Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Q(s,s') with Deep Deterministic Dynamics Gradients
Paper and Code
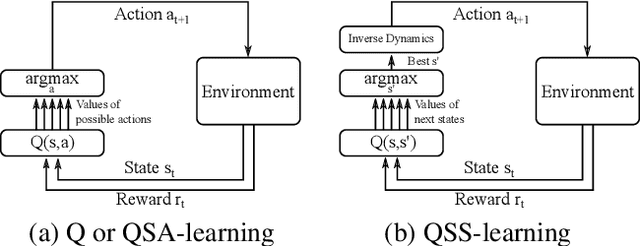
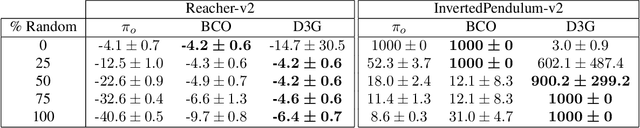
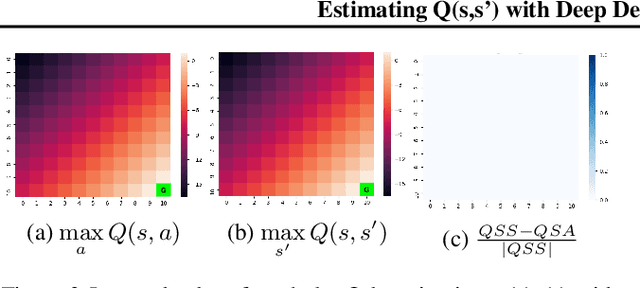
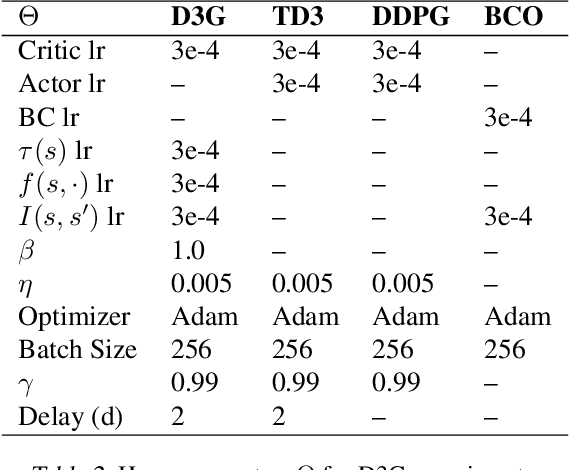
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
View paper on