 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR: Traffic Light Detection using Fourier Domain Adaptation in Hostile WeatheR
Nov 12, 2024

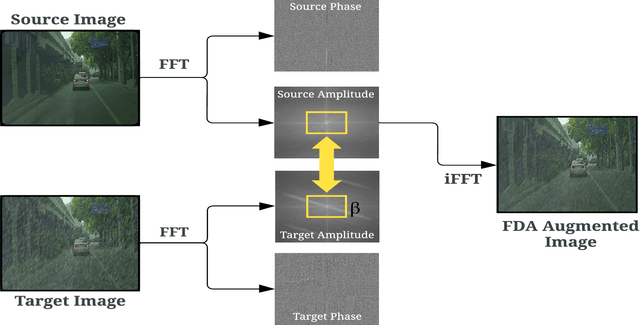

The scarcity of comprehensive datasets in the traffic light detection and recognition domain and the poor performance of state-of-the-art models under hostile weather conditions present significant challenges. To address these issues, this paper proposes a novel approach by merging two widely used datasets, LISA and S2TLD. The merged dataset is further processed to tackle class imbalance, a common problem in this domain. This merged dataset becomes our source domain. Synthetic rain and fog are added to the dataset to create our target domain. We employ Fourier Domain Adaptation (FDA) to create a final dataset with a minimized domain gap between the two datasets, helping the model trained on this final dataset adapt to rainy and foggy weather conditions. Additionally, we explore Semi-Supervised Learning (SSL) techniques to leverage the available data more effectively. Experimental results demonstrate that models trained on FDA-augmented images outperform those trained without FDA across confidence-dependent and independent metrics, like mAP50, mAP50-95, Precision, and Recall. The best-performing model, YOLOv8, achieved a Precision increase of 5.1860%, Recall increase of 14.8009%, mAP50 increase of 9.5074%, and mAP50-95 increase of 19.5035%. On average, percentage increases of 7.6892% in Precision, 19.9069% in Recall, 15.8506% in mAP50, and 23.8099% in mAP50-95 were observed across all models, highlighting the effectiveness of FDA in mitigating the impact of adverse weather conditions on model performance. These improvements pave the way for real-world applications where reliable performance in challenging environmental conditions is critical.
Improving Multi-Domain Task-Oriented Dialogue System with Offline Reinforcement Learning
Nov 08, 2024Task-oriented dialogue (TOD) system is designed to accomplish user-defined tasks through dialogues. The TOD system has progressed towards end-to-end modeling by leveraging pre-trained large language models. Fine-tuning the pre-trained language models using only supervised learning leads to the exposure bias and token loss problem and it deviates the models from completing the user's task. To address these issues, we propose a TOD system that leverages a unified pre-trained language model, GPT2, as a base model. It is optimized using supervised learning and reinforcement learning (RL). The issues in the TOD system are mitigated using a non-differentiable reward function. The reward is calculated using the weighted sum of the success rate and BLEU evaluation metrics. The success rate and BLEU metrics in reward calculation guide the language model for user task completion while ensuring a coherent and fluent response. Our model is acquired by fine-tuning a pre-trained model on the dialogue-session level which comprises user utterance, belief state, system act, and system response. Experimental results on MultiWOZ2.1 demonstrate that our model increases the inform rate by 1.60% and the success rate by 3.17% compared to the baseline.
Modeling Text-Label Alignment for Hierarchical Text Classification
Sep 01, 2024Hierarchical Text Classification (HTC) aims to categorize text data based on a structured label hierarchy, resulting in predicted labels forming a sub-hierarchy tree. The semantics of the text should align with the semantics of the labels in this sub-hierarchy. With the sub-hierarchy changing for each sample, the dynamic nature of text-label alignment poses challenges for existing methods, which typically process text and labels independently. To overcome this limitation, we propose a Text-Label Alignment (TLA) loss specifically designed to model the alignment between text and labels. We obtain a set of negative labels for a given text and its positive label set. By leveraging contrastive learning, the TLA loss pulls the text closer to its positive label and pushes it away from its negative label in the embedding space. This process aligns text representations with related labels while distancing them from unrelated ones. Building upon this framework, we introduce the Hierarchical Text-Label Alignment (HTLA) model, which leverages BERT as the text encoder and GPTrans as the graph encoder and integrates text-label embeddings to generate hierarchy-aware representations. Experimental results on benchmark datasets and comparison with existing baselines demonstrate the effectiveness of HTLA for HTC.
Snowy Scenes,Clear Detections: A Robust Model for Traffic Light Detection in Adverse Weather Conditions
Jun 19, 2024



With the rise of autonomous vehicles and advanced driver-assistance systems (ADAS), ensuring reliable object detection in all weather conditions is crucial for safety and efficiency. Adverse weather like snow, rain, and fog presents major challenges for current detection systems, often resulting in failures and potential safety risks. This paper introduces a novel framework and pipeline designed to improve object detection under such conditions, focusing on traffic signal detection where traditional methods often fail due to domain shifts caused by adverse weather. We provide a comprehensive analysis of the limitations of existing techniques. Our proposed pipeline significantly enhances detection accuracy in snow, rain, and fog. Results show a 40.8% improvement in average IoU and F1 scores compared to naive fine-tuning and a 22.4% performance increase in domain shift scenarios, such as training on artificial snow and testing on rain images.
Crowdsensing-based Road Damage Detection Challenge (CRDDC-2022)
Nov 21, 2022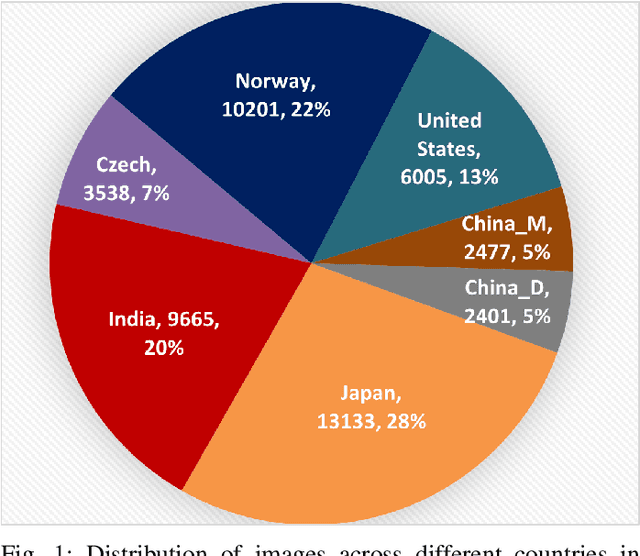



This paper summarizes the Crowdsensing-based Road Damage Detection Challenge (CRDDC), a Big Data Cup organized as a part of the IEEE International Conference on Big Data'2022. The Big Data Cup challenges involve a released dataset and a well-defined problem with clear evaluation metrics. The challenges run on a data competition platform that maintains a real-time online evaluation system for the participants. In the presented case, the data constitute 47,420 road images collected from India, Japan, the Czech Republic, Norway, the United States, and China to propose methods for automatically detecting road damages in these countries. More than 60 teams from 19 countries registered for this competition. The submitted solutions were evaluated using five leaderboards based on performance for unseen test images from the aforementioned six countries. This paper encapsulates the top 11 solutions proposed by these teams. The best-performing model utilizes ensemble learning based on YOLO and Faster-RCNN series models to yield an F1 score of 76% for test data combined from all 6 countries. The paper concludes with a comparison of current and past challenges and provides direction for the future.
RDD2022: A multi-national image dataset for automatic Road Damage Detection
Sep 18, 2022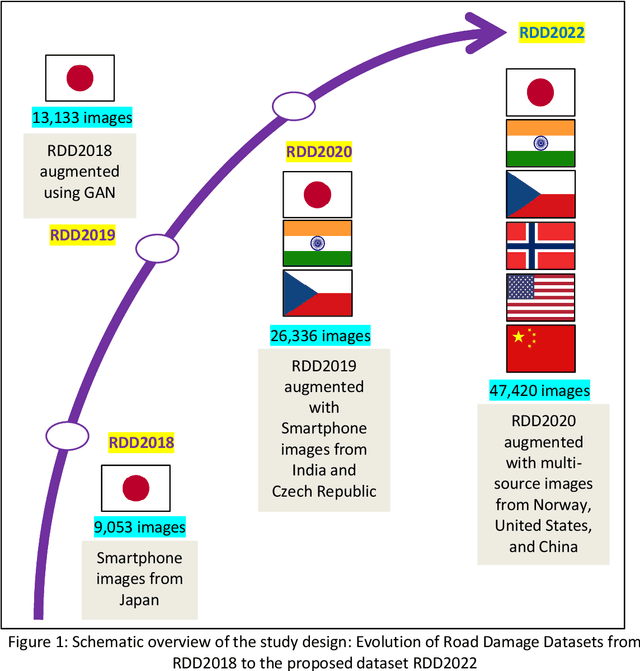
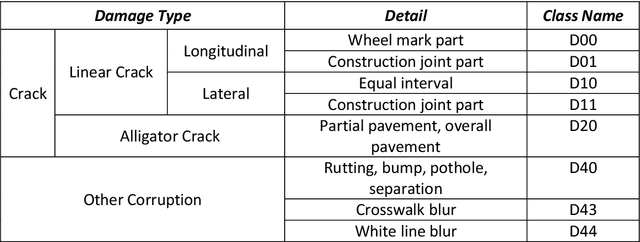
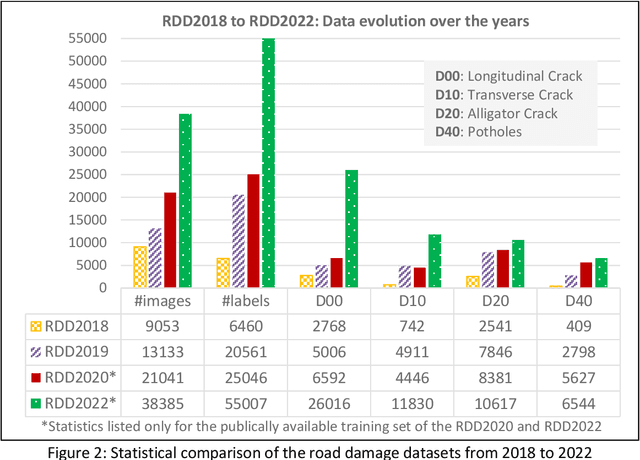

The data article describes the Road Damage Dataset, RDD2022, which comprises 47,420 road images from six countries, Japan, India, the Czech Republic, Norway, the United States, and China. The images have been annotated with more than 55,000 instances of road damage. Four types of road damage, namely longitudinal cracks, transverse cracks, alligator cracks, and potholes, are captured in the dataset. The annotated dataset is envisioned for developing deep learning-based methods to detect and classify road damage automatically. The dataset has been released as a part of the Crowd sensing-based Road Damage Detection Challenge (CRDDC2022). The challenge CRDDC2022 invites researchers from across the globe to propose solutions for automatic road damage detection in multiple countries. The municipalities and road agencies may utilize the RDD2022 dataset, and the models trained using RDD2022 for low-cost automatic monitoring of road conditions. Further, computer vision and machine learning researchers may use the dataset to benchmark the performance of different algorithms for other image-based applications of the same type (classification, object detection, etc.).
Global Road Damage Detection: State-of-the-art Solutions
Nov 17, 2020

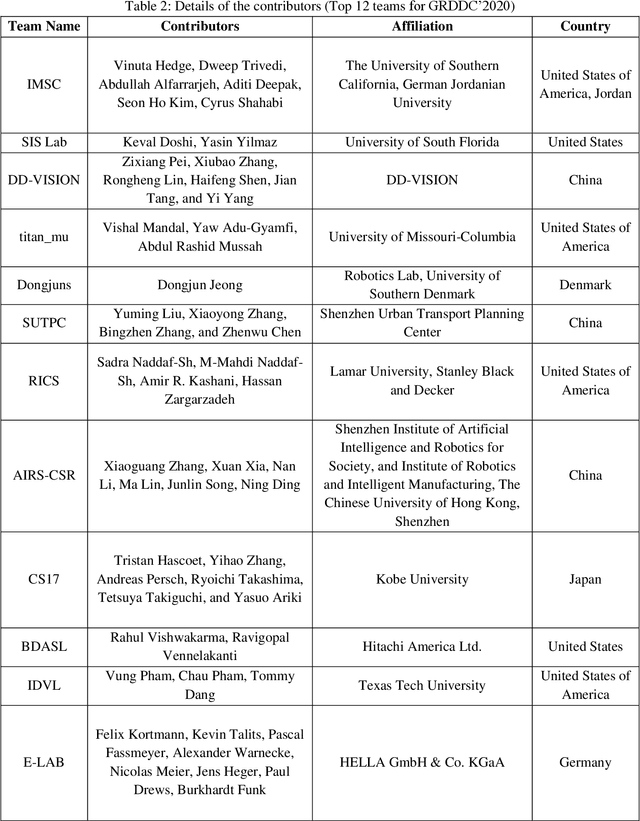

This paper summarizes the Global Road Damage Detection Challenge (GRDDC), a Big Data Cup organized as a part of the IEEE International Conference on Big Data'2020. The Big Data Cup challenges involve a released dataset and a well-defined problem with clear evaluation metrics. The challenges run on a data competition platform that maintains a leaderboard for the participants. In the presented case, the data constitute 26336 road images collected from India, Japan, and the Czech Republic to propose methods for automatically detecting road damages in these countries. In total, 121 teams from several countries registered for this competition. The submitted solutions were evaluated using two datasets test1 and test2, comprising 2,631 and 2,664 images. This paper encapsulates the top 12 solutions proposed by these teams. The best performing model utilizes YOLO-based ensemble learning to yield an F1 score of 0.67 on test1 and 0.66 on test2. The paper concludes with a review of the facets that worked well for the presented challenge and those that could be improved in future challenges.
Transfer Learning-based Road Damage Detection for Multiple Countries
Aug 30, 2020
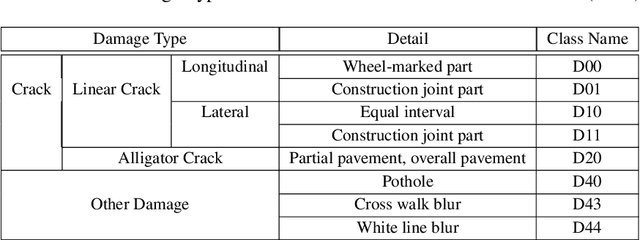
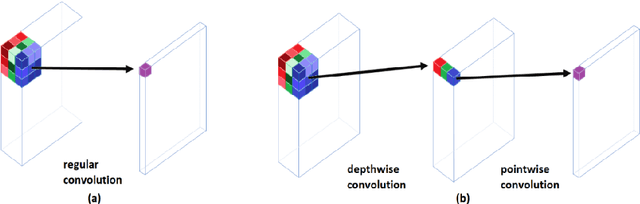
Many municipalities and road authorities seek to implement automated evaluation of road damage. However, they often lack technology, know-how, and funds to afford state-of-the-art equipment for data collection and analysis of road damages. Although some countries, like Japan, have developed less expensive and readily available Smartphone-based methods for automatic road condition monitoring, other countries still struggle to find efficient solutions. This work makes the following contributions in this context. Firstly, it assesses the usability of the Japanese model for other countries. Secondly, it proposes a large-scale heterogeneous road damage dataset comprising 26620 images collected from multiple countries using smartphones. Thirdly, we propose generalized models capable of detecting and classifying road damages in more than one country. Lastly, we provide recommendations for readers, local agencies, and municipalities of other countries when one other country publishes its data and model for automatic road damage detection and classification. Our dataset is available at (https://github.com/sekilab/RoadDamageDetector/).
An Enhanced Text Classification to Explore Health based Indian Government Policy Tweets
Aug 18, 2020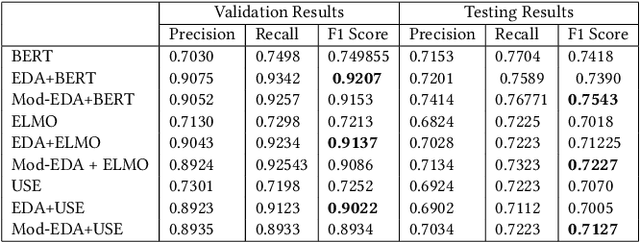
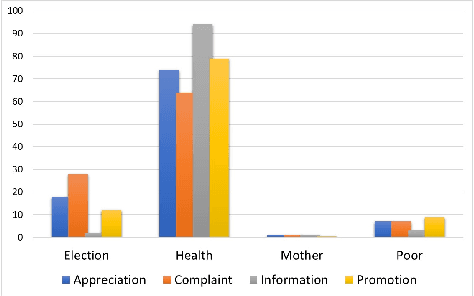
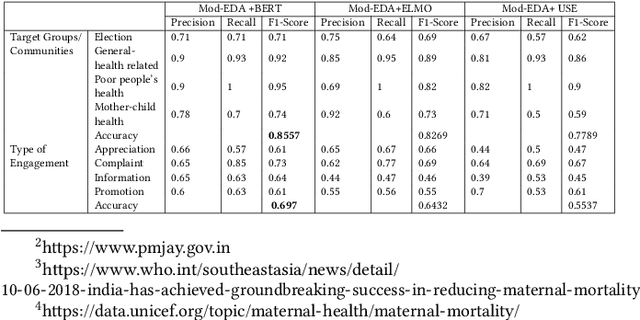
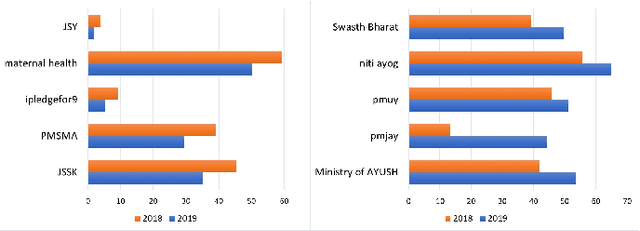
Government-sponsored policy-making and scheme generations is one of the means of protecting and promoting the social, economic, and personal development of the citizens. The evaluation of effectiveness of these schemes done by government only provide the statistical information in terms of facts and figures which do not include the in-depth knowledge of public perceptions, experiences and views on the topic. In this research work, we propose an improved text classification framework that classifies the Twitter data of different health-based government schemes. The proposed framework leverages the language representation models (LR models) BERT, ELMO, and USE. However, these LR models have less real-time applicability due to the scarcity of the ample annotated data. To handle this, we propose a novel GloVe word embeddings and class-specific sentiments based text augmentation approach (named Mod-EDA) which boosts the performance of text classification task by increasing the size of labeled data. Furthermore, the trained model is leveraged to identify the level of engagement of citizens towards these policies in different communities such as middle-income and low-income groups.
Online Anomaly Detection via Class-Imbalance Learning
Aug 27, 2015
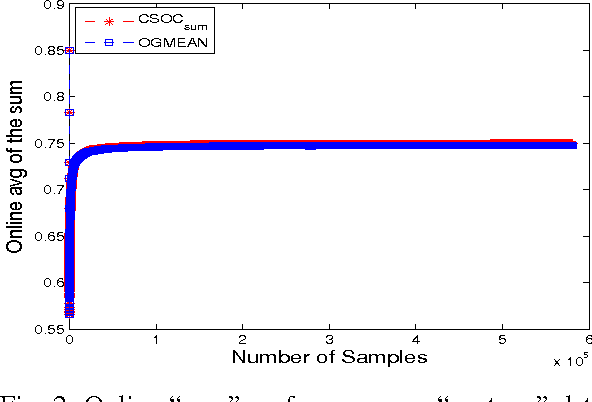


Anomaly detection is an important task in many real world applications such as fraud detection, suspicious activity detection, health care monitoring etc. In this paper, we tackle this problem from supervised learning perspective in online learning setting. We maximize well known \emph{Gmean} metric for class-imbalance learning in online learning framework. Specifically, we show that maximizing \emph{Gmean} is equivalent to minimizing a convex surrogate loss function and based on that we propose novel online learning algorithm for anomaly detection. We then show, by extensive experiments, that the performance of the proposed algorithm with respect to $sum$ metric is as good as a recently proposed Cost-Sensitive Online Classification(CSOC) algorithm for class-imbalance learning over various benchmarked data sets while keeping running time close to the perception algorithm. Our another conclusion is that other competitive online algorithms do not perform consistently over data sets of varying size. This shows the potential applicability of our proposed approach.