 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis
May 16, 2025Much of the excitement in modern AI is driven by the observation that scaling up existing systems leads to better performance. But does better performance necessarily imply better internal representations? While the representational optimist assumes it must, this position paper challenges that view. We compare neural networks evolved through an open-ended search process to networks trained via conventional stochastic gradient descent (SGD) on the simple task of generating a single image. This minimal setup offers a unique advantage: each hidden neuron's full functional behavior can be easily visualized as an image, thus revealing how the network's output behavior is internally constructed neuron by neuron. The result is striking: while both networks produce the same output behavior, their internal representations differ dramatically. The SGD-trained networks exhibit a form of disorganization that we term fractured entangled representation (FER). Interestingly, the evolved networks largely lack FER, even approaching a unified factored representation (UFR). In large models, FER may be degrading core model capacities like generalization, creativity, and (continual) learning. Therefore, understanding and mitigating FER could be critical to the future of representation learning.
Automating the Search for Artificial Life with Foundation Models
Dec 23, 2024



With the recent Nobel Prize awarded for radical advances in protein discovery, foundation models (FMs) for exploring large combinatorial spaces promise to revolutionize many scientific fields. Artificial Life (ALife) has not yet integrated FMs, thus presenting a major opportunity for the field to alleviate the historical burden of relying chiefly on manual design and trial-and-error to discover the configurations of lifelike simulations. This paper presents, for the first time, a successful realization of this opportunity using vision-language FMs. The proposed approach, called Automated Search for Artificial Life (ASAL), (1) finds simulations that produce target phenomena, (2) discovers simulations that generate temporally open-ended novelty, and (3) illuminates an entire space of interestingly diverse simulations. Because of the generality of FMs, ASAL works effectively across a diverse range of ALife substrates including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. A major result highlighting the potential of this technique is the discovery of previously unseen Lenia and Boids lifeforms, as well as cellular automata that are open-ended like Conway's Game of Life. Additionally, the use of FMs allows for the quantification of previously qualitative phenomena in a human-aligned way. This new paradigm promises to accelerate ALife research beyond what is possible through human ingenuity alone.
Evolution through Large Models
Jun 17, 2022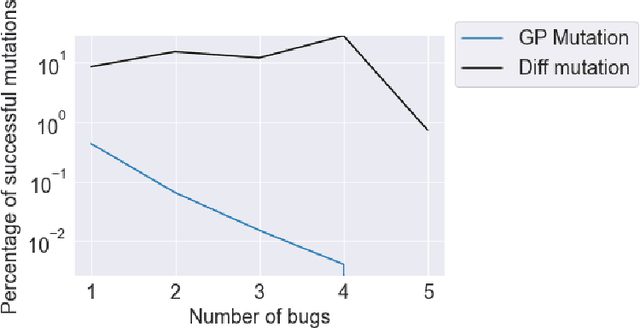
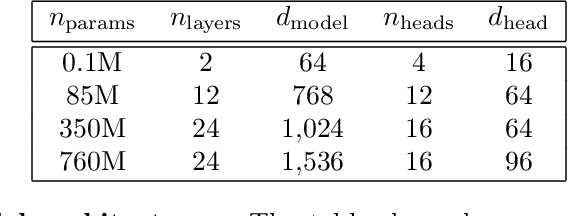
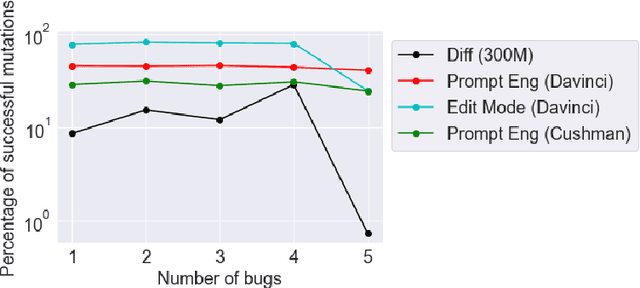
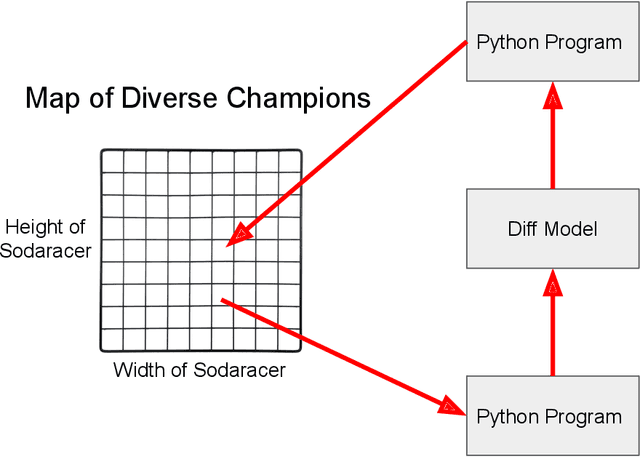
This paper pursues the insight that large language models (LLMs) trained to generate code can vastly improve the effectiveness of mutation operators applied to programs in genetic programming (GP). Because such LLMs benefit from training data that includes sequential changes and modifications, they can approximate likely changes that humans would make. To highlight the breadth of implications of such evolution through large models (ELM), in the main experiment ELM combined with MAP-Elites generates hundreds of thousands of functional examples of Python programs that output working ambulating robots in the Sodarace domain, which the original LLM had never seen in pre-training. These examples then help to bootstrap training a new conditional language model that can output the right walker for a particular terrain. The ability to bootstrap new models that can output appropriate artifacts for a given context in a domain where zero training data was previously available carries implications for open-endedness, deep learning, and reinforcement learning. These implications are explored here in depth in the hope of inspiring new directions of research now opened up by ELM.
Towards Consistent Predictive Confidence through Fitted Ensembles
Jun 22, 2021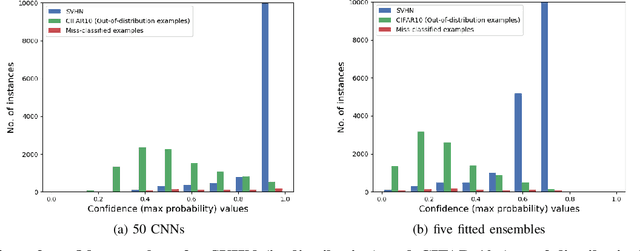
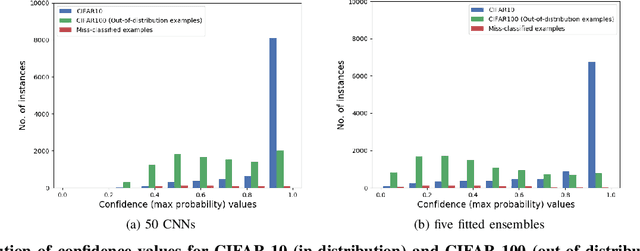
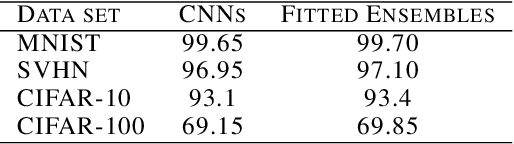

Deep neural networks are behind many of the recent successes in machine learning applications. However, these models can produce overconfident decisions while encountering out-of-distribution (OOD) examples or making a wrong prediction. This inconsistent predictive confidence limits the integration of independently-trained learning models into a larger system. This paper introduces separable concept learning framework to realistically measure the performance of classifiers in presence of OOD examples. In this setup, several instances of a classifier are trained on different parts of a partition of the set of classes. Later, the performance of the combination of these models is evaluated on a separate test set. Unlike current OOD detection techniques, this framework does not require auxiliary OOD datasets and does not separate classification from detection performance. Furthermore, we present a new strong baseline for more consistent predictive confidence in deep models, called fitted ensembles, where overconfident predictions are rectified by transformed versions of the original classification task. Fitted ensembles can naturally detect OOD examples without requiring auxiliary data by observing contradicting predictions among its components. Experiments on MNIST, SVHN, CIFAR-10/100, and ImageNet show fitted ensemble significantly outperform conventional ensembles on OOD examples and are possible to scale.
Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search
May 27, 2020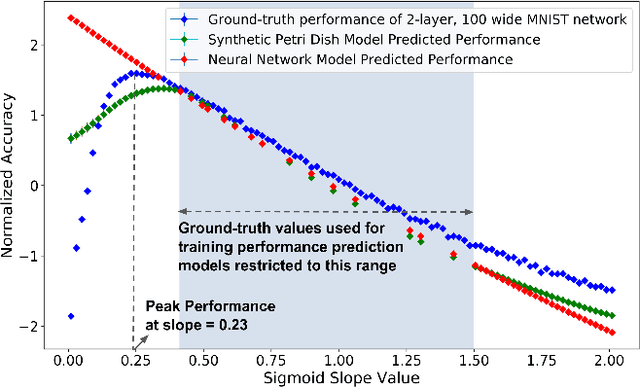
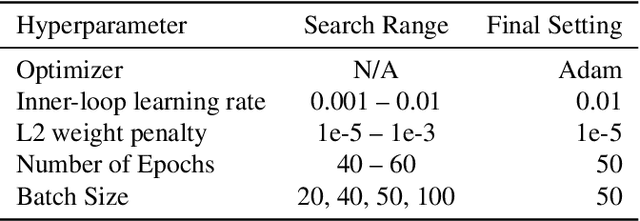
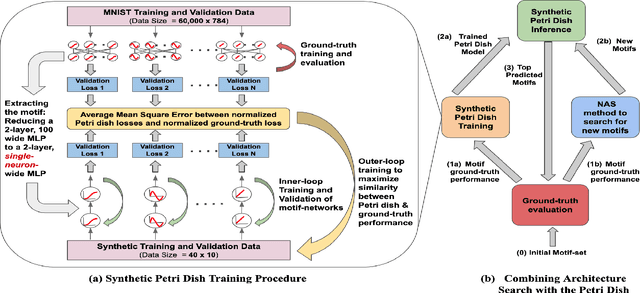
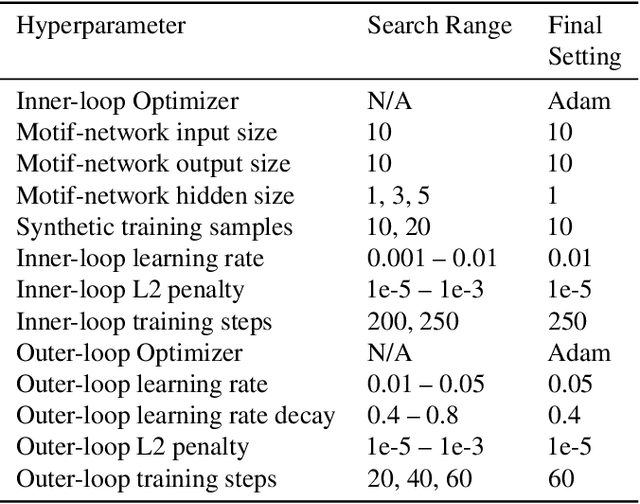
Neural Architecture Search (NAS) explores a large space of architectural motifs -- a compute-intensive process that often involves ground-truth evaluation of each motif by instantiating it within a large network, and training and evaluating the network with thousands of domain-specific data samples. Inspired by how biological motifs such as cells are sometimes extracted from their natural environment and studied in an artificial Petri dish setting, this paper proposes the Synthetic Petri Dish model for evaluating architectural motifs. In the Synthetic Petri Dish, architectural motifs are instantiated in very small networks and evaluated using very few learned synthetic data samples (to effectively approximate performance in the full problem). The relative performance of motifs in the Synthetic Petri Dish can substitute for their ground-truth performance, thus accelerating the most expensive step of NAS. Unlike other neural network-based prediction models that parse the structure of the motif to estimate its performance, the Synthetic Petri Dish predicts motif performance by training the actual motif in an artificial setting, thus deriving predictions from its true intrinsic properties. Experiments in this paper demonstrate that the Synthetic Petri Dish can therefore predict the performance of new motifs with significantly higher accuracy, especially when insufficient ground truth data is available. Our hope is that this work can inspire a new research direction in studying the performance of extracted components of models in an alternative controlled setting.
First return then explore
May 14, 2020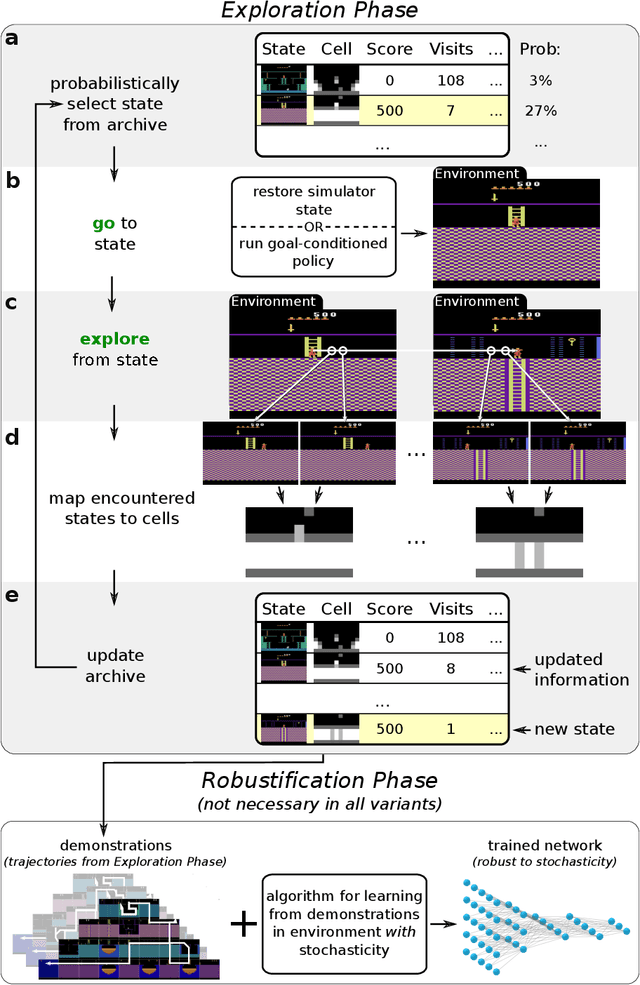
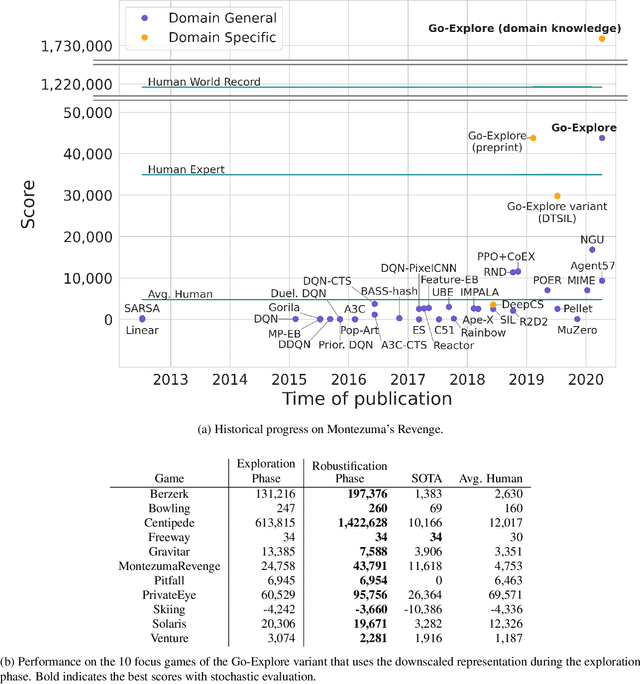
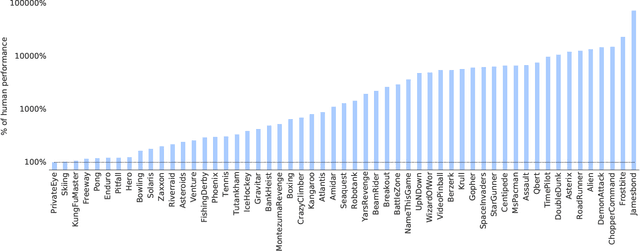
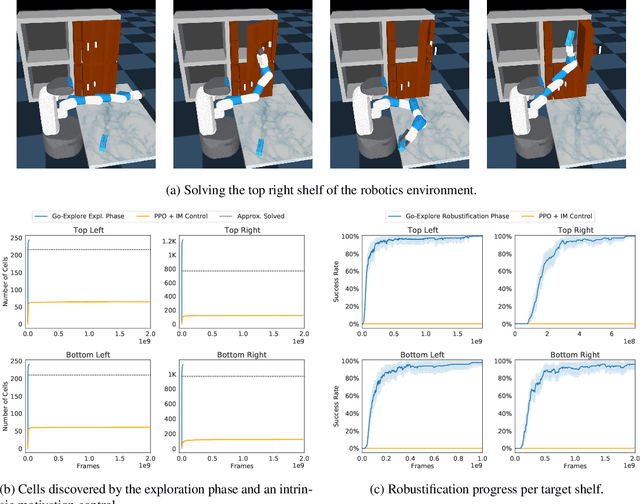
The promise of reinforcement learning is to solve complex sequential decision problems by specifying a high-level reward function only. However, RL algorithms struggle when, as is often the case, simple and intuitive rewards provide sparse and deceptive feedback. Avoiding these pitfalls requires thoroughly exploring the environment, but despite substantial investments by the community, creating algorithms that can do so remains one of the central challenges of the field. We hypothesize that the main impediment to effective exploration originates from algorithms forgetting how to reach previously visited states ("detachment") and from failing to first return to a state before exploring from it ("derailment"). We introduce Go-Explore, a family of algorithms that addresses these two challenges directly through the simple principles of explicitly remembering promising states and first returning to such states before exploring. Go-Explore solves all heretofore unsolved Atari games (those for which algorithms could not previously outperform humans when evaluated following current community standards) and surpasses the state of the art on all hard-exploration games, with orders of magnitude improvements on the grand challenges Montezuma's Revenge and Pitfall. We also demonstrate the practical potential of Go-Explore on a challenging and extremely sparse-reward robotics task. Additionally, we show that adding a goal-conditioned policy can further improve Go-Explore's exploration efficiency and enable it to handle stochasticity throughout training. The striking contrast between the substantial performance gains from Go-Explore and the simplicity of its mechanisms suggests that remembering promising states, returning to them, and exploring from them is a powerful and general approach to exploration, an insight that may prove critical to the creation of truly intelligent learning agents.
Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions
Apr 13, 2020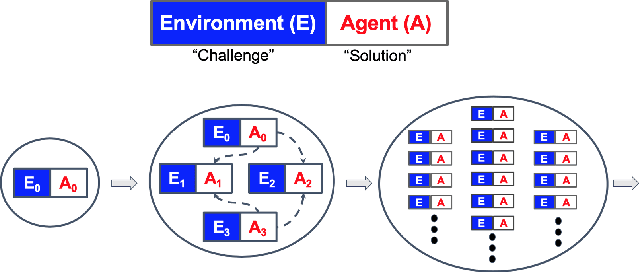

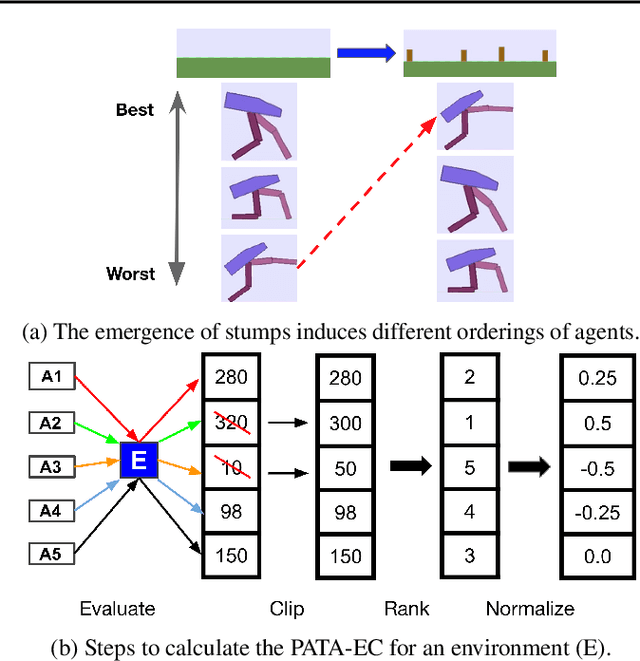
Creating open-ended algorithms, which generate their own never-ending stream of novel and appropriately challenging learning opportunities, could help to automate and accelerate progress in machine learning. A recent step in this direction is the Paired Open-Ended Trailblazer (POET), an algorithm that generates and solves its own challenges, and allows solutions to goal-switch between challenges to avoid local optima. However, the original POET was unable to demonstrate its full creative potential because of limitations of the algorithm itself and because of external issues including a limited problem space and lack of a universal progress measure. Importantly, both limitations pose impediments not only for POET, but for the pursuit of open-endedness in general. Here we introduce and empirically validate two new innovations to the original algorithm, as well as two external innovations designed to help elucidate its full potential. Together, these four advances enable the most open-ended algorithmic demonstration to date. The algorithmic innovations are (1) a domain-general measure of how meaningfully novel new challenges are, enabling the system to potentially create and solve interesting challenges endlessly, and (2) an efficient heuristic for determining when agents should goal-switch from one problem to another (helping open-ended search better scale). Outside the algorithm itself, to enable a more definitive demonstration of open-endedness, we introduce (3) a novel, more flexible way to encode environmental challenges, and (4) a generic measure of the extent to which a system continues to exhibit open-ended innovation. Enhanced POET produces a diverse range of sophisticated behaviors that solve a wide range of environmental challenges, many of which cannot be solved through other means.
Fiber: A Platform for Efficient Development and Distributed Training for Reinforcement Learning and Population-Based Methods
Mar 25, 2020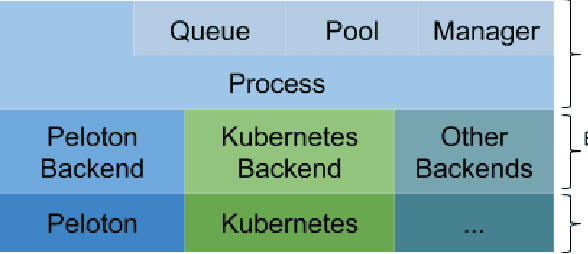
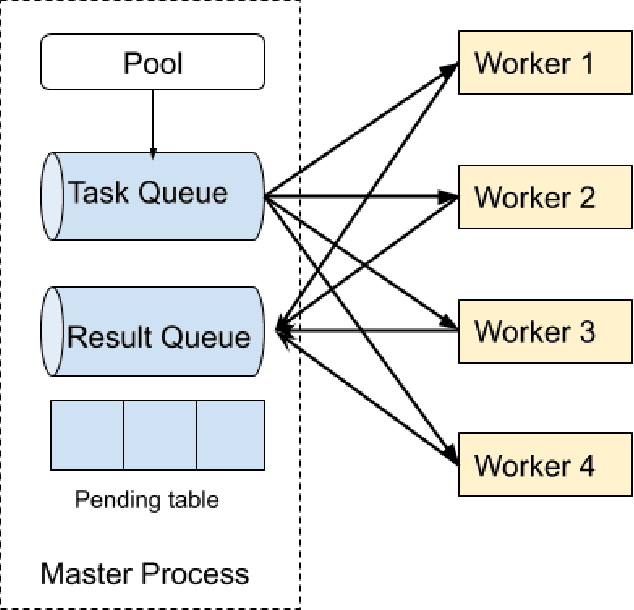
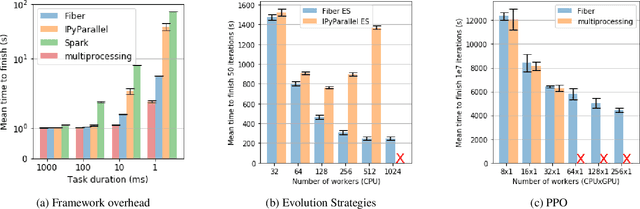
Recent advances in machine learning are consistently enabled by increasing amounts of computation. Reinforcement learning (RL) and population-based methods in particular pose unique challenges for efficiency and flexibility to the underlying distributed computing frameworks. These challenges include frequent interaction with simulations, the need for dynamic scaling, and the need for a user interface with low adoption cost and consistency across different backends. In this paper we address these challenges while still retaining development efficiency and flexibility for both research and practical applications by introducing Fiber, a scalable distributed computing framework for RL and population-based methods. Fiber aims to significantly expand the accessibility of large-scale parallel computation to users of otherwise complicated RL and population-based approaches without the need to for specialized computational expertise.
Learning to Continually Learn
Mar 04, 2020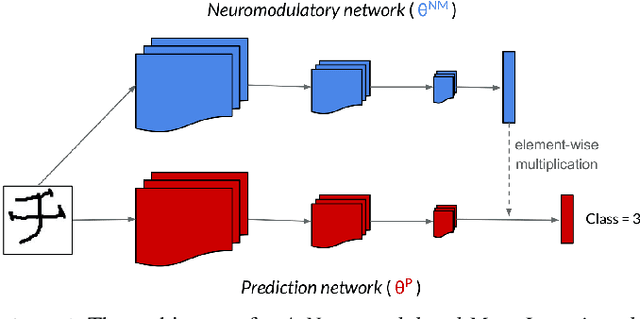
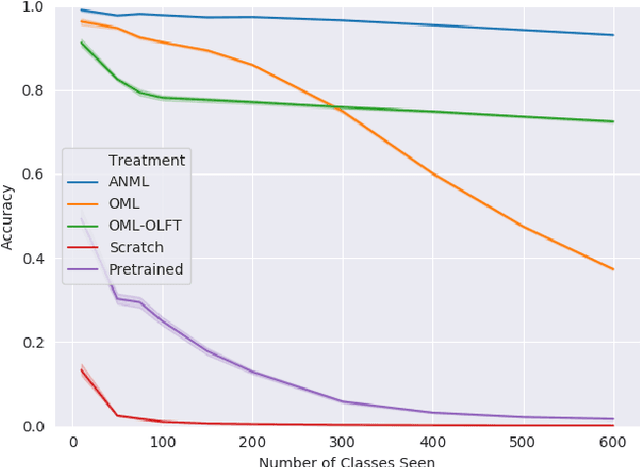
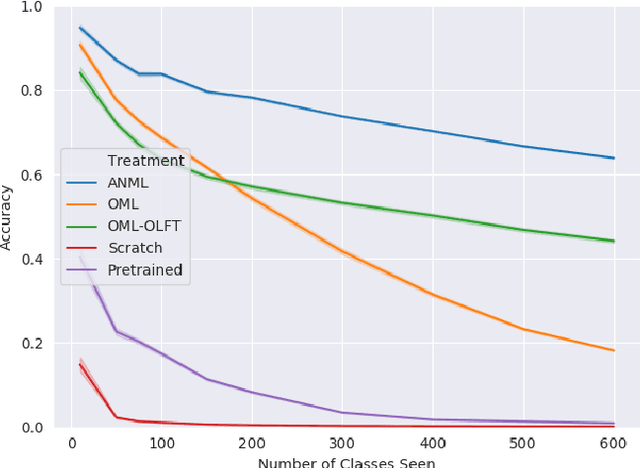
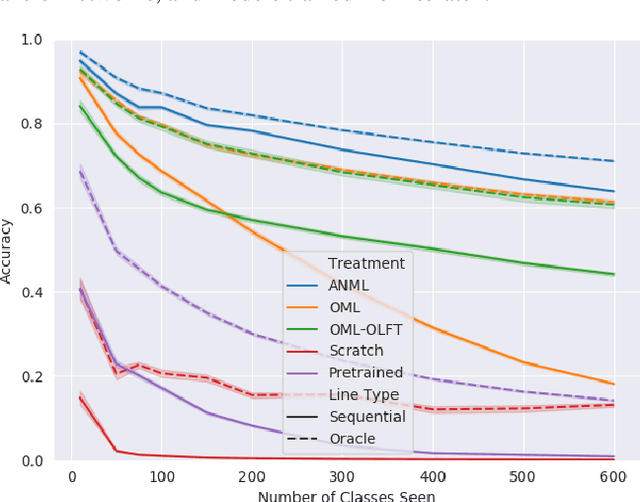
Continual lifelong learning requires an agent or model to learn many sequentially ordered tasks, building on previous knowledge without catastrophically forgetting it. Much work has gone towards preventing the default tendency of machine learning models to catastrophically forget, yet virtually all such work involves manually-designed solutions to the problem. We instead advocate meta-learning a solution to catastrophic forgetting, allowing AI to learn to continually learn. Inspired by neuromodulatory processes in the brain, we propose A Neuromodulated Meta-Learning Algorithm (ANML). It differentiates through a sequential learning process to meta-learn an activation-gating function that enables context-dependent selective activation within a deep neural network. Specifically, a neuromodulatory (NM) neural network gates the forward pass of another (otherwise normal) neural network called the prediction learning network (PLN). The NM network also thus indirectly controls selective plasticity (i.e. the backward pass of) the PLN. ANML enables continual learning without catastrophic forgetting at scale: it produces state-of-the-art continual learning performance, sequentially learning as many as 600 classes (over 9,000 SGD updates).
Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity
Feb 24, 2020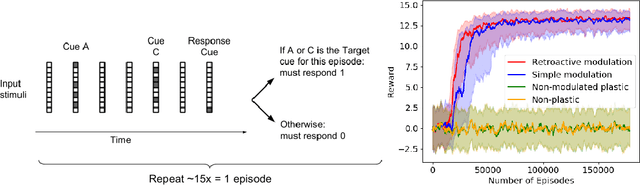

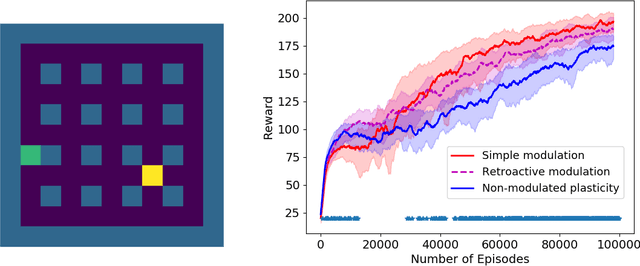
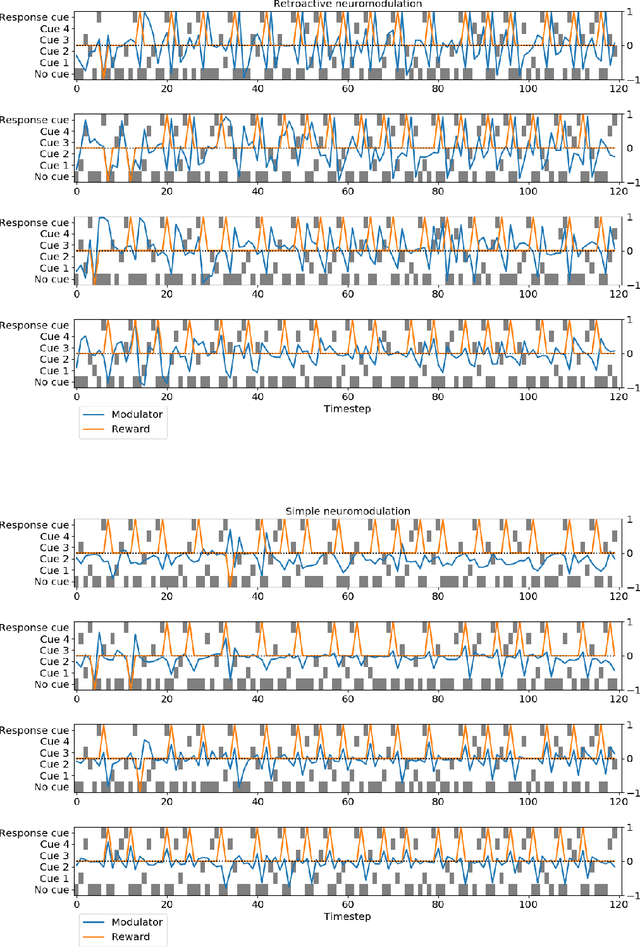
The impressive lifelong learning in animal brains is primarily enabled by plastic changes in synaptic connectivity. Importantly, these changes are not passive, but are actively controlled by neuromodulation, which is itself under the control of the brain. The resulting self-modifying abilities of the brain play an important role in learning and adaptation, and are a major basis for biological reinforcement learning. Here we show for the first time that artificial neural networks with such neuromodulated plasticity can be trained with gradient descent. Extending previous work on differentiable Hebbian plasticity, we propose a differentiable formulation for the neuromodulation of plasticity. We show that neuromodulated plasticity improves the performance of neural networks on both reinforcement learning and supervised learning tasks. In one task, neuromodulated plastic LSTMs with millions of parameters outperform standard LSTMs on a benchmark language modeling task (controlling for the number of parameters). We conclude that differentiable neuromodulation of plasticity offers a powerful new framework for training neural networks.
* Presented at the 7th International Conference on Learning Representations (ICLR 2019)