 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM Reliability through Hybrid Abstention and Adaptive Detection
Feb 17, 2026Large Language Models (LLMs) deployed in production environments face a fundamental safety-utility trade-off either a strict filtering mechanisms prevent harmful outputs but often block benign queries or a relaxed controls risk unsafe content generation. Conventional guardrails based on static rules or fixed confidence thresholds are typically context-insensitive and computationally expensive, resulting in high latency and degraded user experience. To address these limitations, we introduce an adaptive abstention system that dynamically adjusts safety thresholds based on real-time contextual signals such as domain and user history. The proposed framework integrates a multi-dimensional detection architecture composed of five parallel detectors, combined through a hierarchical cascade mechanism to optimize both speed and precision. The cascade design reduces unnecessary computation by progressively filtering queries, achieving substantial latency improvements compared to non-cascaded models and external guardrail systems. Extensive evaluation on mixed and domain-specific workloads demonstrates significant reductions in false positives, particularly in sensitive domains such as medical advice and creative writing. The system maintains high safety precision and near-perfect recall under strict operating modes. Overall, our context-aware abstention framework effectively balances safety and utility while preserving performance, offering a scalable solution for reliable LLM deployment.
LightTopoGAT: Enhancing Graph Attention Networks with Topological Features for Efficient Graph Classification
Dec 15, 2025
Graph Neural Networks have demonstrated significant success in graph classification tasks, yet they often require substantial computational resources and struggle to capture global graph properties effectively. We introduce LightTopoGAT, a lightweight graph attention network that enhances node features through topological augmentation by incorporating node degree and local clustering coefficient to improve graph representation learning. The proposed approach maintains parameter efficiency through streamlined attention mechanisms while integrating structural information that is typically overlooked by local message passing schemes. Through comprehensive experiments on three benchmark datasets, MUTAG, ENZYMES, and PROTEINS, we show that LightTopoGAT achieves superior performance compared to established baselines including GCN, GraphSAGE, and standard GAT, with a 6.6 percent improvement in accuracy on MUTAG and a 2.2 percent improvement on PROTEINS. Ablation studies further confirm that these performance gains arise directly from the inclusion of topological features, demonstrating a simple yet effective strategy for enhancing graph neural network performance without increasing architectural complexity.
Automated Detection and Analysis of Minor Deformations in Flat Walls Due to Railway Vibrations Using LiDAR and Machine Learning
Jan 14, 2025This study introduces an advanced methodology for automatically identifying minor deformations in flat walls caused by vibrations from nearby railway tracks. It leverages high-density Terrestrial Laser Scanner (TLS) LiDAR surveys and AI/ML techniques to collect and analyze data. The scan data is processed into a detailed point cloud, which is segmented to distinguish ground points, trees, buildings, and other objects. The analysis focuses on identifying sections along flat walls and estimating their deformations relative to the ground orientation. Findings from the study, conducted at the RGIPT campus, reveal significant deformations in walls close to the railway corridor, with the highest deformations ranging from 7 to 8 cm and an average of 3 to 4 cm. In contrast, walls further from the corridor show negligible deformations. The developed automated process for feature extraction and deformation monitoring demonstrates potential for structural health monitoring. By integrating LiDAR data with machine learning, the methodology provides an efficient system for identifying and analyzing structural deformations, highlighting the importance of continuous monitoring for ensuring structural integrity and public safety in urban infrastructure. This approach represents a substantial advancement in automated feature extraction and deformation analysis, contributing to more effective management of urban infrastructure.
* I am requesting the withdrawal of my paper due to the need for significant revisions to ensure the accuracy and integrity of the presented findings
Automatic Detection of Signalling Behaviour from Assistance Dogs as they Forecast the Onset of Epileptic Seizures in Humans
Mar 11, 2023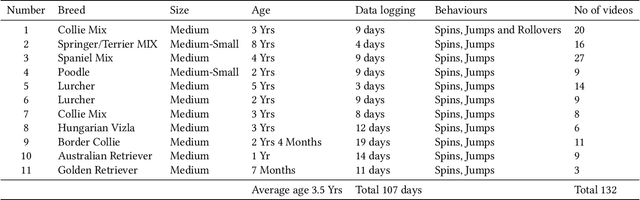
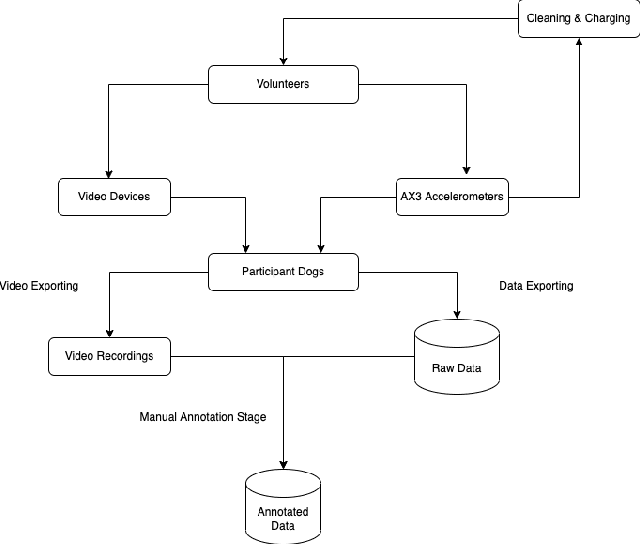
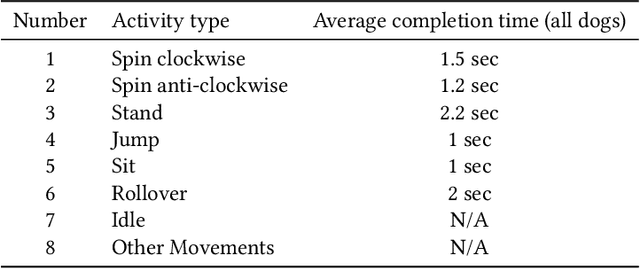
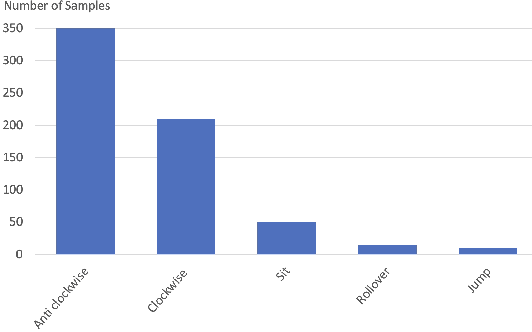
Epilepsy or the occurrence of epileptic seizures, is one of the world's most well-known neurological disorders affecting millions of people. Seizures mostly occur due to non-coordinated electrical discharges in the human brain and may cause damage, including collapse and loss of consciousness. If the onset of a seizure can be forecast then the subject can be placed into a safe environment or position so that self-injury as a result of a collapse can be minimised. However there are no definitive methods to predict seizures in an everyday, uncontrolled environment. Previous studies have shown that pet dogs have the ability to detect the onset of an epileptic seizure by scenting the characteristic volatile organic compounds exuded through the skin by a subject prior a seizure occurring and there are cases where assistance dogs, trained to scent the onset of a seizure, can signal this to their owner/trainer. In this work we identify how we can automatically detect the signalling behaviours of trained assistance dogs and use this to alert their owner. Using data from an accelerometer worn on the collar of a dog we describe how we gathered movement data from 11 trained dogs for a total of 107 days as they exhibited signalling behaviour on command. We present the machine learning techniques used to accurately detect signalling from routine dog behaviour. This work is a step towards automatic alerting of the likely onset of an epileptic seizure from the signalling behaviour of a trained assistance dog.
* 8 pages, 5 tables, 6 figures
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
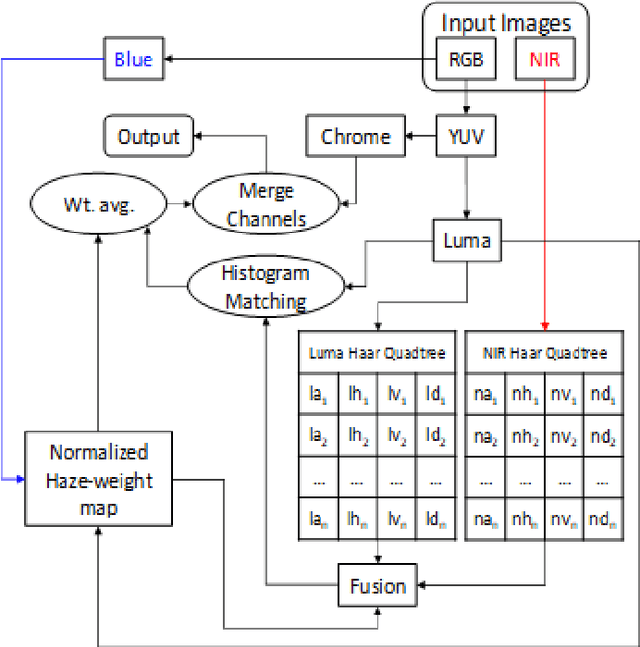
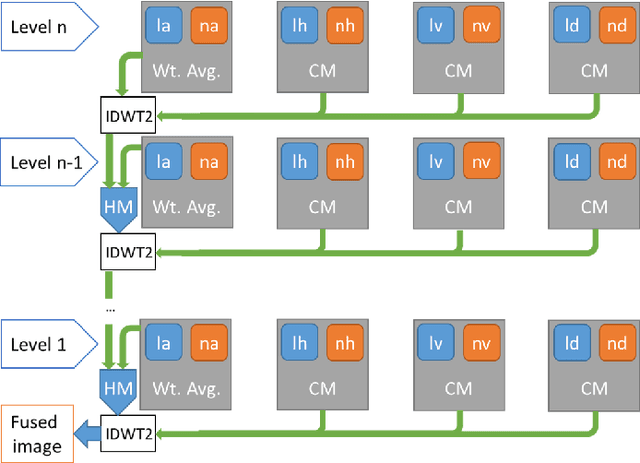
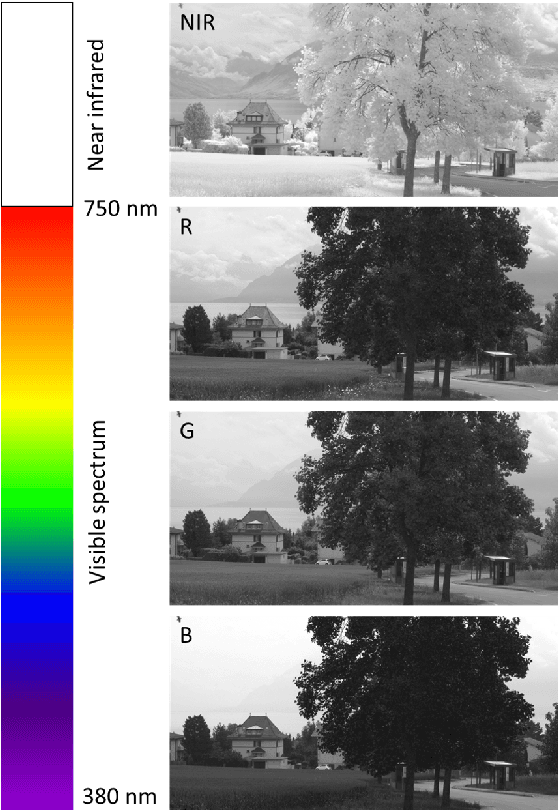
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
Towards Consistent Predictive Confidence through Fitted Ensembles
Jun 22, 2021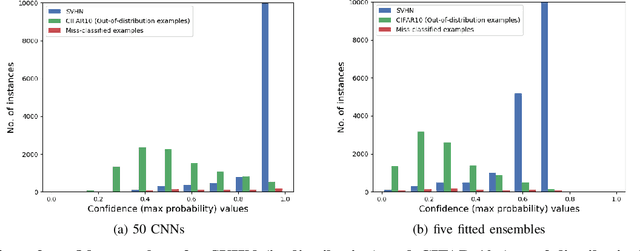
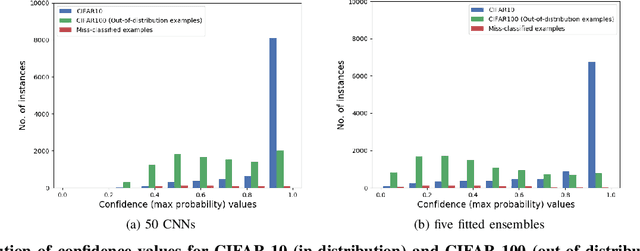
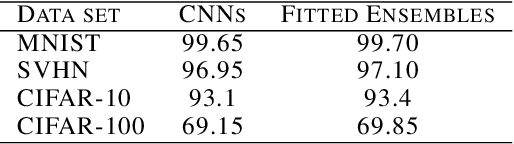

Deep neural networks are behind many of the recent successes in machine learning applications. However, these models can produce overconfident decisions while encountering out-of-distribution (OOD) examples or making a wrong prediction. This inconsistent predictive confidence limits the integration of independently-trained learning models into a larger system. This paper introduces separable concept learning framework to realistically measure the performance of classifiers in presence of OOD examples. In this setup, several instances of a classifier are trained on different parts of a partition of the set of classes. Later, the performance of the combination of these models is evaluated on a separate test set. Unlike current OOD detection techniques, this framework does not require auxiliary OOD datasets and does not separate classification from detection performance. Furthermore, we present a new strong baseline for more consistent predictive confidence in deep models, called fitted ensembles, where overconfident predictions are rectified by transformed versions of the original classification task. Fitted ensembles can naturally detect OOD examples without requiring auxiliary data by observing contradicting predictions among its components. Experiments on MNIST, SVHN, CIFAR-10/100, and ImageNet show fitted ensemble significantly outperform conventional ensembles on OOD examples and are possible to scale.
Parallelized Instantaneous Velocity and Heading Estimation of Objects using Single Imaging Radar
Dec 23, 2020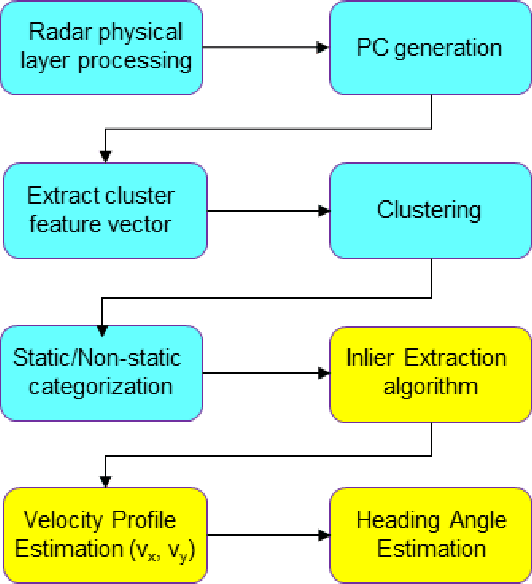

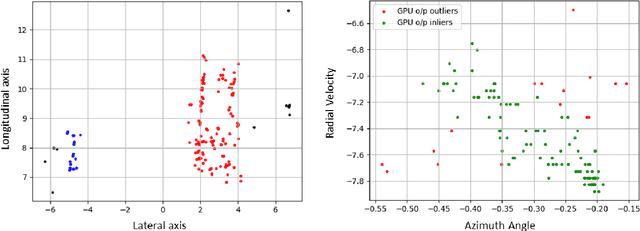

The development of high-resolution imaging radars introduce a plethora of useful applications, particularly in the automotive sector. With increasing attention on active transport safety and autonomous driving, these imaging radars are set to form the core of an autonomous engine. One of the most important tasks of such high-resolution radars is to estimate the instantaneous velocities and heading angles of the detected objects (vehicles, pedestrians, etc.). Feasible estimation methods should be fast enough in real-time scenarios, bias-free and robust against micro-Dopplers, noise and other systemic variations. This work proposes a parallel-computing scheme that achieves a real-time and accurate implementation of vector velocity determination using frequency modulated continuous wave (FMCW) radars. The proposed scheme is tested against traffic data collected using an FMCW radar at a center frequency of 78.6 GHz and a bandwidth of 4 GHz. Experiments show that the parallel algorithm presented performs much faster than its conventional counterparts without any loss in precision.
Hi-CI: Deep Causal Inference in High Dimensions
Aug 22, 2020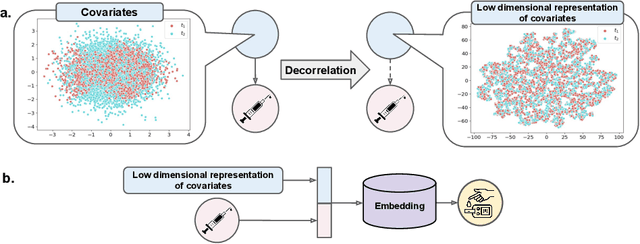
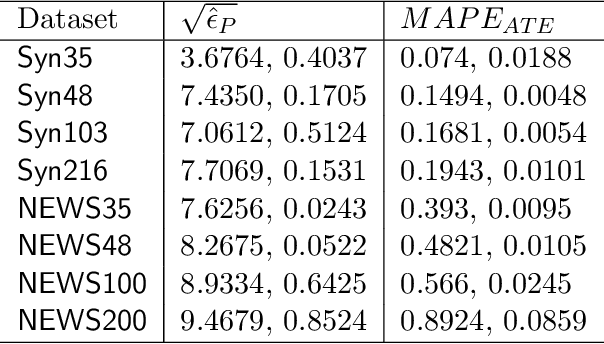
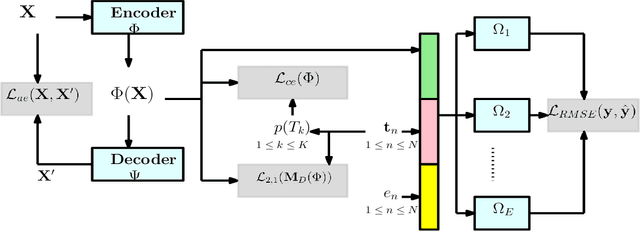
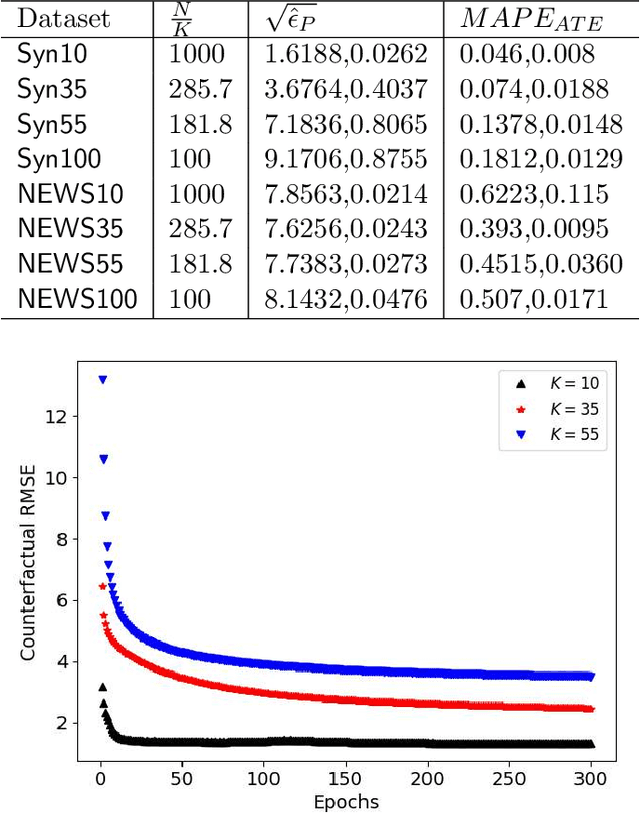
We address the problem of counterfactual regression using causal inference (CI) in observational studies consisting of high dimensional covariates and high cardinality treatments. Confounding bias, which leads to inaccurate treatment effect estimation, is attributed to covariates that affect both treatments and outcome. The presence of high-dimensional co-variates exacerbates the impact of bias as it is harder to isolate and measure the impact of these confounders. In the presence of high-cardinality treatment variables, CI is rendered ill-posed due to the increase in the number of counterfactual outcomes to be predicted. We propose Hi-CI, a deep neural network (DNN) based framework for estimating causal effects in the presence of large number of covariates, and high-cardinal and continuous treatment variables. The proposed architecture comprises of a decorrelation network and an outcome prediction network. In the decorrelation network, we learn a data representation in lower dimensions as compared to the original covariates and addresses confounding bias alongside. Subsequently, in the outcome prediction network, we learn an embedding of high-cardinality and continuous treatments, jointly with the data representation. We demonstrate the efficacy of causal effect prediction of the proposed Hi-CI network using synthetic and real-world NEWS datasets.
CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Aug 19, 2020
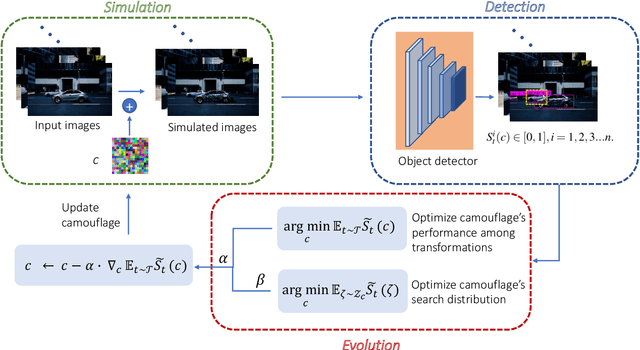
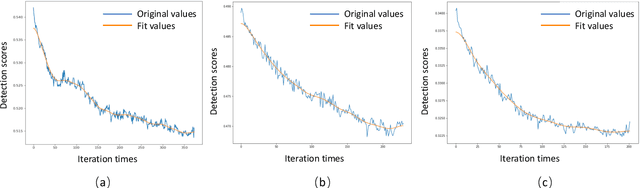
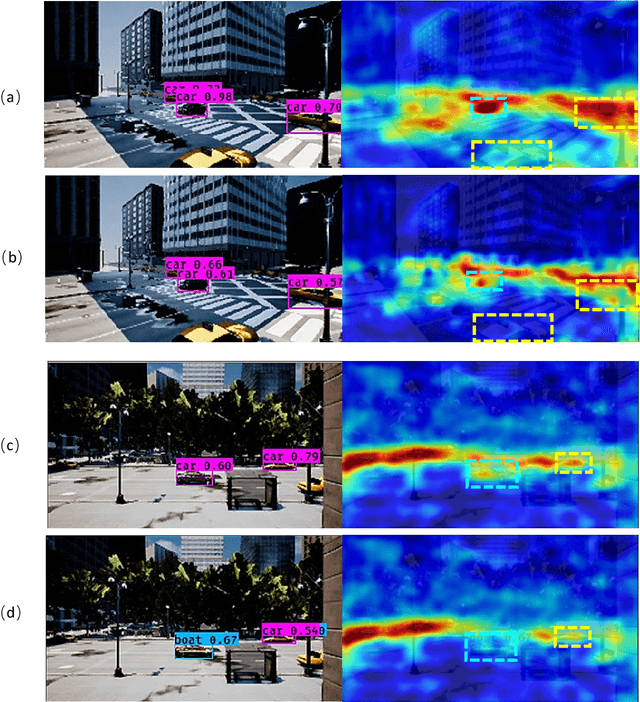
Deep neural network based object detection hasbecome the cornerstone of many real-world applications. Alongwith this success comes concerns about its vulnerability tomalicious attacks. To gain more insight into this issue, we proposea contextual camouflage attack (CCA for short) algorithm to in-fluence the performance of object detectors. In this paper, we usean evolutionary search strategy and adversarial machine learningin interactions with a photo-realistic simulated environment tofind camouflage patterns that are effective over a huge varietyof object locations, camera poses, and lighting conditions. Theproposed camouflages are validated effective to most of the state-of-the-art object detectors.
MultiMBNN: Matched and Balanced Causal Inference with Neural Networks
Apr 29, 2020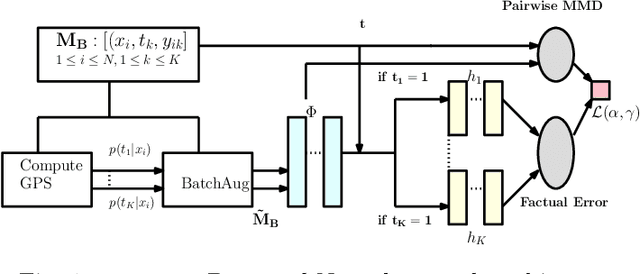
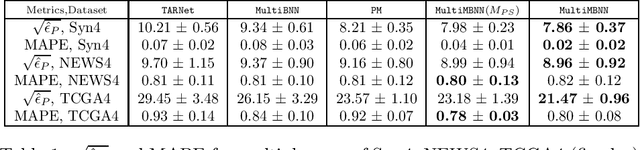
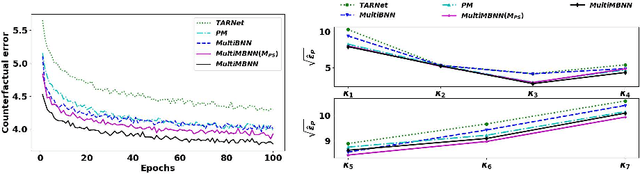
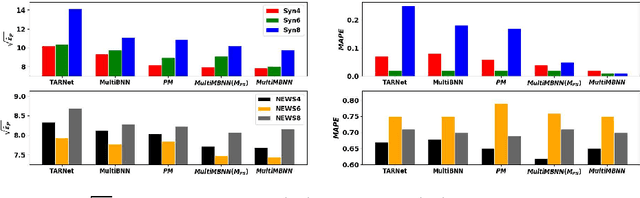
Causal inference (CI) in observational studies has received a lot of attention in healthcare, education, ad attribution, policy evaluation, etc. Confounding is a typical hazard, where the context affects both, the treatment assignment and response. In a multiple treatment scenario, we propose the neural network based MultiMBNN, where we overcome confounding by employing generalized propensity score based matching, and learning balanced representations. We benchmark the performance on synthetic and real-world datasets using PEHE, and mean absolute percentage error over ATE as metrics. MultiMBNN outperforms the state-of-the-art algorithms for CI such as TARNet and Perfect Match (PM).