 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of Vision-Language Models for Content Moderation of Children's Videos
Dec 06, 2023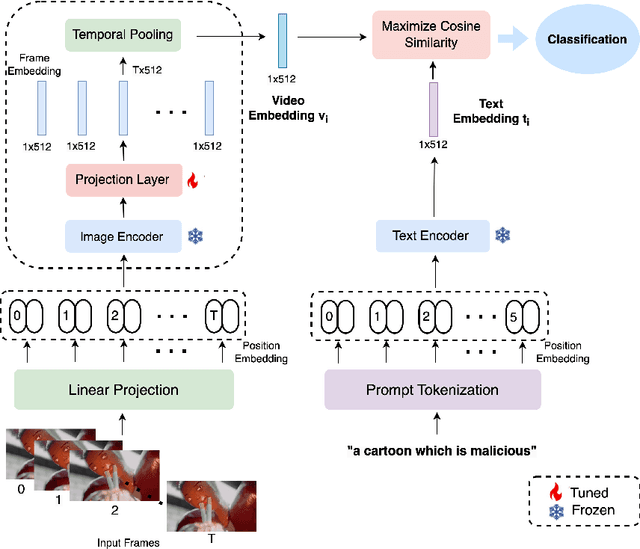

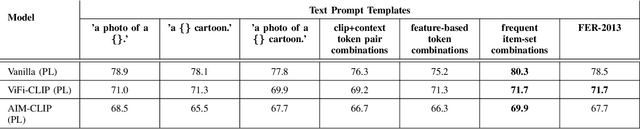
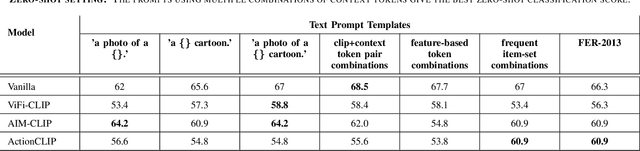
Natural language supervision has been shown to be effective for zero-shot learning in many computer vision tasks, such as object detection and activity recognition. However, generating informative prompts can be challenging for more subtle tasks, such as video content moderation. This can be difficult, as there are many reasons why a video might be inappropriate, beyond violence and obscenity. For example, scammers may attempt to create junk content that is similar to popular educational videos but with no meaningful information. This paper evaluates the performance of several CLIP variations for content moderation of children's cartoons in both the supervised and zero-shot setting. We show that our proposed model (Vanilla CLIP with Projection Layer) outperforms previous work conducted on the Malicious or Benign (MOB) benchmark for video content moderation. This paper presents an in depth analysis of how context-specific language prompts affect content moderation performance. Our results indicate that it is important to include more context in content moderation prompts, particularly for cartoon videos as they are not well represented in the CLIP training data.
LAMP: Leveraging Language Prompts for Multi-person Pose Estimation
Jul 26, 2023
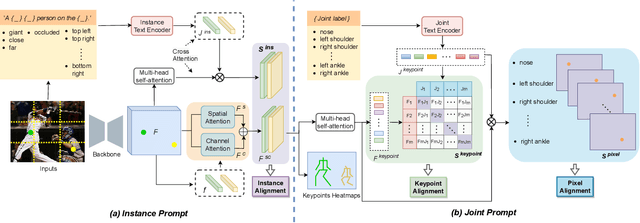


Human-centric visual understanding is an important desideratum for effective human-robot interaction. In order to navigate crowded public places, social robots must be able to interpret the activity of the surrounding humans. This paper addresses one key aspect of human-centric visual understanding, multi-person pose estimation. Achieving good performance on multi-person pose estimation in crowded scenes is difficult due to the challenges of occluded joints and instance separation. In order to tackle these challenges and overcome the limitations of image features in representing invisible body parts, we propose a novel prompt-based pose inference strategy called LAMP (Language Assisted Multi-person Pose estimation). By utilizing the text representations generated by a well-trained language model (CLIP), LAMP can facilitate the understanding of poses on the instance and joint levels, and learn more robust visual representations that are less susceptible to occlusion. This paper demonstrates that language-supervised training boosts the performance of single-stage multi-person pose estimation, and both instance-level and joint-level prompts are valuable for training. The code is available at https://github.com/shengnanh20/LAMP.
Predicting Team Performance with Spatial Temporal Graph Convolutional Networks
Jun 21, 2022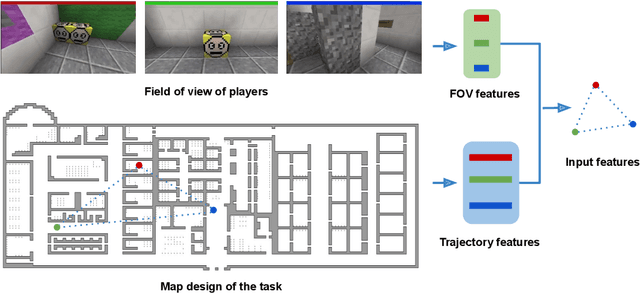
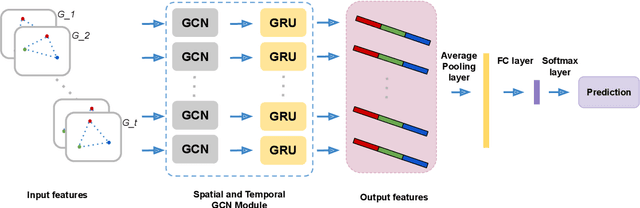
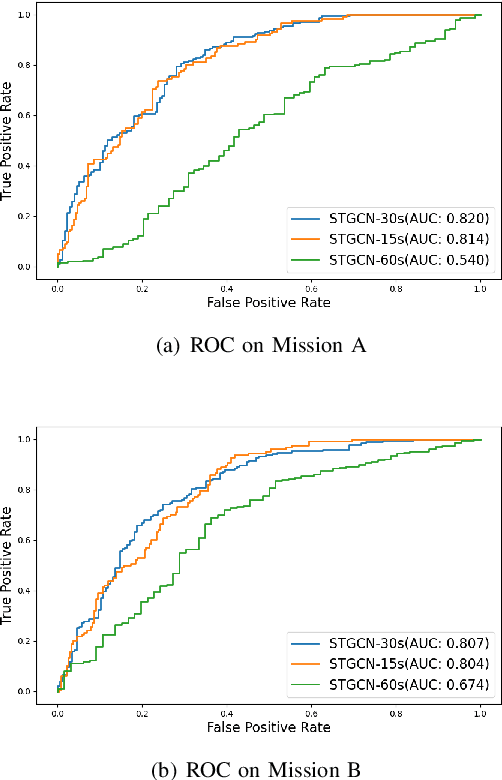
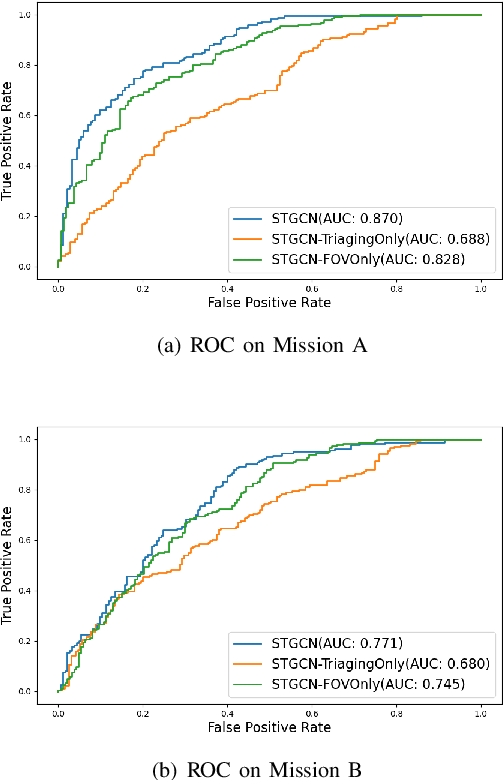
This paper presents a new approach for predicting team performance from the behavioral traces of a set of agents. This spatiotemporal forecasting problem is very relevant to sports analytics challenges such as coaching and opponent modeling. We demonstrate that our proposed model, Spatial Temporal Graph Convolutional Networks (ST-GCN), outperforms other classification techniques at predicting game score from a short segment of player movement and game features. Our proposed architecture uses a graph convolutional network to capture the spatial relationships between team members and Gated Recurrent Units to analyze dynamic motion information. An ablative evaluation was performed to demonstrate the contributions of different aspects of our architecture.
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
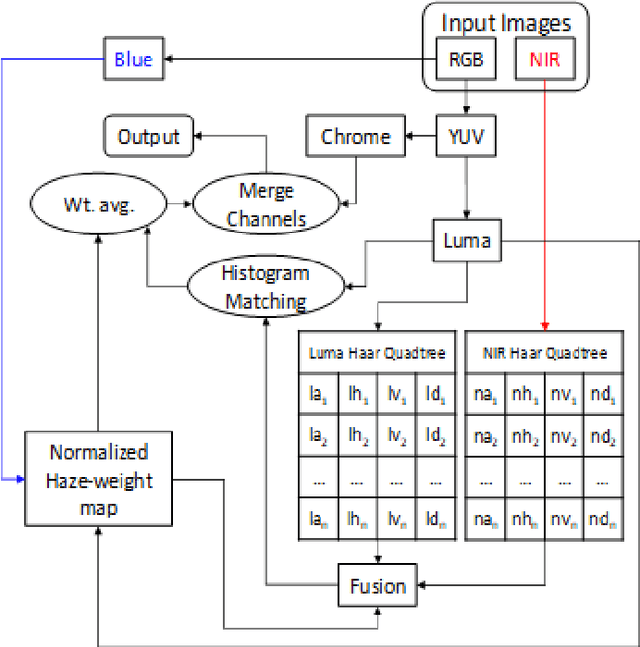
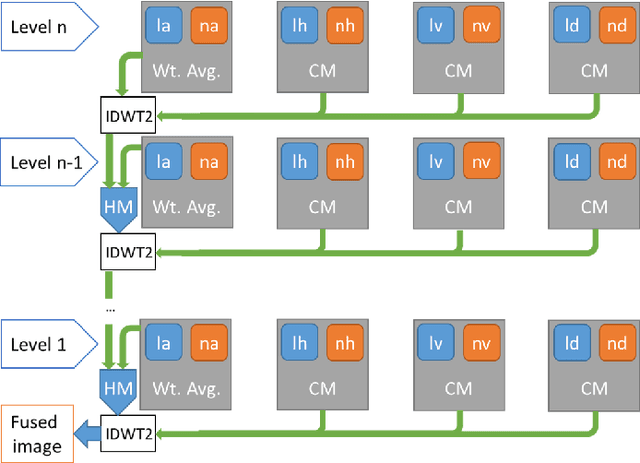
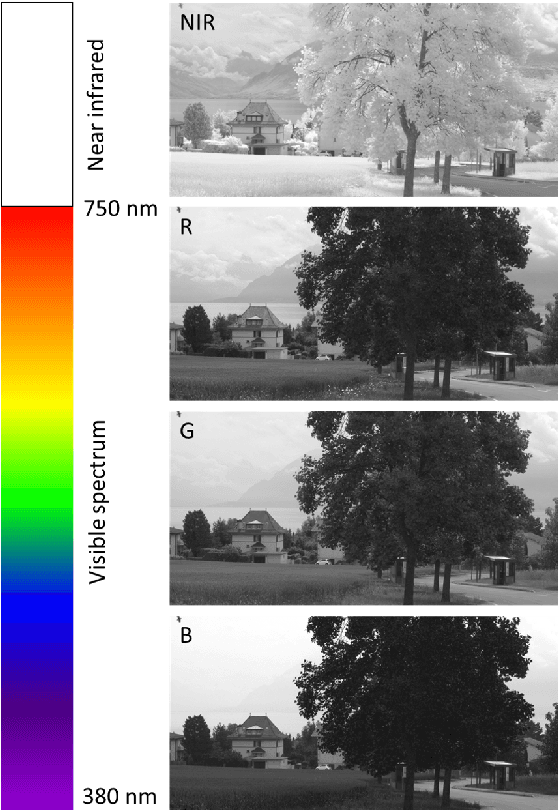
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Aug 19, 2020
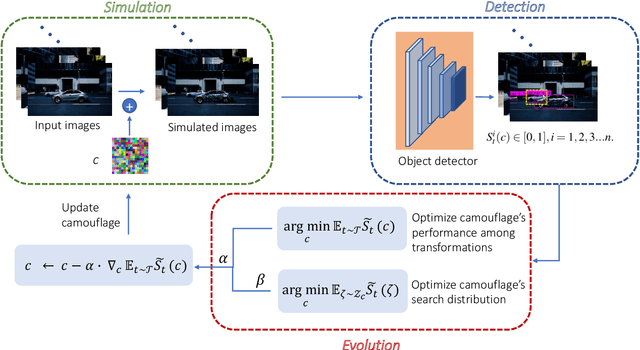
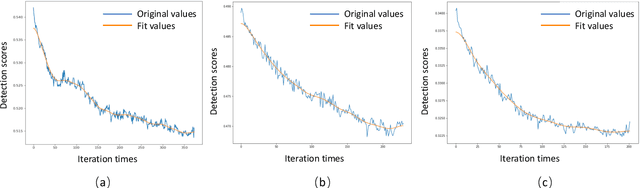
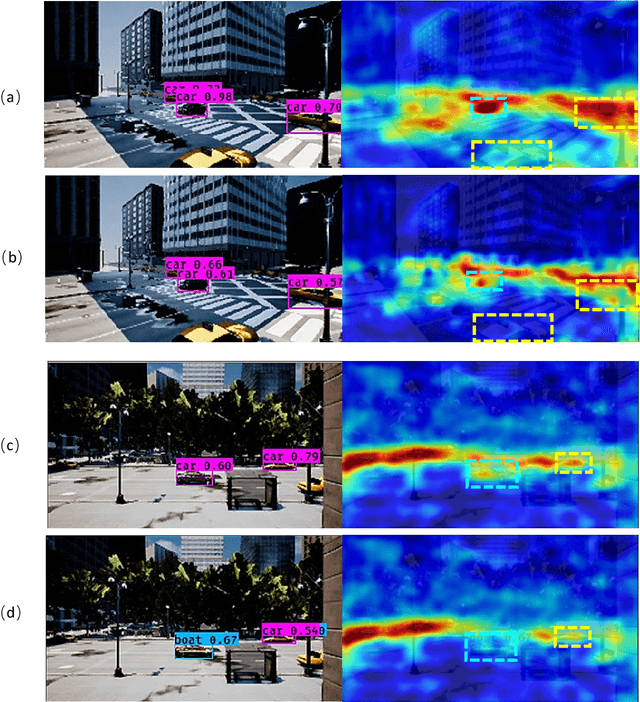
Deep neural network based object detection hasbecome the cornerstone of many real-world applications. Alongwith this success comes concerns about its vulnerability tomalicious attacks. To gain more insight into this issue, we proposea contextual camouflage attack (CCA for short) algorithm to in-fluence the performance of object detectors. In this paper, we usean evolutionary search strategy and adversarial machine learningin interactions with a photo-realistic simulated environment tofind camouflage patterns that are effective over a huge varietyof object locations, camera poses, and lighting conditions. Theproposed camouflages are validated effective to most of the state-of-the-art object detectors.
Learning Compact Appearance Representation for Video-based Person Re-Identification
Feb 21, 2017



This paper presents a novel approach for video-based person re-identification using multiple Convolutional Neural Networks (CNNs). Unlike previous work, we intend to extract a compact yet discriminative appearance representation from several frames rather than the whole sequence. Specifically, given a video, the representative frames are selected based on the walking profile of consecutive frames. A multiple CNN architecture incorporated with feature pooling is proposed to learn and compile the features of the selected representative frames into a compact description about the pedestrian for identification. Experiments are conducted on benchmark datasets to demonstrate the superiority of the proposed method over existing person re-identification approaches.