 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffWorld Gym: open-access physical robotics environment for real-world reinforcement learning benchmark and research
Oct 18, 2019
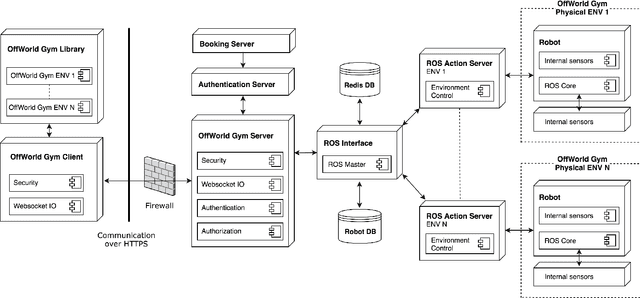
Success stories of applied machine learning can be traced back to the datasets and environments that were put forward as challenges for the community. The challenge that the community sets as a benchmark is usually the challenge that the community eventually solves. The ultimate challenge of reinforcement learning research is to train real agents to operate in the real environment, but until now there has not been a common real-world RL benchmark. In this work, we present a prototype real-world environment from OffWorld Gym -- a collection of real-world environments for reinforcement learning in robotics with free public remote access. Close integration into existing ecosystem allows the community to start using OffWorld Gym without any prior experience in robotics and takes away the burden of managing a physical robotics system, abstracting it under a familiar API. We introduce a navigation task, where a robot has to reach a visual beacon on an uneven terrain using only the camera input and provide baseline results in both the real environment and the simulated replica. To start training, visit https://gym.offworld.ai.
Visual Hindsight Experience Replay
Jan 31, 2019
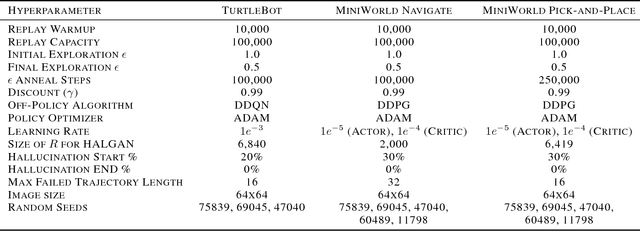
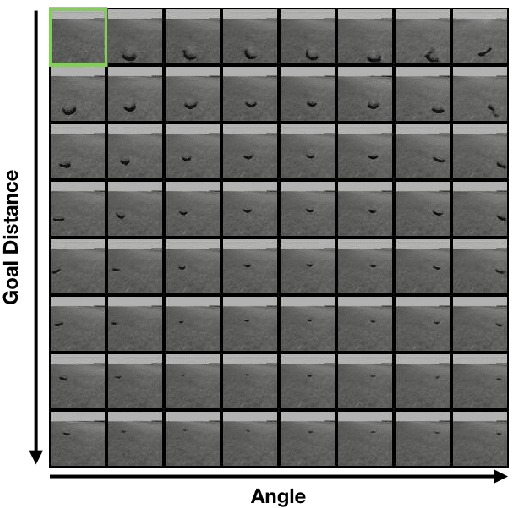

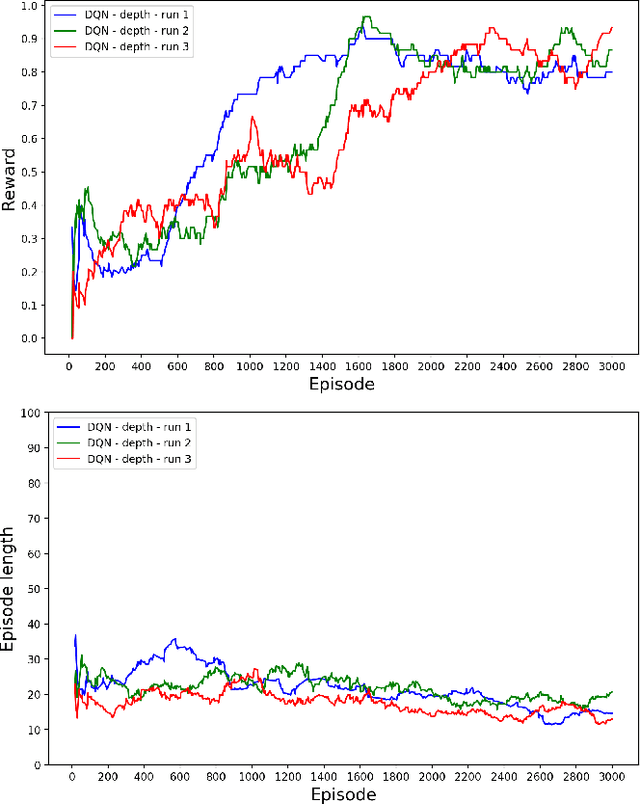
Reinforcement Learning algorithms typically require millions of environment interactions to learn successful policies in sparse reward settings. Hindsight Experience Replay (HER) was introduced as a technique to increase sample efficiency through re-imagining unsuccessful trajectories as successful ones by replacing the originally intended goals. However, this method is not applicable to visual domains where the goal configuration is unknown and must be inferred from observation. In this work, we show how unsuccessful visual trajectories can be hallucinated to be successful using a generative model trained on relatively few snapshots of the goal. As far as we are aware, this is the first work that does so with the agent policy conditioned solely on its state. We then apply this model to training reinforcement learning agents in discrete and continuous settings. We show results on a navigation and pick-and-place task in a 3D environment and on a simulated robotics application. Our method shows marked improvement over standard RL algorithms and baselines derived from prior work.