 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCortex-Inspired Continual Learning: Unsupervised Instantiation and Recovery of Functional Task Networks
Apr 27, 2026Block-sequential continual learning demands that a single model both protect prior solutions from catastrophic forgetting and efficiently infer at inference time which prior solution matches the current input without task labels. We present Functional Task Networks (FTN), a parameter-isolation method inspired by structural and dynamical motifs found in the mammalian neocortex. Similar to mixture-of-experts, this method uses a high dimensional, self-organizing binary mask over a large population of small but deep networks, inspired by dendritic models of pyramidal neurons. The mask is produced by a three-stage procedure: (1) gradient descent on a continuous mask identifies task-relevant neurons, (2) a smoothing kernel biases the result toward spatial contiguity, (3) and k-winner-take-all binarizes the resulting group at a fixed capacity budget. Like mixture-of-experts, each neuron is an independent deep network, so disjoint masks give exactly disjoint gradient updates, providing structural guarantees against catastrophic forgetting. This three-stage procedure recovers the sub-network of a previously-trained task in a single gradient step, providing unsupervised task segmentation at inference time. We test it on three continual-learning benchmarks: (1) a synthetic multi-task classification/regression generator, (2) MNIST with shuffled class labels (pure concept shift), and (3) Permuted MNIST (domain shift). On all three, FTN with fine grained smoothing (FTN-Slow) results in nearly zero forgetting. FTN with a large kernel and only 2 iterations of smoothing (FTN-Fast) trades off some retention for increased speed. We show that the spatial organization mechanism reduces the effective mask search from the combinatorial top-k subset problem in O(C(H,K)) to the complexity of a near-linear scan in O(H) over compact cortical neighborhoods, which is parallelized by the gradient-based update.
Thinking agents for zero-shot generalization to qualitatively novel tasks
Mar 25, 2025



Intelligent organisms can solve truly novel problems which they have never encountered before, either in their lifetime or their evolution. An important component of this capacity is the ability to ``think'', that is, to mentally manipulate objects, concepts and behaviors in order to plan and evaluate possible solutions to novel problems, even without environment interaction. To generate problems that are truly qualitatively novel, while still solvable zero-shot (by mental simulation), we use the combinatorial nature of environments: we train the agent while withholding a specific combination of the environment's elements. The novel test task, based on this combination, is thus guaranteed to be truly novel, while still mentally simulable since the agent has been exposed to each individual element (and their pairwise interactions) during training. We propose a method to train agents endowed with world models to make use their mental simulation abilities, by selecting tasks based on the difference between the agent's pre-thinking and post-thinking performance. When tested on the novel, withheld problem, the resulting agent successfully simulated alternative scenarios and used the resulting information to guide its behavior in the actual environment, solving the novel task in a single real-environment trial (zero-shot).
Brain-inspired learning in artificial neural networks: a review
May 18, 2023


Artificial neural networks (ANNs) have emerged as an essential tool in machine learning, achieving remarkable success across diverse domains, including image and speech generation, game playing, and robotics. However, there exist fundamental differences between ANNs' operating mechanisms and those of the biological brain, particularly concerning learning processes. This paper presents a comprehensive review of current brain-inspired learning representations in artificial neural networks. We investigate the integration of more biologically plausible mechanisms, such as synaptic plasticity, to enhance these networks' capabilities. Moreover, we delve into the potential advantages and challenges accompanying this approach. Ultimately, we pinpoint promising avenues for future research in this rapidly advancing field, which could bring us closer to understanding the essence of intelligence.
A large parametrized space of meta-reinforcement learning tasks
Feb 11, 2023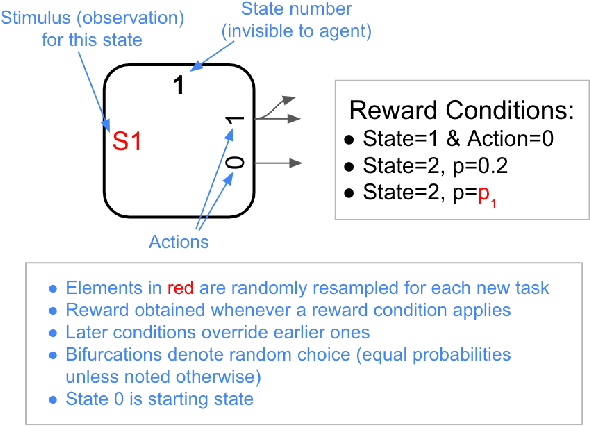
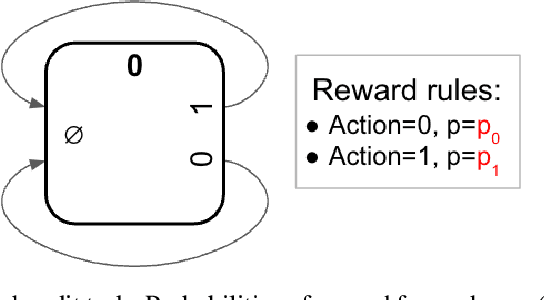
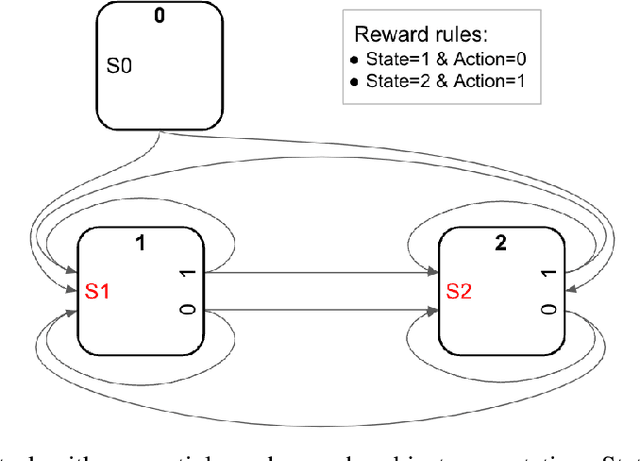
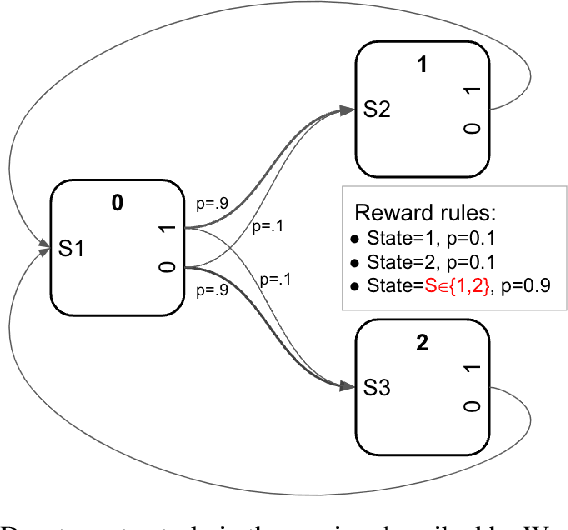
We describe a parametrized space for simple meta-reinforcement-learning (meta-RL) tasks with arbitrary stimuli. The parametrization allows us to randomly generate an arbitrary number of novel simple meta-learning tasks. The space of meta-RL tasks covered by this parametrization includes many well-known meta-RL tasks, such as bandit tasks, the Harlow task, T-mazes, the Daw two-step task and others. Simple extensions allow it to capture tasks based on two-dimensional topological spaces, such as find-the-spot or key-door tasks. We describe a number of randomly generated meta-RL tasks and discuss potential issues arising from random generation.
Learning to acquire novel cognitive tasks with evolution, plasticity and meta-meta-learning
Jan 17, 2022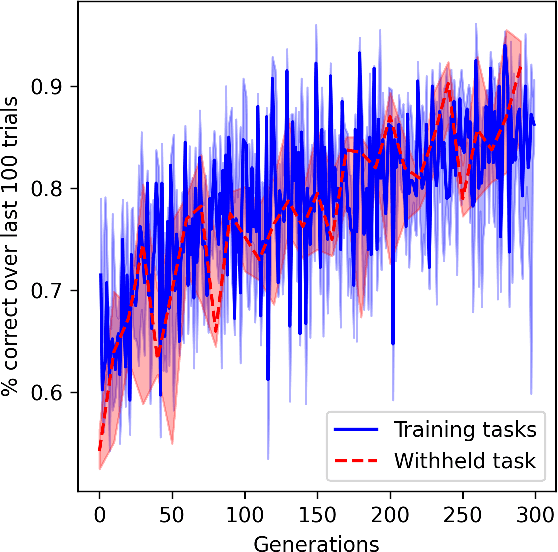
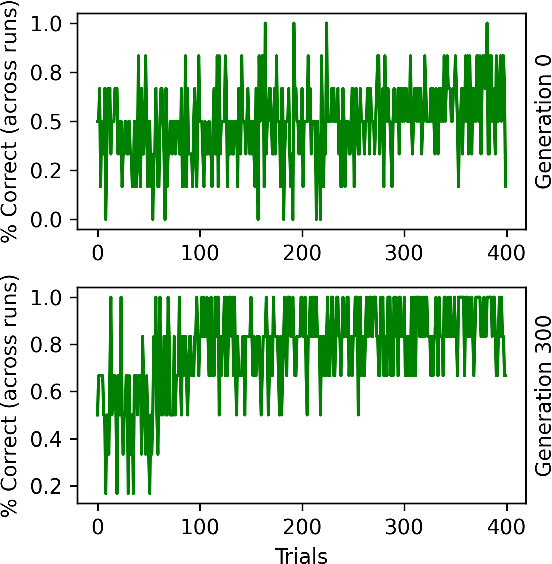
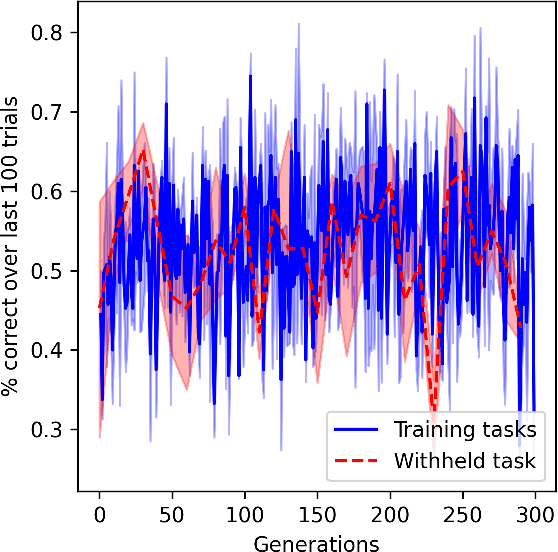
In meta-learning, networks are trained with external algorithms to learn tasks that require acquiring, storing and exploiting unpredictable information for each new instance of the task. However, animals are able to pick up such cognitive tasks automatically, as a result of their evolved neural architecture and synaptic plasticity mechanisms. Here we evolve neural networks, endowed with plastic connections, over a sizeable set of simple meta-learning tasks based on a framework from computational neuroscience. The resulting evolved network can automatically acquire a novel simple cognitive task, never seen during training, through the spontaneous operation of its evolved neural organization and plasticity structure. We suggest that attending to the multiplicity of loops involved in natural learning may provide useful insight into the emergence of intelligent behavior
Multi-layer Hebbian networks with modern deep learning frameworks
Jul 04, 2021



Deep learning networks generally use non-biological learning methods. By contrast, networks based on more biologically plausible learning, such as Hebbian learning, show comparatively poor performance and difficulties of implementation. Here we show that hierarchical, convolutional Hebbian learning can be implemented almost trivially with modern deep learning frameworks, by using specific losses whose gradients produce exactly the desired Hebbian updates. We provide expressions whose gradients exactly implement a plain Hebbian rule (dw ~= xy), Grossberg's instar rule (dw ~= y(x-w)), and Oja's rule (dw ~= y(x-yw)). As an application, we build Hebbian convolutional multi-layer networks for object recognition. We observe that higher layers of such networks tend to learn large, simple features (Gabor-like filters and blobs), explaining the previously reported decrease in decoding performance over successive layers. To combat this tendency, we introduce interventions (denser activations with sparse plasticity, pruning of connections between layers) which result in sparser learned features, massively increase performance, and allow information to increase over successive layers. We hypothesize that more advanced techniques (dynamic stimuli, trace learning, feedback connections, etc.), together with the massive computational boost offered by modern deep learning frameworks, could greatly improve the performance and biological relevance of multi-layer Hebbian networks.
Enabling Continual Learning with Differentiable Hebbian Plasticity
Jun 30, 2020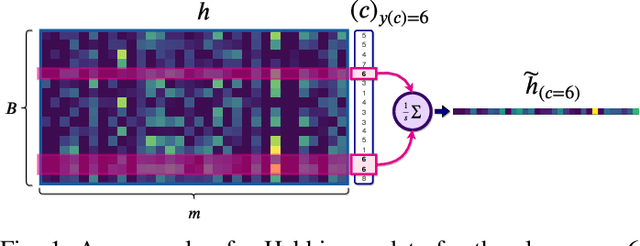
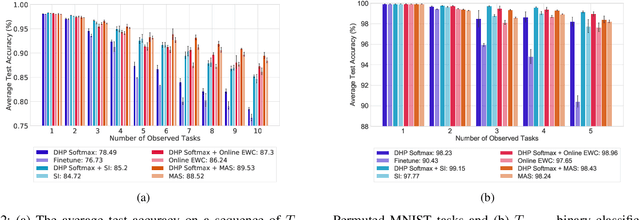
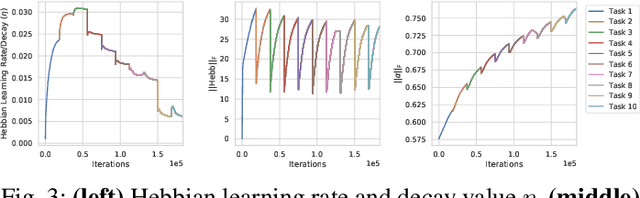
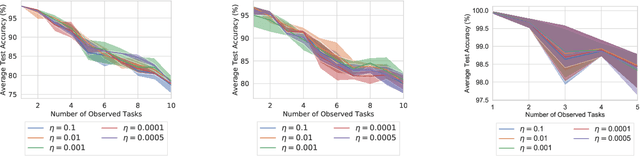
Continual learning is the problem of sequentially learning new tasks or knowledge while protecting previously acquired knowledge. However, catastrophic forgetting poses a grand challenge for neural networks performing such learning process. Thus, neural networks that are deployed in the real world often struggle in scenarios where the data distribution is non-stationary (concept drift), imbalanced, or not always fully available, i.e., rare edge cases. We propose a Differentiable Hebbian Consolidation model which is composed of a Differentiable Hebbian Plasticity (DHP) Softmax layer that adds a rapid learning plastic component (compressed episodic memory) to the fixed (slow changing) parameters of the softmax output layer; enabling learned representations to be retained for a longer timescale. We demonstrate the flexibility of our method by integrating well-known task-specific synaptic consolidation methods to penalize changes in the slow weights that are important for each target task. We evaluate our approach on the Permuted MNIST, Split MNIST and Vision Datasets Mixture benchmarks, and introduce an imbalanced variant of Permuted MNIST -- a dataset that combines the challenges of class imbalance and concept drift. Our proposed model requires no additional hyperparameters and outperforms comparable baselines by reducing forgetting.
Learning to Continually Learn
Mar 04, 2020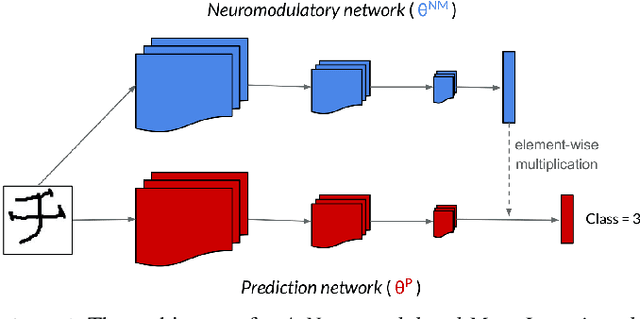
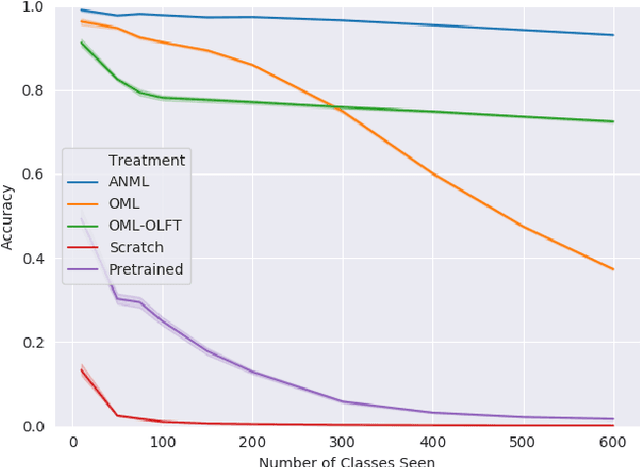
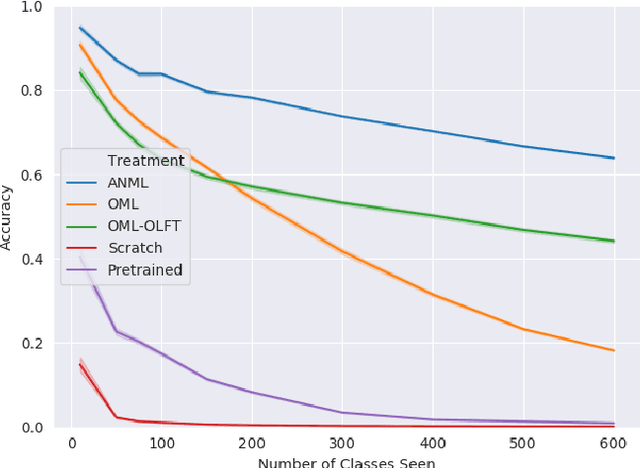
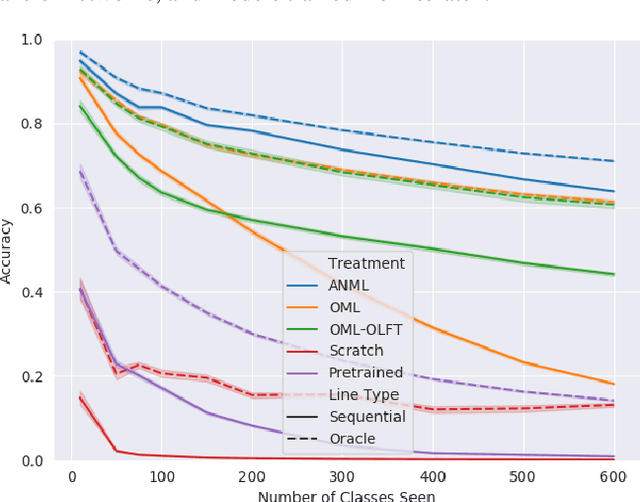
Continual lifelong learning requires an agent or model to learn many sequentially ordered tasks, building on previous knowledge without catastrophically forgetting it. Much work has gone towards preventing the default tendency of machine learning models to catastrophically forget, yet virtually all such work involves manually-designed solutions to the problem. We instead advocate meta-learning a solution to catastrophic forgetting, allowing AI to learn to continually learn. Inspired by neuromodulatory processes in the brain, we propose A Neuromodulated Meta-Learning Algorithm (ANML). It differentiates through a sequential learning process to meta-learn an activation-gating function that enables context-dependent selective activation within a deep neural network. Specifically, a neuromodulatory (NM) neural network gates the forward pass of another (otherwise normal) neural network called the prediction learning network (PLN). The NM network also thus indirectly controls selective plasticity (i.e. the backward pass of) the PLN. ANML enables continual learning without catastrophic forgetting at scale: it produces state-of-the-art continual learning performance, sequentially learning as many as 600 classes (over 9,000 SGD updates).
Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity
Feb 24, 2020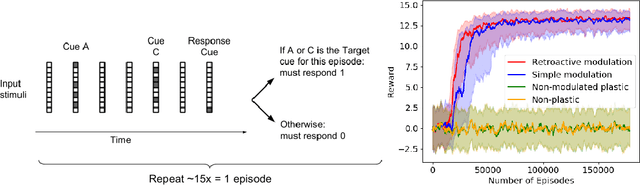

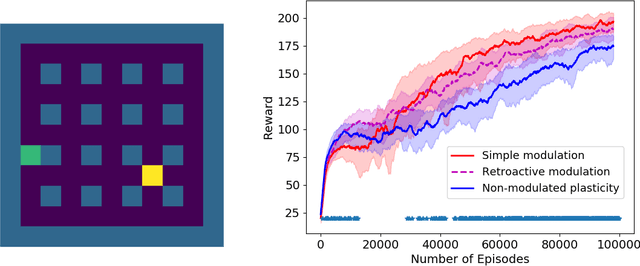
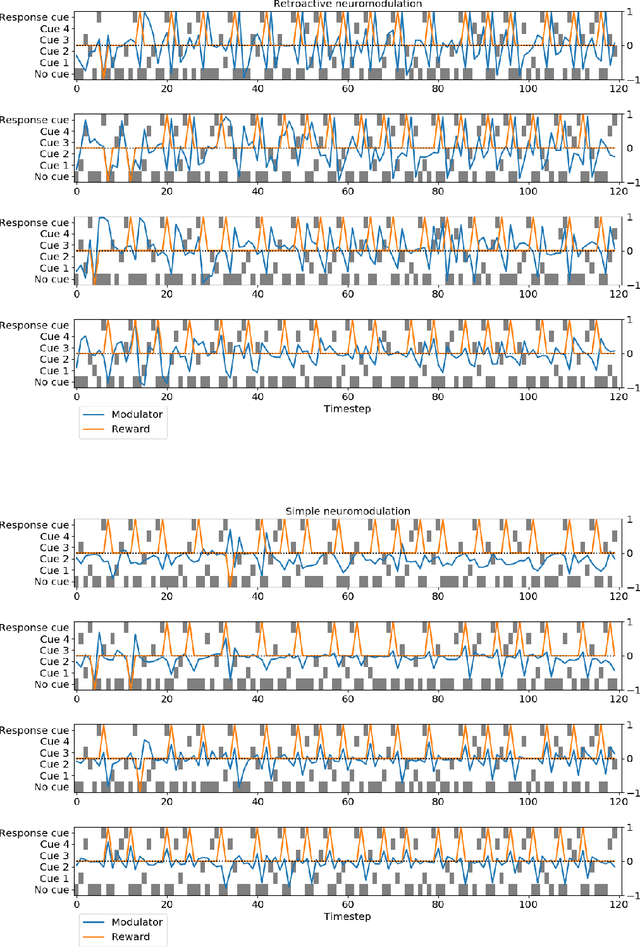
The impressive lifelong learning in animal brains is primarily enabled by plastic changes in synaptic connectivity. Importantly, these changes are not passive, but are actively controlled by neuromodulation, which is itself under the control of the brain. The resulting self-modifying abilities of the brain play an important role in learning and adaptation, and are a major basis for biological reinforcement learning. Here we show for the first time that artificial neural networks with such neuromodulated plasticity can be trained with gradient descent. Extending previous work on differentiable Hebbian plasticity, we propose a differentiable formulation for the neuromodulation of plasticity. We show that neuromodulated plasticity improves the performance of neural networks on both reinforcement learning and supervised learning tasks. In one task, neuromodulated plastic LSTMs with millions of parameters outperform standard LSTMs on a benchmark language modeling task (controlling for the number of parameters). We conclude that differentiable neuromodulation of plasticity offers a powerful new framework for training neural networks.
* Presented at the 7th International Conference on Learning Representations (ICLR 2019)
Estimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020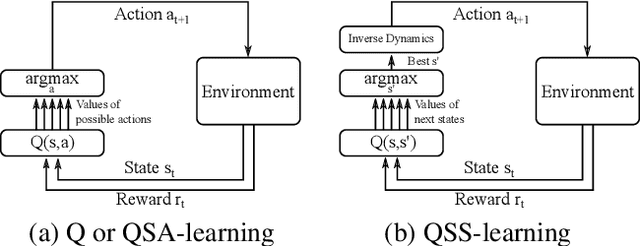
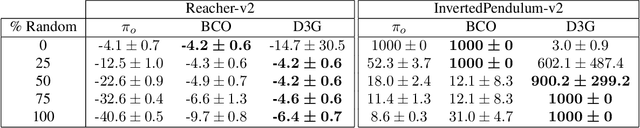
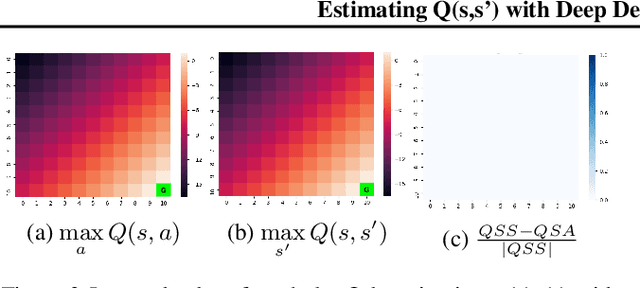
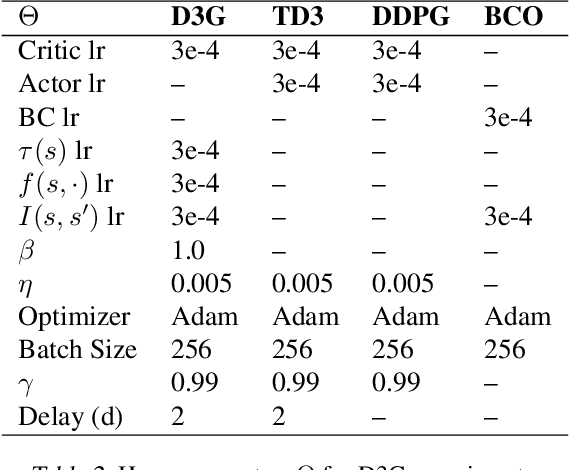
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.