 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models as a Source of Rewards
Dec 14, 2023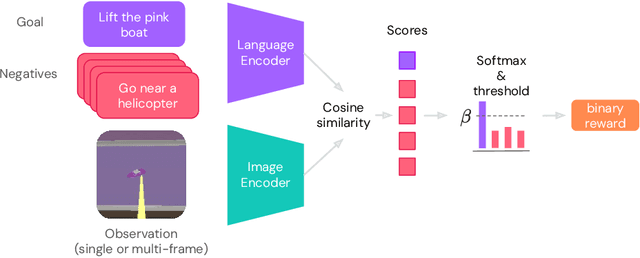
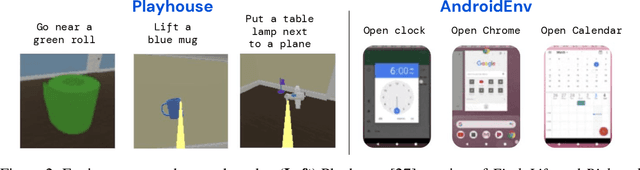
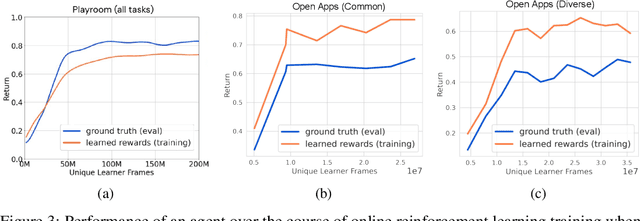
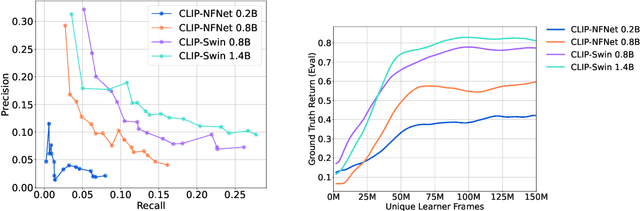
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
In-context Reinforcement Learning with Algorithm Distillation
Oct 25, 2022



We propose Algorithm Distillation (AD), a method for distilling reinforcement learning (RL) algorithms into neural networks by modeling their training histories with a causal sequence model. Algorithm Distillation treats learning to reinforcement learn as an across-episode sequential prediction problem. A dataset of learning histories is generated by a source RL algorithm, and then a causal transformer is trained by autoregressively predicting actions given their preceding learning histories as context. Unlike sequential policy prediction architectures that distill post-learning or expert sequences, AD is able to improve its policy entirely in-context without updating its network parameters. We demonstrate that AD can reinforcement learn in-context in a variety of environments with sparse rewards, combinatorial task structure, and pixel-based observations, and find that AD learns a more data-efficient RL algorithm than the one that generated the source data.
Hard Attention Control By Mutual Information Maximization
Mar 10, 2021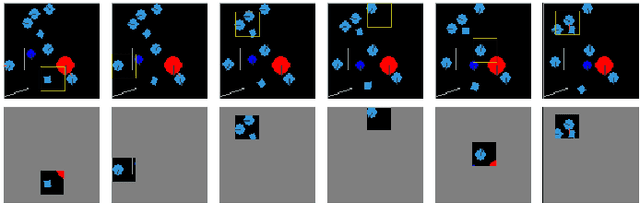

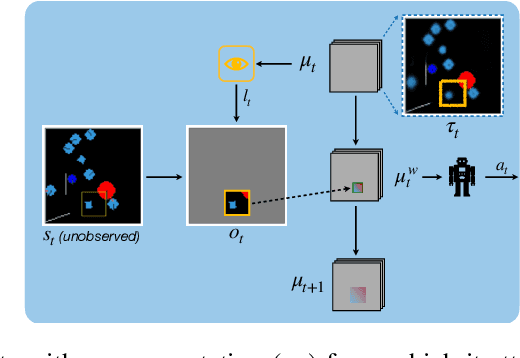
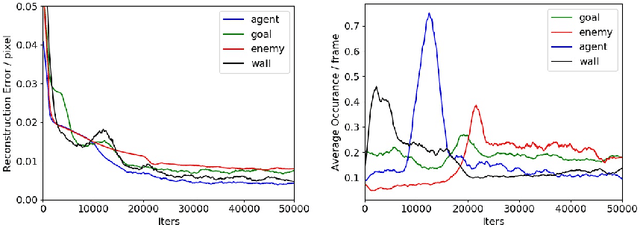
Biological agents have adopted the principle of attention to limit the rate of incoming information from the environment. One question that arises is if an artificial agent has access to only a limited view of its surroundings, how can it control its attention to effectively solve tasks? We propose an approach for learning how to control a hard attention window by maximizing the mutual information between the environment state and the attention location at each step. The agent employs an internal world model to make predictions about its state and focuses attention towards where the predictions may be wrong. Attention is trained jointly with a dynamic memory architecture that stores partial observations and keeps track of the unobserved state. We demonstrate that our approach is effective in predicting the full state from a sequence of partial observations. We also show that the agent's internal representation of the surroundings, a live mental map, can be used for control in two partially observable reinforcement learning tasks. Videos of the trained agent can be found at https://sites.google.com/view/hard-attention-control.
Estimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020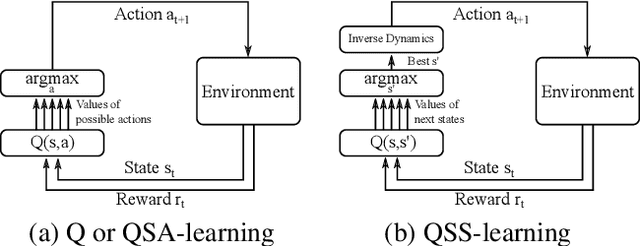
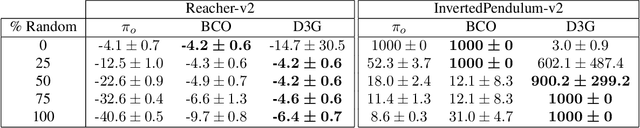
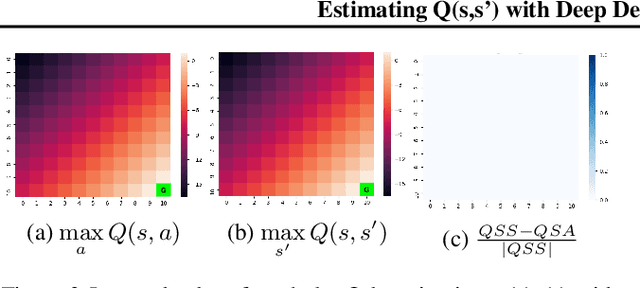
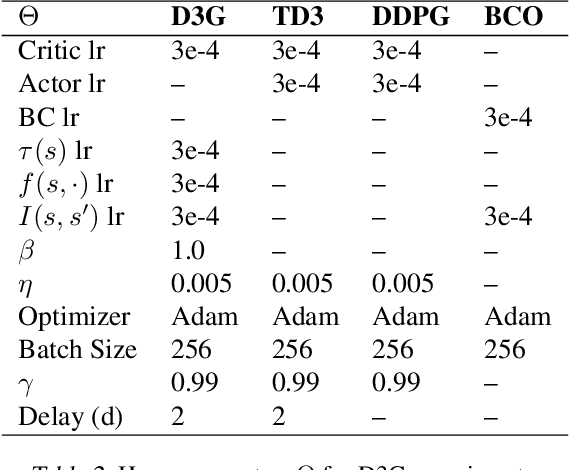
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
Visual Hindsight Experience Replay
Jan 31, 2019
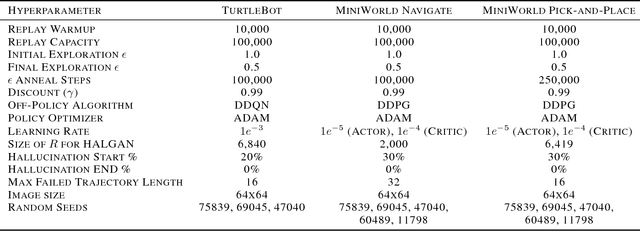
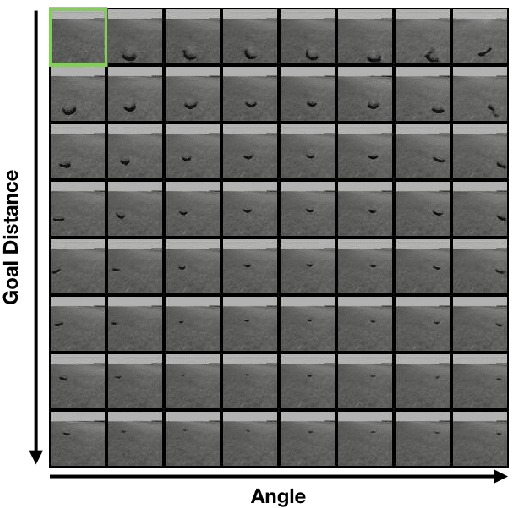

Reinforcement Learning algorithms typically require millions of environment interactions to learn successful policies in sparse reward settings. Hindsight Experience Replay (HER) was introduced as a technique to increase sample efficiency through re-imagining unsuccessful trajectories as successful ones by replacing the originally intended goals. However, this method is not applicable to visual domains where the goal configuration is unknown and must be inferred from observation. In this work, we show how unsuccessful visual trajectories can be hallucinated to be successful using a generative model trained on relatively few snapshots of the goal. As far as we are aware, this is the first work that does so with the agent policy conditioned solely on its state. We then apply this model to training reinforcement learning agents in discrete and continuous settings. We show results on a navigation and pick-and-place task in a 3D environment and on a simulated robotics application. Our method shows marked improvement over standard RL algorithms and baselines derived from prior work.
Imitating Latent Policies from Observation
May 24, 2018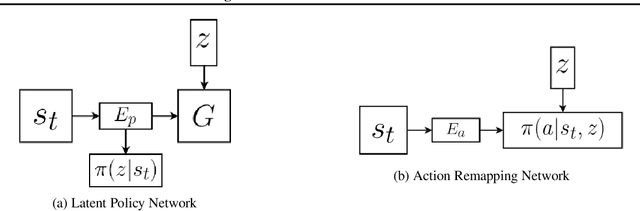
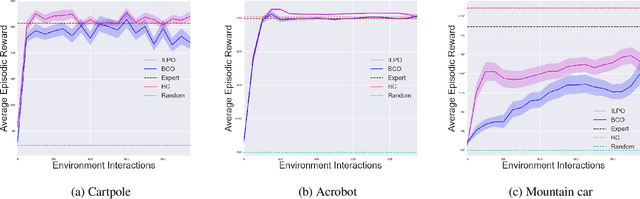
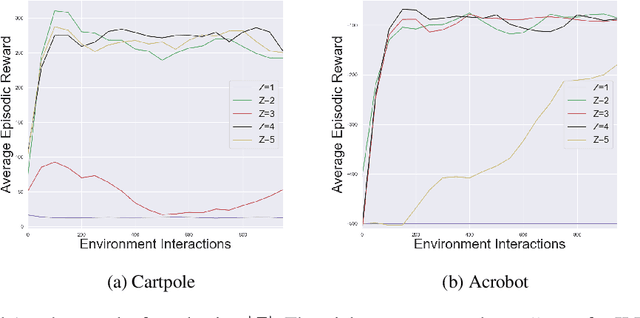
We describe a novel approach to imitation learning that infers latent policies directly from state observations. We introduce a method that characterizes the causal effects of unknown actions on observations while simultaneously predicting their likelihood. We then outline an action alignment procedure that leverages a small amount of environment interactions to determine a mapping between latent and real-world actions. We show that this corrected labeling can be used for imitating the observed behavior, even though no expert actions are given. We evaluate our approach within classic control and photo-realistic visual environments and demonstrate that it performs well when compared to standard approaches.
Learning to Compose Skills
Nov 30, 2017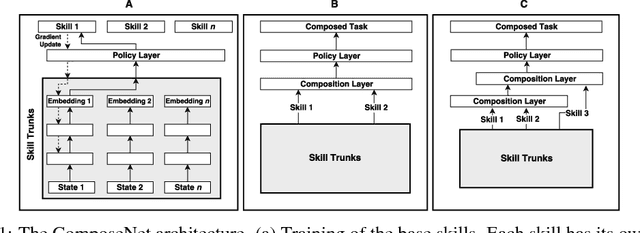
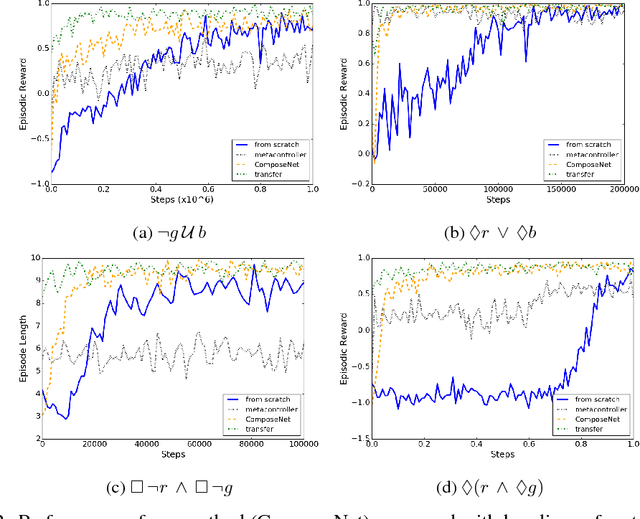
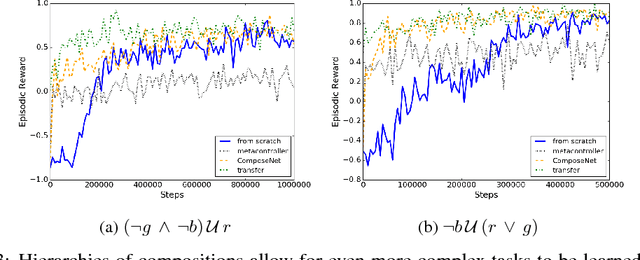
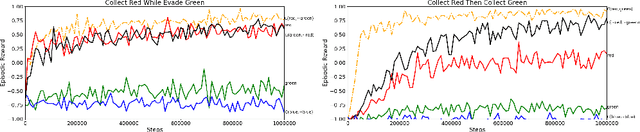
We present a differentiable framework capable of learning a wide variety of compositions of simple policies that we call skills. By recursively composing skills with themselves, we can create hierarchies that display complex behavior. Skill networks are trained to generate skill-state embeddings that are provided as inputs to a trainable composition function, which in turn outputs a policy for the overall task. Our experiments on an environment consisting of multiple collect and evade tasks show that this architecture is able to quickly build complex skills from simpler ones. Furthermore, the learned composition function displays some transfer to unseen combinations of skills, allowing for zero-shot generalizations.
State Space Decomposition and Subgoal Creation for Transfer in Deep Reinforcement Learning
May 24, 2017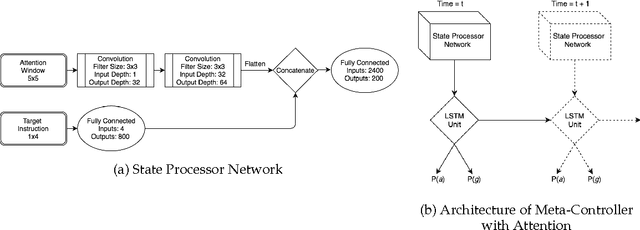
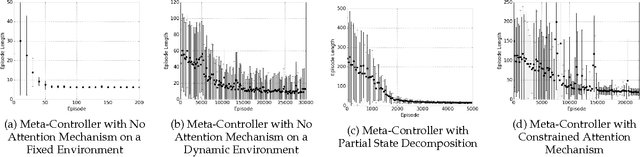
Typical reinforcement learning (RL) agents learn to complete tasks specified by reward functions tailored to their domain. As such, the policies they learn do not generalize even to similar domains. To address this issue, we develop a framework through which a deep RL agent learns to generalize policies from smaller, simpler domains to more complex ones using a recurrent attention mechanism. The task is presented to the agent as an image and an instruction specifying the goal. This meta-controller guides the agent towards its goal by designing a sequence of smaller subtasks on the part of the state space within the attention, effectively decomposing it. As a baseline, we consider a setup without attention as well. Our experiments show that the meta-controller learns to create subgoals within the attention.