 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMMA: Laplacian pyramids for Efficient Marine SeMAntic Segmentation
Mar 26, 2026Semantic segmentation in marine environments is crucial for the autonomous navigation of unmanned surface vessels (USVs) and coastal Earth Observation events such as oil spills. However, existing methods, often relying on deep CNNs and transformer-based architectures, face challenges in deployment due to their high computational costs and resource-intensive nature. These limitations hinder the practicality of real-time, low-cost applications in real-world marine settings. To address this, we propose LEMMA, a lightweight semantic segmentation model designed specifically for accurate remote sensing segmentation under resource constraints. The proposed architecture leverages Laplacian Pyramids to enhance edge recognition, a critical component for effective feature extraction in complex marine environments for disaster response, environmental surveillance, and coastal monitoring. By integrating edge information early in the feature extraction process, LEMMA eliminates the need for computationally expensive feature map computations in deeper network layers, drastically reducing model size, complexity and inference time. LEMMA demonstrates state-of-the-art performance across datasets captured from diverse platforms while reducing trainable parameters and computational requirements by up to 71x, GFLOPs by up to 88.5\%, and inference time by up to 84.65\%, as compared to existing models. Experimental results highlight its effectiveness and real-world applicability, including 93.42\% IoU on the Oil Spill dataset and 98.97\% mIoU on Mastr1325.
Multicollinearity-Aware Parameter-Free Strategy for Hyperspectral Band Selection: A Dependence Measures-Based Approach
Sep 26, 2025Hyperspectral bands offer rich spectral and spatial information; however, their high dimensionality poses challenges for efficient processing. Band selection (BS) methods aim to extract a smaller subset of bands to reduce spectral redundancy. Existing approaches, such as ranking-based, clustering-based, and iterative methods, often suffer from issues like sensitivity to initialization, parameter tuning, and high computational cost. This work introduces a BS strategy integrating three dependence measures: Average Band Correlation (ABC) and Mutual Information (MI), and Variance Inflation Factor (VIF). ABC quantifies linear correlations between spectral bands, while MI measures uncertainty reduction relative to ground truth labels. To address multicollinearity and reduce the search space, the approach first applies a VIF-based pre-selection of spectral bands. Subsequently, a clustering algorithm is used to identify the optimal subset of bands based on the ABC and MI values. Unlike previous methods, this approach is completely parameter-free for hyperspectral band selection, eliminating the need for optimal parameter estimation. The proposed method is evaluated on four standard benchmark datasets: WHU-Hi-LongKou, Pavia University, Salinas, and Oil Spill datasets, and is compared to existing state-of-the-art approaches. There is significant overlap between the bands identified by our proposed method and those selected by other methods, indicating that our approach effectively captures the most relevant spectral features. Further, support vector machine (SVM) classification validates that VIF-driven pruning enhances classification by minimizing multicollinearity. Ablation studies confirm that combining ABC with MI yields robust, discriminative band subsets.
DEAL-YOLO: Drone-based Efficient Animal Localization using YOLO
Mar 06, 2025Although advances in deep learning and aerial surveillance technology are improving wildlife conservation efforts, complex and erratic environmental conditions still pose a problem, requiring innovative solutions for cost-effective small animal detection. This work introduces DEAL-YOLO, a novel approach that improves small object detection in Unmanned Aerial Vehicle (UAV) images by using multi-objective loss functions like Wise IoU (WIoU) and Normalized Wasserstein Distance (NWD), which prioritize pixels near the centre of the bounding box, ensuring smoother localization and reducing abrupt deviations. Additionally, the model is optimized through efficient feature extraction with Linear Deformable (LD) convolutions, enhancing accuracy while maintaining computational efficiency. The Scaled Sequence Feature Fusion (SSFF) module enhances object detection by effectively capturing inter-scale relationships, improving feature representation, and boosting metrics through optimized multiscale fusion. Comparison with baseline models reveals high efficacy with up to 69.5\% fewer parameters compared to vanilla Yolov8-N, highlighting the robustness of the proposed modifications. Through this approach, our paper aims to facilitate the detection of endangered species, animal population analysis, habitat monitoring, biodiversity research, and various other applications that enrich wildlife conservation efforts. DEAL-YOLO employs a two-stage inference paradigm for object detection, refining selected regions to improve localization and confidence. This approach enhances performance, especially for small instances with low objectness scores.
Correlation-Based Band Selection for Hyperspectral Image Classification
Jan 24, 2025


Hyperspectral images offer extensive spectral information about ground objects across multiple spectral bands. However, the large volume of data can pose challenges during processing. Typically, adjacent bands in hyperspectral data are highly correlated, leading to the use of only a few selected bands for various applications. In this work, we present a correlation-based band selection approach for hyperspectral image classification. Our approach calculates the average correlation between bands using correlation coefficients to identify the relationships among different bands. Afterward, we select a subset of bands by analyzing the average correlation and applying a threshold-based method. This allows us to isolate and retain bands that exhibit lower inter-band dependencies, ensuring that the selected bands provide diverse and non-redundant information. We evaluate our proposed approach on two standard benchmark datasets: Pavia University (PA) and Salinas Valley (SA), focusing on image classification tasks. The experimental results demonstrate that our method performs competitively with other standard band selection approaches.
HipyrNet: Hypernet-Guided Feature Pyramid network for mixed-exposure correction
Jan 09, 2025



Recent advancements in image translation for enhancing mixed-exposure images have demonstrated the transformative potential of deep learning algorithms. However, addressing extreme exposure variations in images remains a significant challenge due to the inherent complexity and contrast inconsistencies across regions. Current methods often struggle to adapt effectively to these variations, resulting in suboptimal performance. In this work, we propose HipyrNet, a novel approach that integrates a HyperNetwork within a Laplacian Pyramid-based framework to tackle the challenges of mixed-exposure image enhancement. The inclusion of a HyperNetwork allows the model to adapt to these exposure variations. HyperNetworks dynamically generates weights for another network, allowing dynamic changes during deployment. In our model, the HyperNetwork employed is used to predict optimal kernels for Feature Pyramid decomposition, which enables a tailored and adaptive decomposition process for each input image. Our enhanced translational network incorporates multiscale decomposition and reconstruction, leveraging dynamic kernel prediction to capture and manipulate features across varying scales. Extensive experiments demonstrate that HipyrNet outperforms existing methods, particularly in scenarios with extreme exposure variations, achieving superior results in both qualitative and quantitative evaluations. Our approach sets a new benchmark for mixed-exposure image enhancement, paving the way for future research in adaptive image translation.
TLDR: Traffic Light Detection using Fourier Domain Adaptation in Hostile WeatheR
Nov 12, 2024

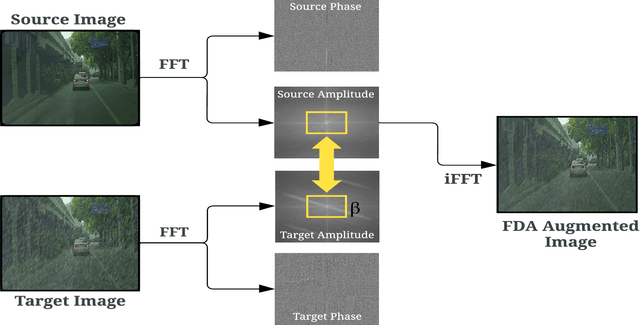

The scarcity of comprehensive datasets in the traffic light detection and recognition domain and the poor performance of state-of-the-art models under hostile weather conditions present significant challenges. To address these issues, this paper proposes a novel approach by merging two widely used datasets, LISA and S2TLD. The merged dataset is further processed to tackle class imbalance, a common problem in this domain. This merged dataset becomes our source domain. Synthetic rain and fog are added to the dataset to create our target domain. We employ Fourier Domain Adaptation (FDA) to create a final dataset with a minimized domain gap between the two datasets, helping the model trained on this final dataset adapt to rainy and foggy weather conditions. Additionally, we explore Semi-Supervised Learning (SSL) techniques to leverage the available data more effectively. Experimental results demonstrate that models trained on FDA-augmented images outperform those trained without FDA across confidence-dependent and independent metrics, like mAP50, mAP50-95, Precision, and Recall. The best-performing model, YOLOv8, achieved a Precision increase of 5.1860%, Recall increase of 14.8009%, mAP50 increase of 9.5074%, and mAP50-95 increase of 19.5035%. On average, percentage increases of 7.6892% in Precision, 19.9069% in Recall, 15.8506% in mAP50, and 23.8099% in mAP50-95 were observed across all models, highlighting the effectiveness of FDA in mitigating the impact of adverse weather conditions on model performance. These improvements pave the way for real-world applications where reliable performance in challenging environmental conditions is critical.
LapGSR: Laplacian Reconstructive Network for Guided Thermal Super-Resolution
Nov 12, 2024



In the last few years, the fusion of multi-modal data has been widely studied for various applications such as robotics, gesture recognition, and autonomous navigation. Indeed, high-quality visual sensors are expensive, and consumer-grade sensors produce low-resolution images. Researchers have developed methods to combine RGB color images with non-visual data, such as thermal, to overcome this limitation to improve resolution. Fusing multiple modalities to produce visually appealing, high-resolution images often requires dense models with millions of parameters and a heavy computational load, which is commonly attributed to the intricate architecture of the model. We propose LapGSR, a multimodal, lightweight, generative model incorporating Laplacian image pyramids for guided thermal super-resolution. This approach uses a Laplacian Pyramid on RGB color images to extract vital edge information, which is then used to bypass heavy feature map computation in the higher layers of the model in tandem with a combined pixel and adversarial loss. LapGSR preserves the spatial and structural details of the image while also being efficient and compact. This results in a model with significantly fewer parameters than other SOTA models while demonstrating excellent results on two cross-domain datasets viz. ULB17-VT and VGTSR datasets.
SolarPanel Segmentation :Self-Supervised Learning for Imperfect Datasets
Feb 20, 2024

The increasing adoption of solar energy necessitates advanced methodologies for monitoring and maintenance to ensure optimal performance of solar panel installations. A critical component in this context is the accurate segmentation of solar panels from aerial or satellite imagery, which is essential for identifying operational issues and assessing efficiency. This paper addresses the significant challenges in panel segmentation, particularly the scarcity of annotated data and the labour-intensive nature of manual annotation for supervised learning. We explore and apply Self-Supervised Learning (SSL) to solve these challenges. We demonstrate that SSL significantly enhances model generalization under various conditions and reduces dependency on manually annotated data, paving the way for robust and adaptable solar panel segmentation solutions.
There Are No Data Like More Data- Datasets for Deep Learning in Earth Observation
Oct 30, 2023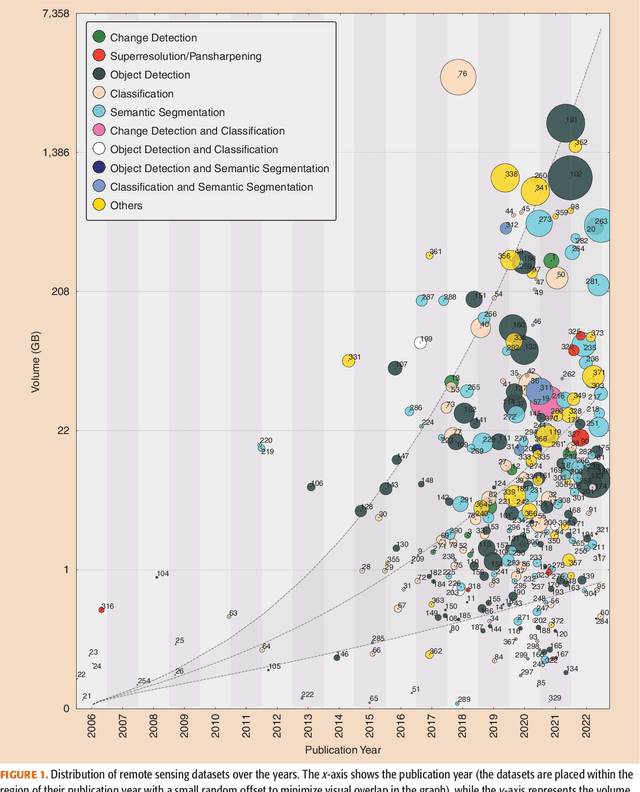

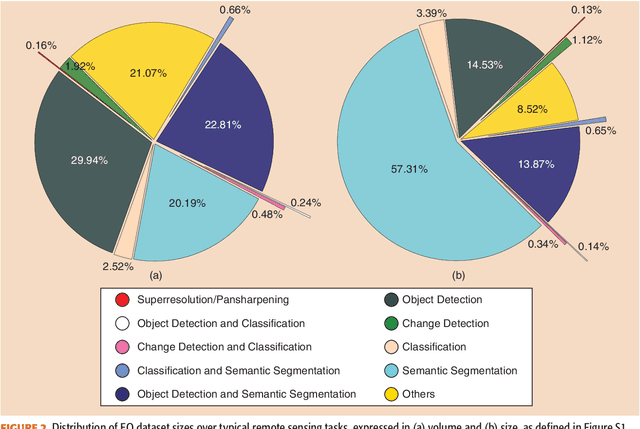
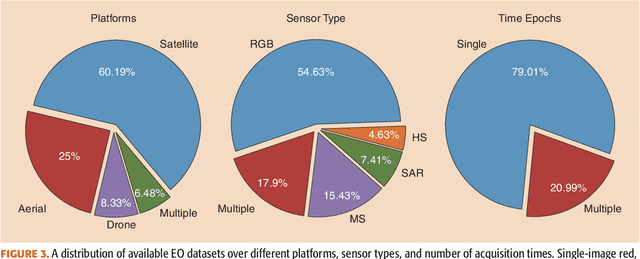
Carefully curated and annotated datasets are the foundation of machine learning, with particularly data-hungry deep neural networks forming the core of what is often called Artificial Intelligence (AI). Due to the massive success of deep learning applied to Earth Observation (EO) problems, the focus of the community has been largely on the development of ever-more sophisticated deep neural network architectures and training strategies largely ignoring the overall importance of datasets. For that purpose, numerous task-specific datasets have been created that were largely ignored by previously published review articles on AI for Earth observation. With this article, we want to change the perspective and put machine learning datasets dedicated to Earth observation data and applications into the spotlight. Based on a review of the historical developments, currently available resources are described and a perspective for future developments is formed. We hope to contribute to an understanding that the nature of our data is what distinguishes the Earth observation community from many other communities that apply deep learning techniques to image data, and that a detailed understanding of EO data peculiarities is among the core competencies of our discipline.
Cross-Geography Generalization of Machine Learning Methods for Classification of Flooded Regions in Aerial Images
Oct 04, 2022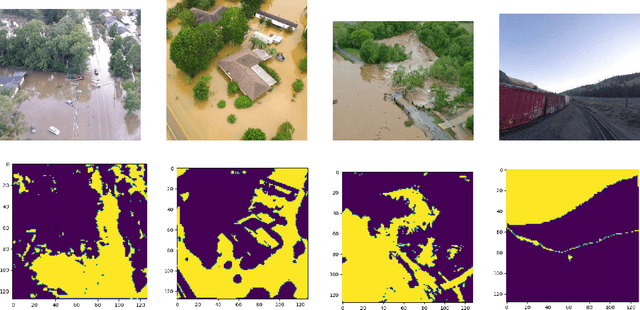
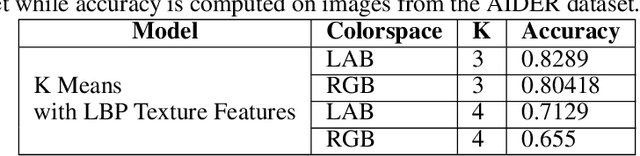
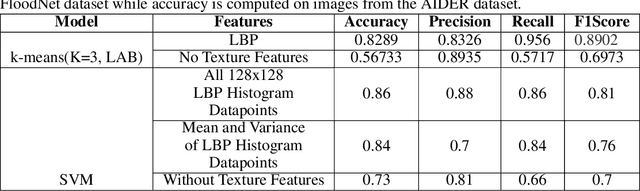
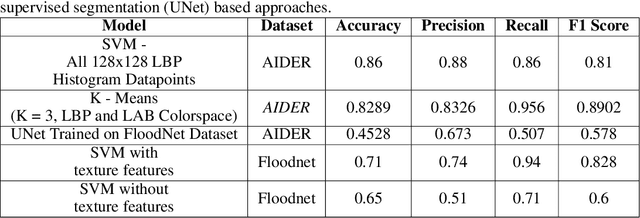
Identification of regions affected by floods is a crucial piece of information required for better planning and management of post-disaster relief and rescue efforts. Traditionally, remote sensing images are analysed to identify the extent of damage caused by flooding. The data acquired from sensors onboard earth observation satellites are analyzed to detect the flooded regions, which can be affected by low spatial and temporal resolution. However, in recent years, the images acquired from Unmanned Aerial Vehicles (UAVs) have also been utilized to assess post-disaster damage. Indeed, a UAV based platform can be rapidly deployed with a customized flight plan and minimum dependence on the ground infrastructure. This work proposes two approaches for identifying flooded regions in UAV aerial images. The first approach utilizes texture-based unsupervised segmentation to detect flooded areas, while the second uses an artificial neural network on the texture features to classify images as flooded and non-flooded. Unlike the existing works where the models are trained and tested on images of the same geographical regions, this work studies the performance of the proposed model in identifying flooded regions across geographical regions. An F1-score of 0.89 is obtained using the proposed segmentation-based approach which is higher than existing classifiers. The robustness of the proposed approach demonstrates that it can be utilized to identify flooded regions of any region with minimum or no user intervention.