 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegoDiffusion: Micro-Serving Text-to-Image Diffusion Workflows
Apr 09, 2026Text-to-image generation executes a diffusion workflow comprising multiple models centered on a base diffusion model. Existing serving systems treat each workflow as an opaque monolith, provisioning, placing, and scaling all constituent models together, which obscures internal dataflow, prevents model sharing, and enforces coarse-grained resource management. In this paper, we make a case for micro-serving diffusion workflows with LegoDiffusion, a system that decomposes a workflow into loosely coupled model-execution nodes that can be independently managed and scheduled. By explicitly managing individual model inference, LegoDiffusion unlocks cluster-scale optimizations, including per-model scaling, model sharing, and adaptive model parallelism. Collectively, LegoDiffusion outperforms existing diffusion workflow serving systems, sustaining up to 3x higher request rates and tolerating up to 8x higher burst traffic.
InstGenIE: Generative Image Editing Made Efficient with Mask-aware Caching and Scheduling
May 27, 2025
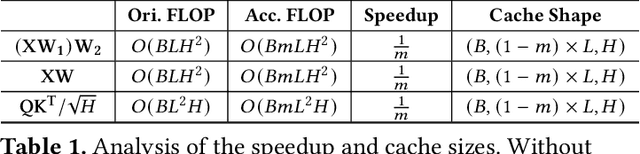
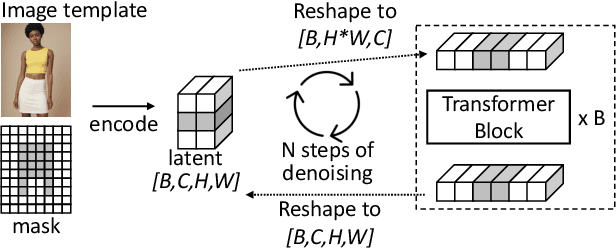
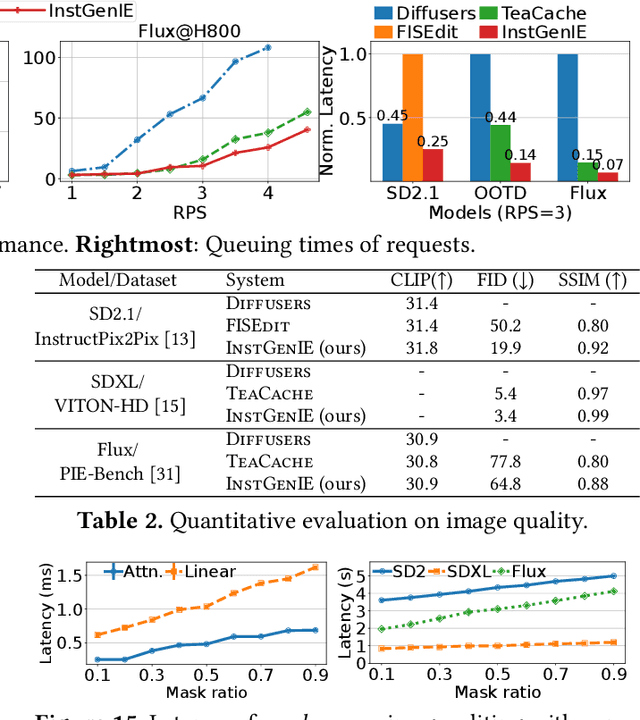
Generative image editing using diffusion models has become a prevalent application in today's AI cloud services. In production environments, image editing typically involves a mask that specifies the regions of an image template to be edited. The use of masks provides direct control over the editing process and introduces sparsity in the model inference. In this paper, we present InstGenIE, a system that efficiently serves image editing requests. The key insight behind InstGenIE is that image editing only modifies the masked regions of image templates while preserving the original content in the unmasked areas. Driven by this insight, InstGenIE judiciously skips redundant computations associated with the unmasked areas by reusing cached intermediate activations from previous inferences. To mitigate the high cache loading overhead, InstGenIE employs a bubble-free pipeline scheme that overlaps computation with cache loading. Additionally, to reduce queuing latency in online serving while improving the GPU utilization, InstGenIE proposes a novel continuous batching strategy for diffusion model serving, allowing newly arrived requests to join the running batch in just one step of denoising computation, without waiting for the entire batch to complete. As heterogeneous masks induce imbalanced loads, InstGenIE also develops a load balancing strategy that takes into account the loads of both computation and cache loading. Collectively, InstGenIE outperforms state-of-the-art diffusion serving systems for image editing, achieving up to 3x higher throughput and reducing average request latency by up to 14.7x while ensuring image quality.
SwiftDiffusion: Efficient Diffusion Model Serving with Add-on Modules
Jul 02, 2024



This paper documents our characterization study and practices for serving text-to-image requests with stable diffusion models in production. We first comprehensively analyze inference request traces for commercial text-to-image applications. It commences with our observation that add-on modules, i.e., ControlNets and LoRAs, that augment the base stable diffusion models, are ubiquitous in generating images for commercial applications. Despite their efficacy, these add-on modules incur high loading overhead, prolong the serving latency, and swallow up expensive GPU resources. Driven by our characterization study, we present SwiftDiffusion, a system that efficiently generates high-quality images using stable diffusion models and add-on modules. To achieve this, SwiftDiffusion reconstructs the existing text-to-image serving workflow by identifying the opportunities for parallel computation and distributing ControlNet computations across multiple GPUs. Further, SwiftDiffusion thoroughly analyzes the dynamics of image generation and develops techniques to eliminate the overhead associated with LoRA loading and patching while preserving the image quality. Last, SwiftDiffusion proposes specialized optimizations in the backbone architecture of the stable diffusion models, which are also compatible with the efficient serving of add-on modules. Compared to state-of-the-art text-to-image serving systems, SwiftDiffusion reduces serving latency by up to 5x and improves serving throughput by up to 2x without compromising image quality.
A Novel Architecture Slimming Method for Network Pruning and Knowledge Distillation
Feb 21, 2022



Network pruning and knowledge distillation are two widely-known model compression methods that efficiently reduce computation cost and model size. A common problem in both pruning and distillation is to determine compressed architecture, i.e., the exact number of filters per layer and layer configuration, in order to preserve most of the original model capacity. In spite of the great advances in existing works, the determination of an excellent architecture still requires human interference or tremendous experimentations. In this paper, we propose an architecture slimming method that automates the layer configuration process. We start from the perspective that the capacity of the over-parameterized model can be largely preserved by finding the minimum number of filters preserving the maximum parameter variance per layer, resulting in a thin architecture. We formulate the determination of compressed architecture as a one-step orthogonal linear transformation, and integrate principle component analysis (PCA), where the variances of filters in the first several projections are maximized. We demonstrate the rationality of our analysis and the effectiveness of the proposed method through extensive experiments. In particular, we show that under the same overall compression rate, the compressed architecture determined by our method shows significant performance gain over baselines after pruning and distillation. Surprisingly, we find that the resulting layer-wise compression rates correspond to the layer sensitivities found by existing works through tremendous experimentations.