 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMMA: Laplacian pyramids for Efficient Marine SeMAntic Segmentation
Mar 26, 2026Semantic segmentation in marine environments is crucial for the autonomous navigation of unmanned surface vessels (USVs) and coastal Earth Observation events such as oil spills. However, existing methods, often relying on deep CNNs and transformer-based architectures, face challenges in deployment due to their high computational costs and resource-intensive nature. These limitations hinder the practicality of real-time, low-cost applications in real-world marine settings. To address this, we propose LEMMA, a lightweight semantic segmentation model designed specifically for accurate remote sensing segmentation under resource constraints. The proposed architecture leverages Laplacian Pyramids to enhance edge recognition, a critical component for effective feature extraction in complex marine environments for disaster response, environmental surveillance, and coastal monitoring. By integrating edge information early in the feature extraction process, LEMMA eliminates the need for computationally expensive feature map computations in deeper network layers, drastically reducing model size, complexity and inference time. LEMMA demonstrates state-of-the-art performance across datasets captured from diverse platforms while reducing trainable parameters and computational requirements by up to 71x, GFLOPs by up to 88.5\%, and inference time by up to 84.65\%, as compared to existing models. Experimental results highlight its effectiveness and real-world applicability, including 93.42\% IoU on the Oil Spill dataset and 98.97\% mIoU on Mastr1325.
LapLoss: Laplacian Pyramid-based Multiscale loss for Image Translation
Mar 07, 2025Contrast enhancement, a key aspect of image-to-image translation (I2IT), improves visual quality by adjusting intensity differences between pixels. However, many existing methods struggle to preserve fine-grained details, often leading to the loss of low-level features. This paper introduces LapLoss, a novel approach designed for I2IT contrast enhancement, based on the Laplacian pyramid-centric networks, forming the core of our proposed methodology. The proposed approach employs a multiple discriminator architecture, each operating at a different resolution to capture high-level features, in addition to maintaining low-level details and textures under mixed lighting conditions. The proposed methodology computes the loss at multiple scales, balancing reconstruction accuracy and perceptual quality to enhance overall image generation. The distinct blend of the loss calculation at each level of the pyramid, combined with the architecture of the Laplacian pyramid enables LapLoss to exceed contemporary contrast enhancement techniques. This framework achieves state-of-the-art results, consistently performing well across different lighting conditions in the SICE dataset.
DEAL-YOLO: Drone-based Efficient Animal Localization using YOLO
Mar 06, 2025Although advances in deep learning and aerial surveillance technology are improving wildlife conservation efforts, complex and erratic environmental conditions still pose a problem, requiring innovative solutions for cost-effective small animal detection. This work introduces DEAL-YOLO, a novel approach that improves small object detection in Unmanned Aerial Vehicle (UAV) images by using multi-objective loss functions like Wise IoU (WIoU) and Normalized Wasserstein Distance (NWD), which prioritize pixels near the centre of the bounding box, ensuring smoother localization and reducing abrupt deviations. Additionally, the model is optimized through efficient feature extraction with Linear Deformable (LD) convolutions, enhancing accuracy while maintaining computational efficiency. The Scaled Sequence Feature Fusion (SSFF) module enhances object detection by effectively capturing inter-scale relationships, improving feature representation, and boosting metrics through optimized multiscale fusion. Comparison with baseline models reveals high efficacy with up to 69.5\% fewer parameters compared to vanilla Yolov8-N, highlighting the robustness of the proposed modifications. Through this approach, our paper aims to facilitate the detection of endangered species, animal population analysis, habitat monitoring, biodiversity research, and various other applications that enrich wildlife conservation efforts. DEAL-YOLO employs a two-stage inference paradigm for object detection, refining selected regions to improve localization and confidence. This approach enhances performance, especially for small instances with low objectness scores.
LapGSR: Laplacian Reconstructive Network for Guided Thermal Super-Resolution
Nov 12, 2024



In the last few years, the fusion of multi-modal data has been widely studied for various applications such as robotics, gesture recognition, and autonomous navigation. Indeed, high-quality visual sensors are expensive, and consumer-grade sensors produce low-resolution images. Researchers have developed methods to combine RGB color images with non-visual data, such as thermal, to overcome this limitation to improve resolution. Fusing multiple modalities to produce visually appealing, high-resolution images often requires dense models with millions of parameters and a heavy computational load, which is commonly attributed to the intricate architecture of the model. We propose LapGSR, a multimodal, lightweight, generative model incorporating Laplacian image pyramids for guided thermal super-resolution. This approach uses a Laplacian Pyramid on RGB color images to extract vital edge information, which is then used to bypass heavy feature map computation in the higher layers of the model in tandem with a combined pixel and adversarial loss. LapGSR preserves the spatial and structural details of the image while also being efficient and compact. This results in a model with significantly fewer parameters than other SOTA models while demonstrating excellent results on two cross-domain datasets viz. ULB17-VT and VGTSR datasets.
TLDR: Traffic Light Detection using Fourier Domain Adaptation in Hostile WeatheR
Nov 12, 2024

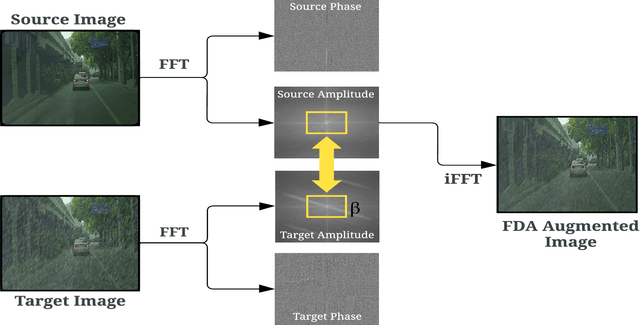

The scarcity of comprehensive datasets in the traffic light detection and recognition domain and the poor performance of state-of-the-art models under hostile weather conditions present significant challenges. To address these issues, this paper proposes a novel approach by merging two widely used datasets, LISA and S2TLD. The merged dataset is further processed to tackle class imbalance, a common problem in this domain. This merged dataset becomes our source domain. Synthetic rain and fog are added to the dataset to create our target domain. We employ Fourier Domain Adaptation (FDA) to create a final dataset with a minimized domain gap between the two datasets, helping the model trained on this final dataset adapt to rainy and foggy weather conditions. Additionally, we explore Semi-Supervised Learning (SSL) techniques to leverage the available data more effectively. Experimental results demonstrate that models trained on FDA-augmented images outperform those trained without FDA across confidence-dependent and independent metrics, like mAP50, mAP50-95, Precision, and Recall. The best-performing model, YOLOv8, achieved a Precision increase of 5.1860%, Recall increase of 14.8009%, mAP50 increase of 9.5074%, and mAP50-95 increase of 19.5035%. On average, percentage increases of 7.6892% in Precision, 19.9069% in Recall, 15.8506% in mAP50, and 23.8099% in mAP50-95 were observed across all models, highlighting the effectiveness of FDA in mitigating the impact of adverse weather conditions on model performance. These improvements pave the way for real-world applications where reliable performance in challenging environmental conditions is critical.