 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Discrimination Clusters: Quantifying and Explaining Systematic Fairness Violations
Dec 29, 2025Fairness in algorithmic decision-making is often framed in terms of individual fairness, which requires that similar individuals receive similar outcomes. A system violates individual fairness if there exists a pair of inputs differing only in protected attributes (such as race or gender) that lead to significantly different outcomes-for example, one favorable and the other unfavorable. While this notion highlights isolated instances of unfairness, it fails to capture broader patterns of systematic or clustered discrimination that may affect entire subgroups. We introduce and motivate the concept of discrimination clustering, a generalization of individual fairness violations. Rather than detecting single counterfactual disparities, we seek to uncover regions of the input space where small perturbations in protected features lead to k-significantly distinct clusters of outcomes. That is, for a given input, we identify a local neighborhood-differing only in protected attributes-whose members' outputs separate into many distinct clusters. These clusters reveal significant arbitrariness in treatment solely based on protected attributes that help expose patterns of algorithmic bias that elude pairwise fairness checks. We present HyFair, a hybrid technique that combines formal symbolic analysis (via SMT and MILP solvers) to certify individual fairness with randomized search to discover discriminatory clusters. This combination enables both formal guarantees-when no counterexamples exist-and the detection of severe violations that are computationally challenging for symbolic methods alone. Given a set of inputs exhibiting high k-unfairness, we introduce a novel explanation method to generate interpretable, decision-tree-style artifacts. Our experiments demonstrate that HyFair outperforms state-of-the-art fairness verification and local explanation methods.
Application of LLMs to Multi-Robot Path Planning and Task Allocation
Jul 09, 2025Efficient exploration is a well known problem in deep reinforcement learning and this problem is exacerbated in multi-agent reinforcement learning due the intrinsic complexities of such algorithms. There are several approaches to efficiently explore an environment to learn to solve tasks by multi-agent operating in that environment, of which, the idea of expert exploration is investigated in this work. More specifically, this work investigates the application of large-language models as expert planners for efficient exploration in planning based tasks for multiple agents.
Thrust Microstepping via Acceleration Feedback in Quadrotor Control for Aerial Grasping of Dynamic Payload
Oct 08, 2024



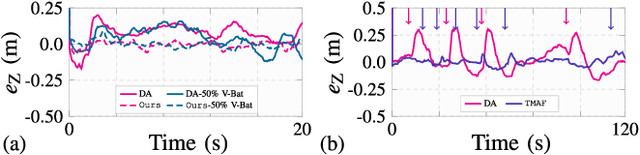
In this work, we propose an end-to-end Thrust Microstepping and Decoupled Control (TMDC) of quadrotors. TMDC focuses on precise off-centered aerial grasping of payloads dynamically, which are attached rigidly to the UAV body via a gripper contrary to the swinging payload. The dynamic payload grasping quickly changes UAV's mass, inertia etc, causing instability while performing a grasping operation in-air. We identify that to handle unknown payload grasping, the role of thrust controller is crucial. Hence, we focus on thrust control without involving system parameters such as mass etc. TMDC is based on our novel Thrust Microstepping via Acceleration Feedback (TMAF) thrust controller and Decoupled Motion Control (DMC). TMAF precisely estimates the desired thrust even at smaller loop rates while DMC decouples the horizontal and vertical motion to counteract disturbances in the case of dynamic payloads. We prove the controller's efficacy via exhaustive experiments in practically interesting and adverse real-world cases, such as fully onboard state estimation without any positioning sensor, narrow and indoor flying workspaces with intense wind turbulence, heavy payloads, non-uniform loop rates, etc. Our TMDC outperforms recent direct acceleration feedback thrust controller (DA) and geometric tracking control (GT) in flying stably for aerial grasping and achieves RMSE below 0.04m in contrast to 0.15m of DA and 0.16m of GT.
Design, Localization, Perception, and Control for GPS-Denied Autonomous Aerial Grasping and Harvesting
Oct 08, 2024
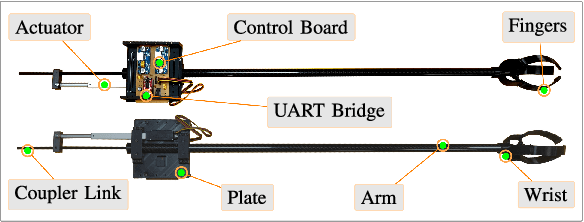
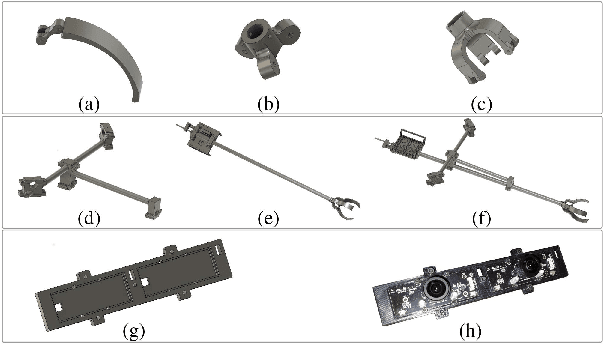
In this paper, we present a comprehensive UAV system design to perform the highly complex task of off-centered aerial grasping. This task has several interdisciplinary research challenges which need to be addressed at once. The main design challenges are GPS-denied functionality, solely onboard computing, and avoiding off-the-shelf costly positioning systems. While in terms of algorithms, visual perception, localization, control, and grasping are the leading research problems. Hence in this paper, we make interdisciplinary contributions: (i) A detailed description of the fundamental challenges in indoor aerial grasping, (ii) a novel lightweight gripper design, (iii) a complete aerial platform design and in-lab fabrication, and (iv) localization, perception, control, grasping systems, and an end-to-end flight autonomy state-machine. Finally, we demonstrate the resulting aerial grasping system Drone-Bee achieving a high grasping rate for a highly challenging agricultural task of apple-like fruit harvesting, indoors in a vertical farming setting (Fig. 1). To our knowledge, such a system has not been previously discussed in the literature, and with its capabilities, this system pushes aerial manipulation towards 4th generation.
Designing Concise ConvNets with Columnar Stages
Oct 05, 2024In the era of vision Transformers, the recent success of VanillaNet shows the huge potential of simple and concise convolutional neural networks (ConvNets). Where such models mainly focus on runtime, it is also crucial to simultaneously focus on other aspects, e.g., FLOPs, parameters, etc, to strengthen their utility further. To this end, we introduce a refreshing ConvNet macro design called Columnar Stage Network (CoSNet). CoSNet has a systematically developed simple and concise structure, smaller depth, low parameter count, low FLOPs, and attention-less operations, well suited for resource-constrained deployment. The key novelty of CoSNet is deploying parallel convolutions with fewer kernels fed by input replication, using columnar stacking of these convolutions, and minimizing the use of 1x1 convolution layers. Our comprehensive evaluations show that CoSNet rivals many renowned ConvNets and Transformer designs under resource-constrained scenarios. Code: https://github.com/ashishkumar822/CoSNet
High-Speed Stereo Visual SLAM for Low-Powered Computing Devices
Oct 05, 2024We present an accurate and GPU-accelerated Stereo Visual SLAM design called Jetson-SLAM. It exhibits frame-processing rates above 60FPS on NVIDIA's low-powered 10W Jetson-NX embedded computer and above 200FPS on desktop-grade 200W GPUs, even in stereo configuration and in the multiscale setting. Our contributions are threefold: (i) a Bounded Rectification technique to prevent tagging many non-corner points as a corner in FAST detection, improving SLAM accuracy. (ii) A novel Pyramidal Culling and Aggregation (PyCA) technique that yields robust features while suppressing redundant ones at high speeds by harnessing a GPU device. PyCA uses our new Multi-Location Per Thread culling strategy (MLPT) and Thread-Efficient Warp-Allocation (TEWA) scheme for GPU to enable Jetson-SLAM achieving high accuracy and speed on embedded devices. (iii) Jetson-SLAM library achieves resource efficiency by having a data-sharing mechanism. Our experiments on three challenging datasets: KITTI, EuRoC, and KAIST-VIO, and two highly accurate SLAM backends: Full-BA and ICE-BA show that Jetson-SLAM is the fastest available accurate and GPU-accelerated SLAM system (Fig. 1).
Cross Resolution Encoding-Decoding For Detection Transformers
Oct 05, 2024



Detection Transformers (DETR) are renowned object detection pipelines, however computationally efficient multiscale detection using DETR is still challenging. In this paper, we propose a Cross-Resolution Encoding-Decoding (CRED) mechanism that allows DETR to achieve the accuracy of high-resolution detection while having the speed of low-resolution detection. CRED is based on two modules; Cross Resolution Attention Module (CRAM) and One Step Multiscale Attention (OSMA). CRAM is designed to transfer the knowledge of low-resolution encoder output to a high-resolution feature. While OSMA is designed to fuse multiscale features in a single step and produce a feature map of a desired resolution enriched with multiscale information. When used in prominent DETR methods, CRED delivers accuracy similar to the high-resolution DETR counterpart in roughly 50% fewer FLOPs. Specifically, state-of-the-art DN-DETR, when used with CRED (calling CRED-DETR), becomes 76% faster, with ~50% reduced FLOPs than its high-resolution counterpart with 202 G FLOPs on MS-COCO benchmark. We plan to release pretrained CRED-DETRs for use by the community. Code: https://github.com/ashishkumar822/CRED-DETR
Modeling Text-Label Alignment for Hierarchical Text Classification
Sep 01, 2024Hierarchical Text Classification (HTC) aims to categorize text data based on a structured label hierarchy, resulting in predicted labels forming a sub-hierarchy tree. The semantics of the text should align with the semantics of the labels in this sub-hierarchy. With the sub-hierarchy changing for each sample, the dynamic nature of text-label alignment poses challenges for existing methods, which typically process text and labels independently. To overcome this limitation, we propose a Text-Label Alignment (TLA) loss specifically designed to model the alignment between text and labels. We obtain a set of negative labels for a given text and its positive label set. By leveraging contrastive learning, the TLA loss pulls the text closer to its positive label and pushes it away from its negative label in the embedding space. This process aligns text representations with related labels while distancing them from unrelated ones. Building upon this framework, we introduce the Hierarchical Text-Label Alignment (HTLA) model, which leverages BERT as the text encoder and GPTrans as the graph encoder and integrates text-label embeddings to generate hierarchy-aware representations. Experimental results on benchmark datasets and comparison with existing baselines demonstrate the effectiveness of HTLA for HTC.
NeuFair: Neural Network Fairness Repair with Dropout
Jul 05, 2024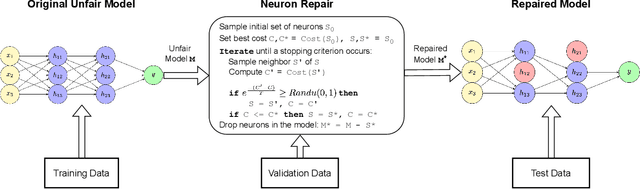
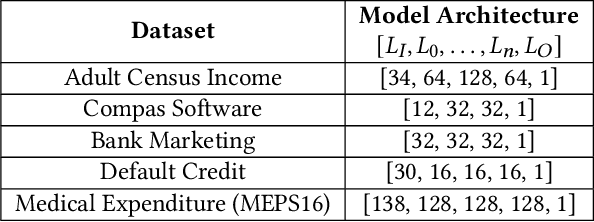
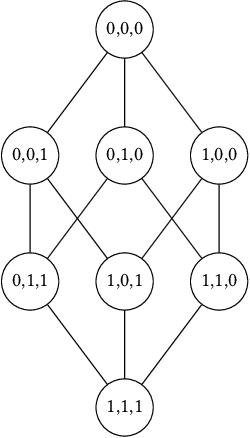

This paper investigates the neural dropout method as a post-processing bias mitigation for deep neural networks (DNNs). Neural-driven software solutions are increasingly applied in socially critical domains with significant fairness implications. While neural networks are exceptionally good at finding statistical patterns from data, they are notorious for overfitting to the training datasets that may encode and amplify existing biases from the historical data. Existing bias mitigation algorithms often require either modifying the input dataset or modifying the learning algorithms. We posit that the prevalent dropout methods that prevent over-fitting during training by randomly dropping neurons may be an effective and less intrusive approach to improve fairness of pre-trained DNNs. However, finding the ideal set of neurons to drop is a combinatorial problem. We propose NeuFair, a family of post-processing randomized algorithms that mitigate unfairness in pre-trained DNNs. Our randomized search is guided by an objective to minimize discrimination while maintaining the model utility. We show that our design of randomized algorithms provides statistical guarantees on finding optimal solutions, and we empirically evaluate the efficacy and efficiency of NeuFair in improving fairness, with minimal or no performance degradation. Our results show that NeuFair improves fairness by up to 69% and outperforms state-of-the-art post-processing bias techniques.
Pick-or-Mix: Dynamic Channel Sampling for ConvNets
Jun 16, 2024



Channel pruning approaches for convolutional neural networks (ConvNets) deactivate the channels, statically or dynamically, and require special implementation. In addition, channel squeezing in representative ConvNets is carried out via 1x1 convolutions which dominates a large portion of computations and network parameters. Given these challenges, we propose an effective multi-purpose module for dynamic channel sampling, namely Pick-or-Mix (PiX), which does not require special implementation. PiX divides a set of channels into subsets and then picks from them, where the picking decision is dynamically made per each pixel based on the input activations. We plug PiX into prominent ConvNet architectures and verify its multi-purpose utilities. After replacing 1x1 channel squeezing layers in ResNet with PiX, the network becomes 25% faster without losing accuracy. We show that PiX allows ConvNets to learn better data representation than widely adopted approaches to enhance networks' representation power (e.g., SE, CBAM, AFF, SKNet, and DWP). We also show that PiX achieves state-of-the-art performance on network downscaling and dynamic channel pruning applications.
* Published in Computer Vision and Pattern Recognition (CVPR 2024)