 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of Vision-Language Models for Content Moderation of Children's Videos
Paper and Code
Dec 06, 2023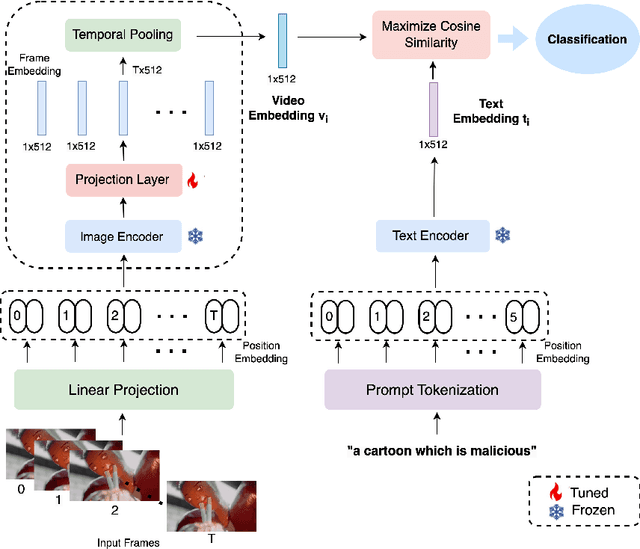

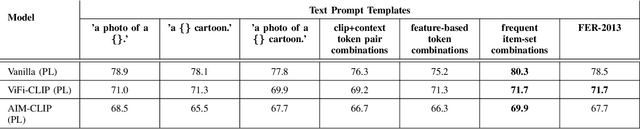
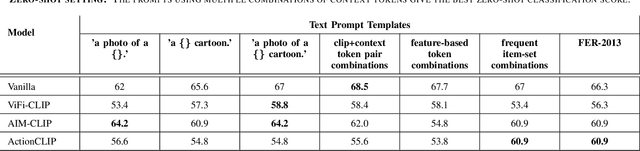
Natural language supervision has been shown to be effective for zero-shot learning in many computer vision tasks, such as object detection and activity recognition. However, generating informative prompts can be challenging for more subtle tasks, such as video content moderation. This can be difficult, as there are many reasons why a video might be inappropriate, beyond violence and obscenity. For example, scammers may attempt to create junk content that is similar to popular educational videos but with no meaningful information. This paper evaluates the performance of several CLIP variations for content moderation of children's cartoons in both the supervised and zero-shot setting. We show that our proposed model (Vanilla CLIP with Projection Layer) outperforms previous work conducted on the Malicious or Benign (MOB) benchmark for video content moderation. This paper presents an in depth analysis of how context-specific language prompts affect content moderation performance. Our results indicate that it is important to include more context in content moderation prompts, particularly for cartoon videos as they are not well represented in the CLIP training data.