 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLay-ML: Intuitive Debugging of Fairness in Data-Driven Social-Critical Software
Jul 01, 2024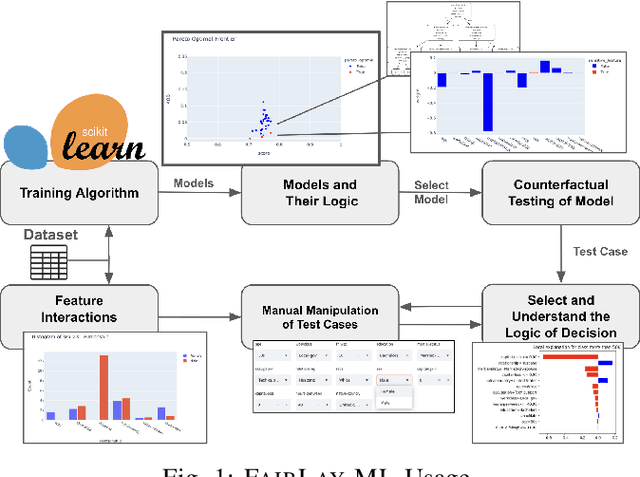
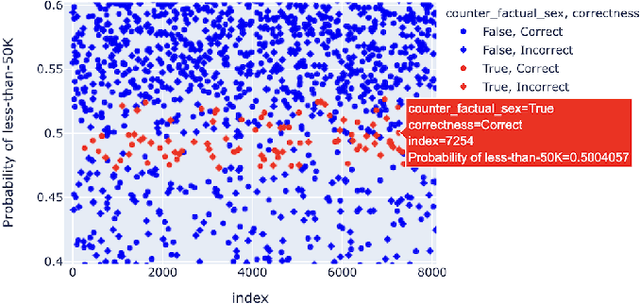
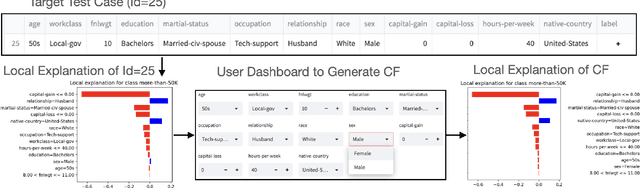
Data-driven software solutions have significantly been used in critical domains with significant socio-economic, legal, and ethical implications. The rapid adoptions of data-driven solutions, however, pose major threats to the trustworthiness of automated decision-support software. A diminished understanding of the solution by the developer and historical/current biases in the data sets are primary challenges. To aid data-driven software developers and end-users, we present \toolname, a debugging tool to test and explain the fairness implications of data-driven solutions. \toolname visualizes the logic of datasets, trained models, and decisions for a given data point. In addition, it trains various models with varying fairness-accuracy trade-offs. Crucially, \toolname incorporates counterfactual fairness testing that finds bugs beyond the development datasets. We conducted two studies through \toolname that allowed us to measure false positives/negatives in prevalent counterfactual testing and understand the human perception of counterfactual test cases in a class survey. \toolname and its benchmarks are publicly available at~\url{https://github.com/Pennswood/FairLay-ML}. The live version of the tool is available at~\url{https://fairlayml-v2.streamlit.app/}. We provide a video demo of the tool at https://youtu.be/wNI9UWkywVU?t=127
FairLay-ML: Intuitive Remedies for Unfairness in Data-Driven Social-Critical Algorithms
Jul 11, 2023



This thesis explores open-sourced machine learning (ML) model explanation tools to understand whether these tools can allow a layman to visualize, understand, and suggest intuitive remedies to unfairness in ML-based decision-support systems. Machine learning models trained on datasets biased against minority groups are increasingly used to guide life-altering social decisions, prompting the urgent need to study their logic for unfairness. Due to this problem's impact on vast populations of the general public, it is critical for the layperson -- not just subject matter experts in social justice or machine learning experts -- to understand the nature of unfairness within these algorithms and the potential trade-offs. Existing research on fairness in machine learning focuses mostly on the mathematical definitions and tools to understand and remedy unfair models, with some directly citing user-interactive tools as necessary for future work. This thesis presents FairLay-ML, a proof-of-concept GUI integrating some of the most promising tools to provide intuitive explanations for unfair logic in ML models by integrating existing research tools (e.g. Local Interpretable Model-Agnostic Explanations) with existing ML-focused GUI (e.g. Python Streamlit). We test FairLay-ML using models of various accuracy and fairness generated by an unfairness detector tool, Parfait-ML, and validate our results using Themis. Our study finds that the technology stack used for FairLay-ML makes it easy to install and provides real-time black-box explanations of pre-trained models to users. Furthermore, the explanations provided translate to actionable remedies.