 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Discrimination Clusters: Quantifying and Explaining Systematic Fairness Violations
Dec 29, 2025Fairness in algorithmic decision-making is often framed in terms of individual fairness, which requires that similar individuals receive similar outcomes. A system violates individual fairness if there exists a pair of inputs differing only in protected attributes (such as race or gender) that lead to significantly different outcomes-for example, one favorable and the other unfavorable. While this notion highlights isolated instances of unfairness, it fails to capture broader patterns of systematic or clustered discrimination that may affect entire subgroups. We introduce and motivate the concept of discrimination clustering, a generalization of individual fairness violations. Rather than detecting single counterfactual disparities, we seek to uncover regions of the input space where small perturbations in protected features lead to k-significantly distinct clusters of outcomes. That is, for a given input, we identify a local neighborhood-differing only in protected attributes-whose members' outputs separate into many distinct clusters. These clusters reveal significant arbitrariness in treatment solely based on protected attributes that help expose patterns of algorithmic bias that elude pairwise fairness checks. We present HyFair, a hybrid technique that combines formal symbolic analysis (via SMT and MILP solvers) to certify individual fairness with randomized search to discover discriminatory clusters. This combination enables both formal guarantees-when no counterexamples exist-and the detection of severe violations that are computationally challenging for symbolic methods alone. Given a set of inputs exhibiting high k-unfairness, we introduce a novel explanation method to generate interpretable, decision-tree-style artifacts. Our experiments demonstrate that HyFair outperforms state-of-the-art fairness verification and local explanation methods.
Technical Challenges in Maintaining Tax Prep Software with Large Language Models
Apr 25, 2025



As the US tax law evolves to adapt to ever-changing politico-economic realities, tax preparation software plays a significant role in helping taxpayers navigate these complexities. The dynamic nature of tax regulations poses a significant challenge to accurately and timely maintaining tax software artifacts. The state-of-the-art in maintaining tax prep software is time-consuming and error-prone as it involves manual code analysis combined with an expert interpretation of tax law amendments. We posit that the rigor and formality of tax amendment language, as expressed in IRS publications, makes it amenable to automatic translation to executable specifications (code). Our research efforts focus on identifying, understanding, and tackling technical challenges in leveraging Large Language Models (LLMs), such as ChatGPT and Llama, to faithfully extract code differentials from IRS publications and automatically integrate them with the prior version of the code to automate tax prep software maintenance.
Attention Pruning: Automated Fairness Repair of Language Models via Surrogate Simulated Annealing
Mar 20, 2025This paper explores pruning attention heads as a post-processing bias mitigation method for large language models (LLMs). Modern AI systems such as LLMs are expanding into sensitive social contexts where fairness concerns become especially crucial. Since LLMs develop decision-making patterns by training on massive datasets of human-generated content, they naturally encode and perpetuate societal biases. While modifying training datasets and algorithms is expensive and requires significant resources; post-processing techniques-such as selectively deactivating neurons and attention heads in pre-trained LLMs-can provide feasible and effective approaches to improve fairness. However, identifying the optimal subset of parameters to prune presents a combinatorial challenge within LLMs' immense parameter space, requiring solutions that efficiently balance competing objectives across the frontiers of model fairness and utility. To address the computational challenges, we explore a search-based program repair approach via randomized simulated annealing. Given the prohibitive evaluation costs in billion-parameter LLMs, we develop surrogate deep neural networks that efficiently model the relationship between attention head states (active/inactive) and their corresponding fairness/utility metrics. This allows us to perform optimization over the surrogate models and efficiently identify optimal subsets of attention heads for selective pruning rather than directly searching through the LLM parameter space. This paper introduces Attention Pruning, a fairness-aware surrogate simulated annealing approach to prune attention heads in LLMs that disproportionately contribute to bias while minimally impacting overall model utility. Our experiments show that Attention Pruning achieves up to $40\%$ reduction in gender bias and outperforms the state-of-the-art bias mitigation strategies.
Fairness Testing through Extreme Value Theory
Jan 20, 2025



Data-driven software is increasingly being used as a critical component of automated decision-support systems. Since this class of software learns its logic from historical data, it can encode or amplify discriminatory practices. Previous research on algorithmic fairness has focused on improving average-case fairness. On the other hand, fairness at the extreme ends of the spectrum, which often signifies lasting and impactful shifts in societal attitudes, has received significantly less emphasis. Leveraging the statistics of extreme value theory (EVT), we propose a novel fairness criterion called extreme counterfactual discrimination (ECD). This criterion estimates the worst-case amounts of disadvantage in outcomes for individuals solely based on their memberships in a protected group. Utilizing tools from search-based software engineering and generative AI, we present a randomized algorithm that samples a statistically significant set of points from the tail of ML outcome distributions even if the input dataset lacks a sufficient number of relevant samples. We conducted several experiments on four ML models (deep neural networks, logistic regression, and random forests) over 10 socially relevant tasks from the literature on algorithmic fairness. First, we evaluate the generative AI methods and find that they generate sufficient samples to infer valid EVT distribution in 95% of cases. Remarkably, we found that the prevalent bias mitigators reduce the average-case discrimination but increase the worst-case discrimination significantly in 5% of cases. We also observed that even the tail-aware mitigation algorithm -- MiniMax-Fairness -- increased the worst-case discrimination in 30% of cases. We propose a novel ECD-based mitigator that improves fairness in the tail in 90% of cases with no degradation of the average-case discrimination.
NeuFair: Neural Network Fairness Repair with Dropout
Jul 05, 2024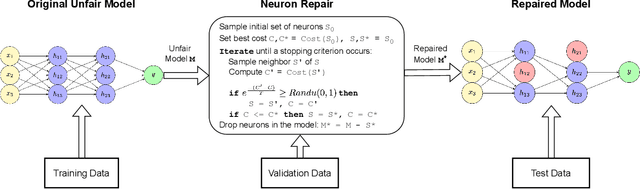
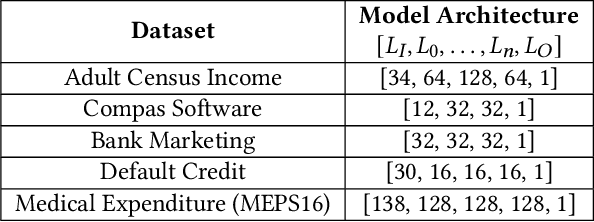

This paper investigates the neural dropout method as a post-processing bias mitigation for deep neural networks (DNNs). Neural-driven software solutions are increasingly applied in socially critical domains with significant fairness implications. While neural networks are exceptionally good at finding statistical patterns from data, they are notorious for overfitting to the training datasets that may encode and amplify existing biases from the historical data. Existing bias mitigation algorithms often require either modifying the input dataset or modifying the learning algorithms. We posit that the prevalent dropout methods that prevent over-fitting during training by randomly dropping neurons may be an effective and less intrusive approach to improve fairness of pre-trained DNNs. However, finding the ideal set of neurons to drop is a combinatorial problem. We propose NeuFair, a family of post-processing randomized algorithms that mitigate unfairness in pre-trained DNNs. Our randomized search is guided by an objective to minimize discrimination while maintaining the model utility. We show that our design of randomized algorithms provides statistical guarantees on finding optimal solutions, and we empirically evaluate the efficacy and efficiency of NeuFair in improving fairness, with minimal or no performance degradation. Our results show that NeuFair improves fairness by up to 69% and outperforms state-of-the-art post-processing bias techniques.
FairLay-ML: Intuitive Debugging of Fairness in Data-Driven Social-Critical Software
Jul 01, 2024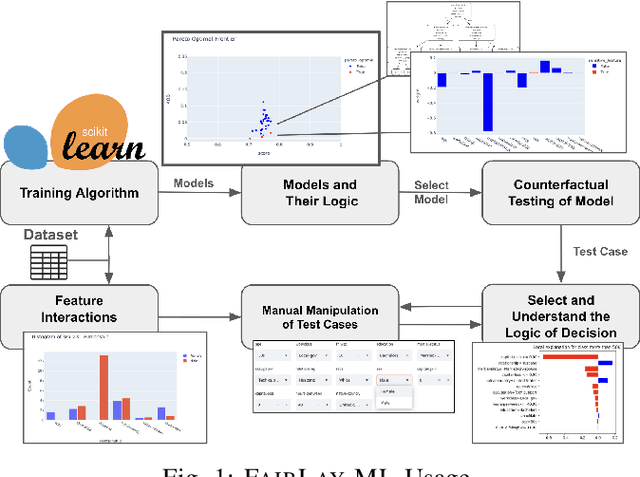
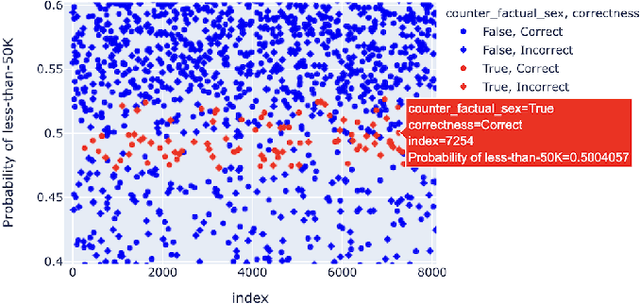
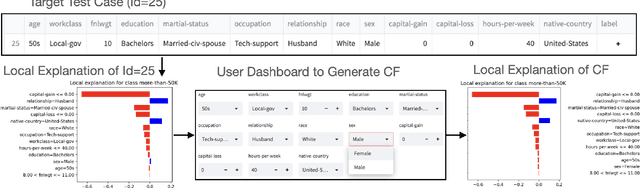
Data-driven software solutions have significantly been used in critical domains with significant socio-economic, legal, and ethical implications. The rapid adoptions of data-driven solutions, however, pose major threats to the trustworthiness of automated decision-support software. A diminished understanding of the solution by the developer and historical/current biases in the data sets are primary challenges. To aid data-driven software developers and end-users, we present \toolname, a debugging tool to test and explain the fairness implications of data-driven solutions. \toolname visualizes the logic of datasets, trained models, and decisions for a given data point. In addition, it trains various models with varying fairness-accuracy trade-offs. Crucially, \toolname incorporates counterfactual fairness testing that finds bugs beyond the development datasets. We conducted two studies through \toolname that allowed us to measure false positives/negatives in prevalent counterfactual testing and understand the human perception of counterfactual test cases in a class survey. \toolname and its benchmarks are publicly available at~\url{https://github.com/Pennswood/FairLay-ML}. The live version of the tool is available at~\url{https://fairlayml-v2.streamlit.app/}. We provide a video demo of the tool at https://youtu.be/wNI9UWkywVU?t=127
Predicting Fairness of ML Software Configuration
Apr 29, 2024



This paper investigates the relationships between hyperparameters of machine learning and fairness. Data-driven solutions are increasingly used in critical socio-technical applications where ensuring fairness is important. Rather than explicitly encoding decision logic via control and data structures, the ML developers provide input data, perform some pre-processing, choose ML algorithms, and tune hyperparameters (HPs) to infer a program that encodes the decision logic. Prior works report that the selection of HPs can significantly influence fairness. However, tuning HPs to find an ideal trade-off between accuracy, precision, and fairness has remained an expensive and tedious task. Can we predict fairness of HP configuration for a given dataset? Are the predictions robust to distribution shifts? We focus on group fairness notions and investigate the HP space of 5 training algorithms. We first find that tree regressors and XGBoots significantly outperformed deep neural networks and support vector machines in accurately predicting the fairness of HPs. When predicting the fairness of ML hyperparameters under temporal distribution shift, the tree regressors outperforms the other algorithms with reasonable accuracy. However, the precision depends on the ML training algorithm, dataset, and protected attributes. For example, the tree regressor model was robust for training data shift from 2014 to 2018 on logistic regression and discriminant analysis HPs with sex as the protected attribute; but not for race and other training algorithms. Our method provides a sound framework to efficiently perform fine-tuning of ML training algorithms and understand the relationships between HPs and fairness.
Worst-Case Convergence Time of ML Algorithms via Extreme Value Theory
Apr 10, 2024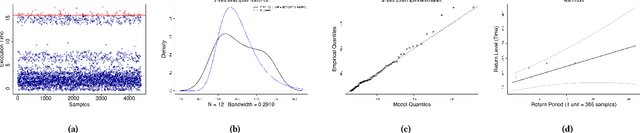



This paper leverages the statistics of extreme values to predict the worst-case convergence times of machine learning algorithms. Timing is a critical non-functional property of ML systems, and providing the worst-case converge times is essential to guarantee the availability of ML and its services. However, timing properties such as worst-case convergence times (WCCT) are difficult to verify since (1) they are not encoded in the syntax or semantics of underlying programming languages of AI, (2) their evaluations depend on both algorithmic implementations and underlying systems, and (3) their measurements involve uncertainty and noise. Therefore, prevalent formal methods and statistical models fail to provide rich information on the amounts and likelihood of WCCT. Our key observation is that the timing information we seek represents the extreme tail of execution times. Therefore, extreme value theory (EVT), a statistical discipline that focuses on understanding and predicting the distribution of extreme values in the tail of outcomes, provides an ideal framework to model and analyze WCCT in the training and inference phases of ML paradigm. Building upon the mathematical tools from EVT, we propose a practical framework to predict the worst-case timing properties of ML. Over a set of linear ML training algorithms, we show that EVT achieves a better accuracy for predicting WCCTs than relevant statistical methods such as the Bayesian factor. On the set of larger machine learning training algorithms and deep neural network inference, we show the feasibility and usefulness of EVT models to accurately predict WCCTs, their expected return periods, and their likelihood.
On the Potential and Limitations of Few-Shot In-Context Learning to Generate Metamorphic Specifications for Tax Preparation Software
Nov 20, 2023
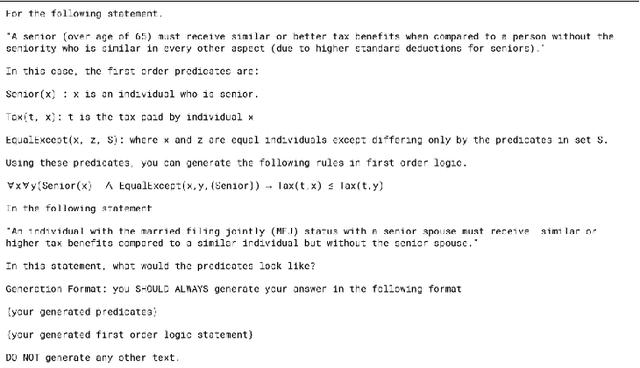


Due to the ever-increasing complexity of income tax laws in the United States, the number of US taxpayers filing their taxes using tax preparation software (henceforth, tax software) continues to increase. According to the U.S. Internal Revenue Service (IRS), in FY22, nearly 50% of taxpayers filed their individual income taxes using tax software. Given the legal consequences of incorrectly filing taxes for the taxpayer, ensuring the correctness of tax software is of paramount importance. Metamorphic testing has emerged as a leading solution to test and debug legal-critical tax software due to the absence of correctness requirements and trustworthy datasets. The key idea behind metamorphic testing is to express the properties of a system in terms of the relationship between one input and its slightly metamorphosed twinned input. Extracting metamorphic properties from IRS tax publications is a tedious and time-consuming process. As a response, this paper formulates the task of generating metamorphic specifications as a translation task between properties extracted from tax documents - expressed in natural language - to a contrastive first-order logic form. We perform a systematic analysis on the potential and limitations of in-context learning with Large Language Models(LLMs) for this task, and outline a research agenda towards automating the generation of metamorphic specifications for tax preparation software.
FairLay-ML: Intuitive Remedies for Unfairness in Data-Driven Social-Critical Algorithms
Jul 11, 2023



This thesis explores open-sourced machine learning (ML) model explanation tools to understand whether these tools can allow a layman to visualize, understand, and suggest intuitive remedies to unfairness in ML-based decision-support systems. Machine learning models trained on datasets biased against minority groups are increasingly used to guide life-altering social decisions, prompting the urgent need to study their logic for unfairness. Due to this problem's impact on vast populations of the general public, it is critical for the layperson -- not just subject matter experts in social justice or machine learning experts -- to understand the nature of unfairness within these algorithms and the potential trade-offs. Existing research on fairness in machine learning focuses mostly on the mathematical definitions and tools to understand and remedy unfair models, with some directly citing user-interactive tools as necessary for future work. This thesis presents FairLay-ML, a proof-of-concept GUI integrating some of the most promising tools to provide intuitive explanations for unfair logic in ML models by integrating existing research tools (e.g. Local Interpretable Model-Agnostic Explanations) with existing ML-focused GUI (e.g. Python Streamlit). We test FairLay-ML using models of various accuracy and fairness generated by an unfairness detector tool, Parfait-ML, and validate our results using Themis. Our study finds that the technology stack used for FairLay-ML makes it easy to install and provides real-time black-box explanations of pre-trained models to users. Furthermore, the explanations provided translate to actionable remedies.