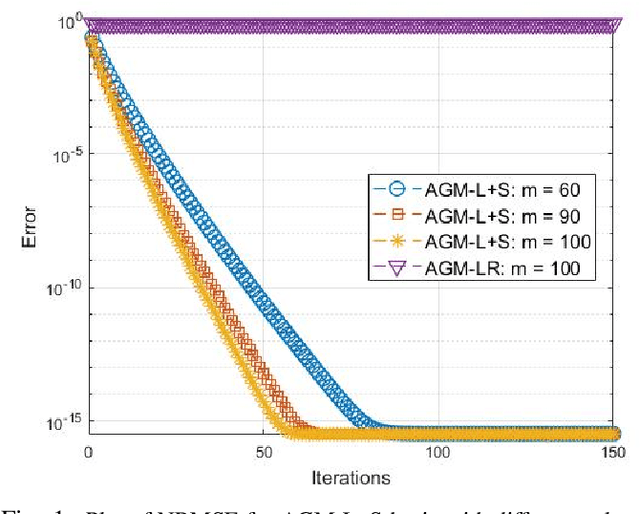
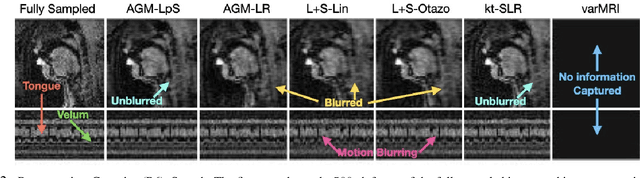
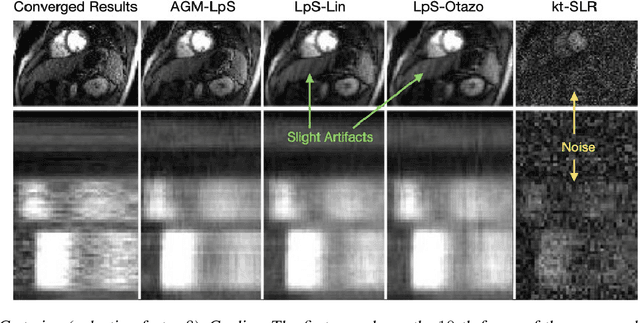
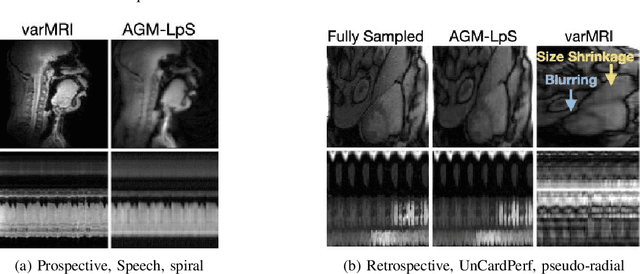
This work introduces a novel near real-time (real-time after an initial short delay) MRI solution that handles motion well and is generalizable. Here, real-time means the algorithm works well on a highly accelerated scan, is zero-latency (reconstructs a new frame as soon as MRI data for it arrives), and is fast enough, i.e., the time taken to process a frame is comparable to the scan time per frame or lesser. We demonstrate its generalizability through experiments on 6 prospective datasets and 17 retrospective datasets that span multiple different applications -- speech larynx imaging, brain, ungated cardiac perfusion, cardiac cine, cardiac OCMR, abdomen; sampling schemes -- Cartesian, pseudo-radial, radial, spiral; and sampling rates -- ranging from 6x to 4 radial lines per frame. Comparisons with a large number of existing real-time and batch methods, including unsupervised and supervised deep learning methods, show the power and speed of our approach.
Open-Source Manually Annotated Vocal Tract Database for Automatic Segmentation from 3D MRI Using Deep Learning: Benchmarking 2D and 3D Convolutional and Transformer Networks
Jan 08, 2025



Accurate segmentation of the vocal tract from magnetic resonance imaging (MRI) data is essential for various voice and speech applications. Manual segmentation is time intensive and susceptible to errors. This study aimed to evaluate the efficacy of deep learning algorithms for automatic vocal tract segmentation from 3D MRI.
Fast Low Rank column-wise Compressive Sensing for Accelerated Dynamic MRI
Dec 19, 2022This work develops a novel set of algorithms, alternating Gradient Descent (GD) and minimization for MRI (altGDmin-MRI1 and altGDmin-MRI2), for accelerated dynamic MRI by assuming an approximate low-rank (LR) model on the matrix formed by the vectorized images of the sequence. The LR model itself is well-known in the MRI literature; our contribution is the novel GD-based algorithms which are much faster, memory efficient, and general compared with existing work; and careful use of a 3-level hierarchical LR model. By general, we mean that, with a single choice of parameters, our method provides accurate reconstructions for multiple accelerated dynamic MRI applications, multiple sampling rates and sampling schemes. We show that our methods outperform many of the popular existing approaches while also being faster than all of them, on average. This claim is based on comparisons on 8 different retrospectively under sampled multi-coil dynamic MRI applications, sampled using either 1D Cartesian or 2D pseudo radial under sampling, at multiple sampling rates. Evaluations on some prospectively under sampled datasets are also provided. Our second contribution is a mini-batch subspace tracking extension that can process new measurements and return reconstructions within a short delay after they arrive. The recovery algorithm itself is also faster than its batch counterpart.
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
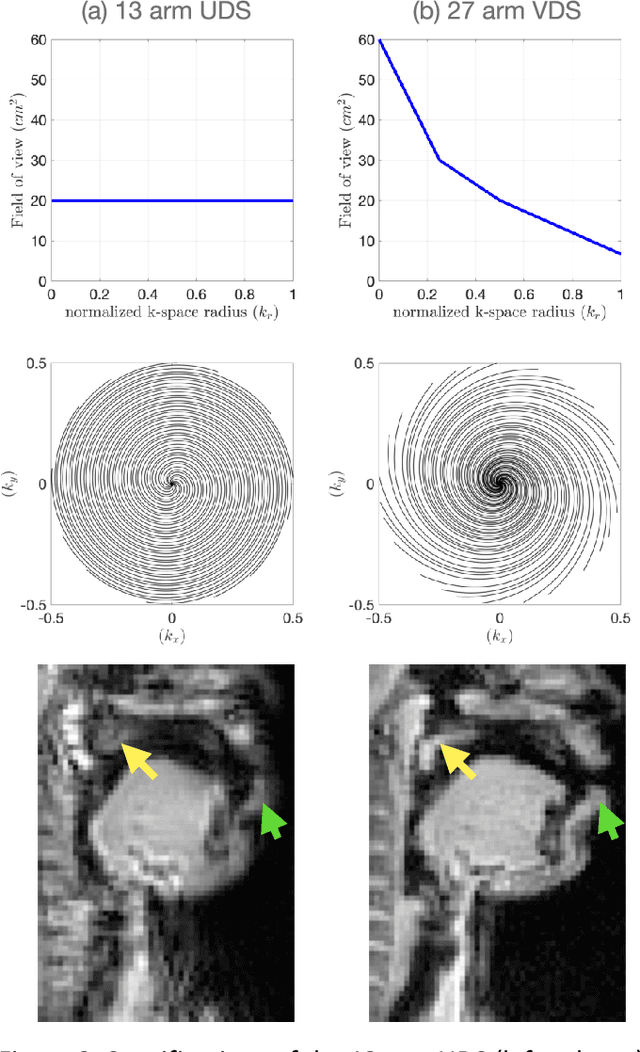
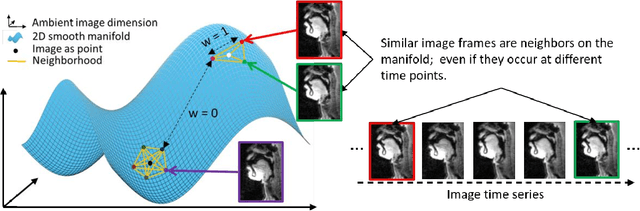
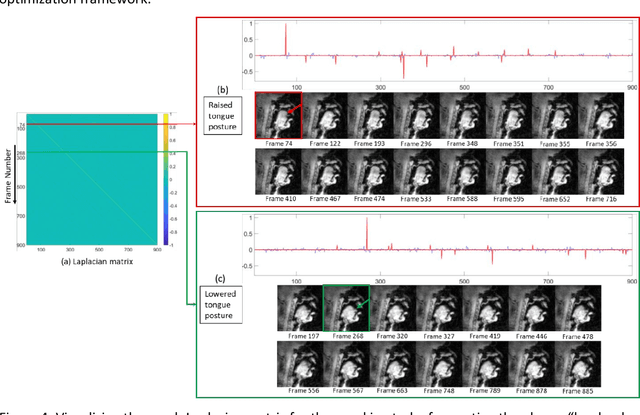
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images
Feb 16, 2021
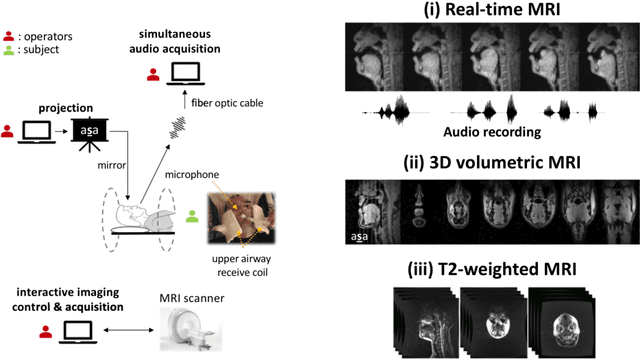
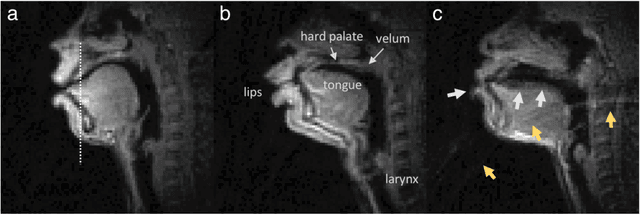
Real-time magnetic resonance imaging (RT-MRI) of human speech production is enabling significant advances in speech science, linguistics, bio-inspired speech technology development, and clinical applications. Easy access to RT-MRI is however limited, and comprehensive datasets with broad access are needed to catalyze research across numerous domains. The imaging of the rapidly moving articulators and dynamic airway shaping during speech demands high spatio-temporal resolution and robust reconstruction methods. Further, while reconstructed images have been published, to-date there is no open dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. Such datasets could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically-relevant biomarkers. The present dataset offers a unique corpus of 2D sagittal-view RT-MRI videos along with synchronized audio for 75 subjects performing linguistically motivated speech tasks, alongside the corresponding first-ever public domain raw RT-MRI data. The dataset also includes 3D volumetric vocal tract MRI during sustained speech sounds and high-resolution static anatomical T2-weighted upper airway MRI for each subject.
Deformation corrected compressed sensing (DC-CS): a novel framework for accelerated dynamic MRI
Sep 02, 2014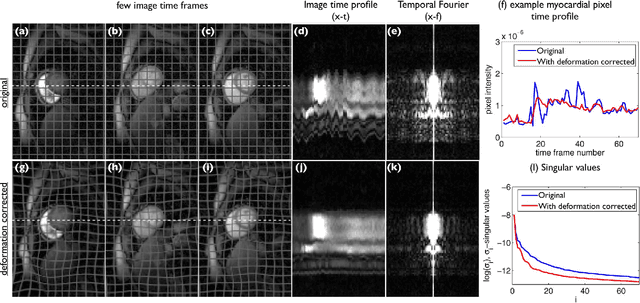
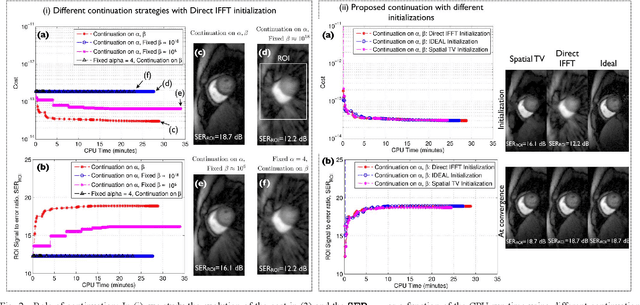
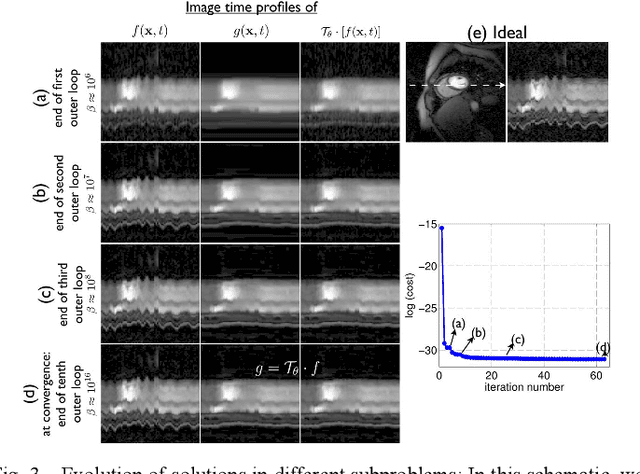
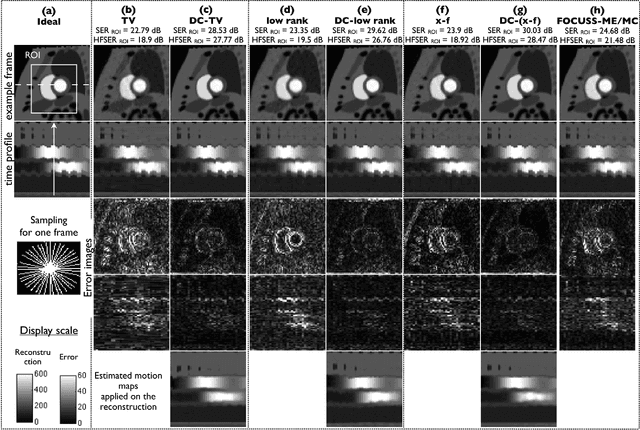
We propose a novel deformation corrected compressed sensing (DC-CS) framework to recover dynamic magnetic resonance images from undersampled measurements. We introduce a generalized formulation that is capable of handling a wide class of sparsity/compactness priors on the deformation corrected dynamic signal. In this work, we consider example compactness priors such as sparsity in temporal Fourier domain, sparsity in temporal finite difference domain, and nuclear norm penalty to exploit low rank structure. Using variable splitting, we decouple the complex optimization problem to simpler and well understood sub problems; the resulting algorithm alternates between simple steps of shrinkage based denoising, deformable registration, and a quadratic optimization step. Additionally, we employ efficient continuation strategies to minimize the risk of convergence to local minima. The proposed formulation contrasts with existing DC-CS schemes that are customized for free breathing cardiac cine applications, and other schemes that rely on fully sampled reference frames or navigator signals to estimate the deformation parameters. The efficient decoupling enabled by the proposed scheme allows its application to a wide range of applications including contrast enhanced dynamic MRI. Through experiments on numerical phantom and in vivo myocardial perfusion MRI datasets, we demonstrate the utility of the proposed DC-CS scheme in providing robust reconstructions with reduced motion artifacts over classical compressed sensing schemes that utilize the compact priors on the original deformation un-corrected signal.