 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Foundation Models for Zero-Shot Ship Instance Segmentation in SAR Imagery
Apr 20, 2026Synthetic Aperture Radar (SAR) plays a critical role in maritime surveillance, yet deep learning for SAR analysis is limited by the lack of pixel-level annotations. This paper explores how general-purpose vision foundation models can enable zero-shot ship instance segmentation in SAR imagery, eliminating the need for pixel-level supervision. A YOLOv11-based detector trained on open SAR datasets localizes ships via bounding boxes, which then prompt the Segment Anything Model 2 (SAM2) to produce instance masks without any mask annotations. Unlike prior SAM-based SAR approaches that rely on fine tuning or adapters, our method demonstrates that spatial constraints from a SAR-trained detector alone can effectively regularize foundation model predictions. This design partially mitigates the optical-SAR domain gap and enables downstream applications such as vessel classification, size estimation, and wake analysis. Experiments on the SSDD benchmark achieve a mean IoU of 0.637 (89% of a fully supervised baseline) with an overall ship detection rate of 89.2%, confirming a scalable, annotation-efficient pathway toward foundation-model-driven SAR image understanding.
Location Is All You Need: Continuous Spatiotemporal Neural Representations of Earth Observation Data
Apr 09, 2026In this work, we present LIANet (Location Is All You Need Network), a coordinate-based neural representation that models multi-temporal spaceborne Earth observation (EO) data for a given region of interest as a continuous spatiotemporal neural field. Given only spatial and temporal coordinates, LIANet reconstructs the corresponding satellite imagery. Once pretrained, this neural representation can be adapted to various EO downstream tasks, such as semantic segmentation or pixel-wise regression, importantly, without requiring access to the original satellite data. LIANet intends to serve as a user-friendly alternative to Geospatial Foundation Models (GFMs) by eliminating the overhead of data access and preprocessing for end-users and enabling fine-tuning solely based on labels. We demonstrate the pretraining of LIANet across target areas of varying sizes and show that fine-tuning it for downstream tasks achieves competitive performance compared to training from scratch or using established GFMs. The source code and datasets are publicly available at https://github.com/mojganmadadi/LIANet/tree/v1.0.1.
HyBiomass: Global Hyperspectral Imagery Benchmark Dataset for Evaluating Geospatial Foundation Models in Forest Aboveground Biomass Estimation
Jun 12, 2025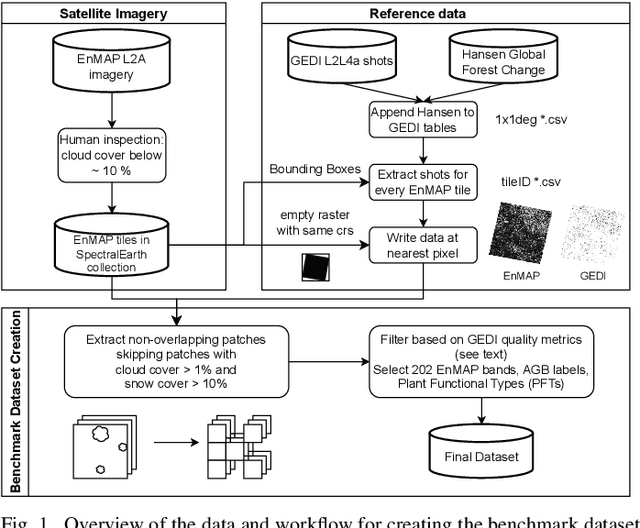
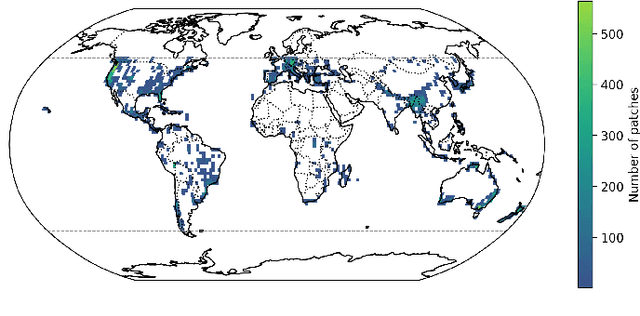
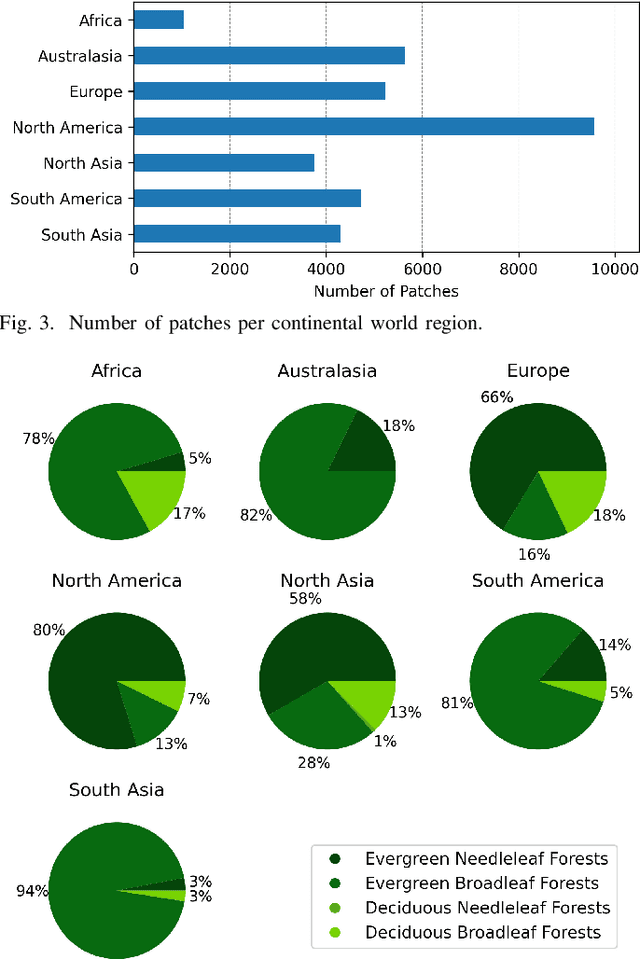
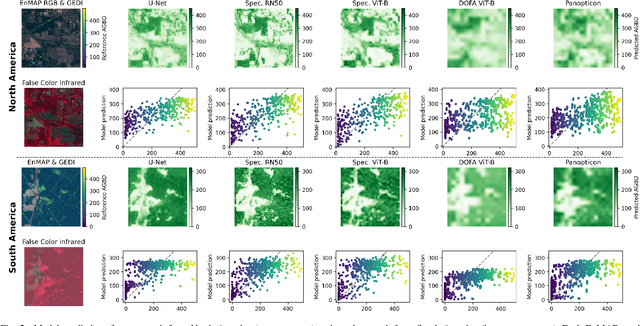
Comprehensive evaluation of geospatial foundation models (Geo-FMs) requires benchmarking across diverse tasks, sensors, and geographic regions. However, most existing benchmark datasets are limited to segmentation or classification tasks, and focus on specific geographic areas. To address this gap, we introduce a globally distributed dataset for forest aboveground biomass (AGB) estimation, a pixel-wise regression task. This benchmark dataset combines co-located hyperspectral imagery (HSI) from the Environmental Mapping and Analysis Program (EnMAP) satellite and predictions of AGB density estimates derived from the Global Ecosystem Dynamics Investigation lidars, covering seven continental regions. Our experimental results on this dataset demonstrate that the evaluated Geo-FMs can match or, in some cases, surpass the performance of a baseline U-Net, especially when fine-tuning the encoder. We also find that the performance difference between the U-Net and Geo-FMs depends on the dataset size for each region and highlight the importance of the token patch size in the Vision Transformer backbone for accurate predictions in pixel-wise regression tasks. By releasing this globally distributed hyperspectral benchmark dataset, we aim to facilitate the development and evaluation of Geo-FMs for HSI applications. Leveraging this dataset additionally enables research into geographic bias and generalization capacity of Geo-FMs. The dataset and source code will be made publicly available.
SARFormer -- An Acquisition Parameter Aware Vision Transformer for Synthetic Aperture Radar Data
Apr 11, 2025This manuscript introduces SARFormer, a modified Vision Transformer (ViT) architecture designed for processing one or multiple synthetic aperture radar (SAR) images. Given the complex image geometry of SAR data, we propose an acquisition parameter encoding module that significantly guides the learning process, especially in the case of multiple images, leading to improved performance on downstream tasks. We further explore self-supervised pre-training, conduct experiments with limited labeled data, and benchmark our contribution and adaptations thoroughly in ablation experiments against a baseline, where the model is tested on tasks such as height reconstruction and segmentation. Our approach achieves up to 17% improvement in terms of RMSE over baseline models
MIMRS: A Survey on Masked Image Modeling in Remote Sensing
Apr 07, 2025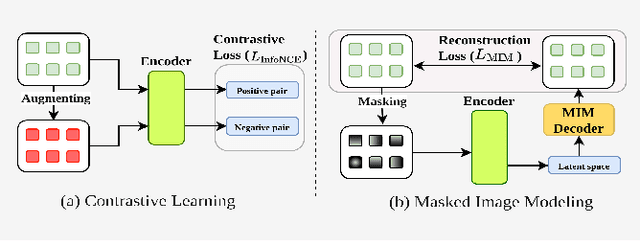


Masked Image Modeling (MIM) is a self-supervised learning technique that involves masking portions of an image, such as pixels, patches, or latent representations, and training models to predict the missing information using the visible context. This approach has emerged as a cornerstone in self-supervised learning, unlocking new possibilities in visual understanding by leveraging unannotated data for pre-training. In remote sensing, MIM addresses challenges such as incomplete data caused by cloud cover, occlusions, and sensor limitations, enabling applications like cloud removal, multi-modal data fusion, and super-resolution. By synthesizing and critically analyzing recent advancements, this survey (MIMRS) is a pioneering effort to chart the landscape of mask image modeling in remote sensing. We highlight state-of-the-art methodologies, applications, and future research directions, providing a foundational review to guide innovation in this rapidly evolving field.
Distribution Shifts at Scale: Out-of-distribution Detection in Earth Observation
Dec 18, 2024Training robust deep learning models is critical in Earth Observation, where globally deployed models often face distribution shifts that degrade performance, especially in low-data regions. Out-of-distribution (OOD) detection addresses this challenge by identifying inputs that differ from in-distribution (ID) data. However, existing methods either assume access to OOD data or compromise primary task performance, making them unsuitable for real-world deployment. We propose TARDIS, a post-hoc OOD detection method for scalable geospatial deployments. The core novelty lies in generating surrogate labels by integrating information from ID data and unknown distributions, enabling OOD detection at scale. Our method takes a pre-trained model, ID data, and WILD samples, disentangling the latter into surrogate ID and surrogate OOD labels based on internal activations, and fits a binary classifier as an OOD detector. We validate TARDIS on EuroSAT and xBD datasets, across 17 experimental setups covering covariate and semantic shifts, showing that it performs close to the theoretical upper bound in assigning surrogate ID and OOD samples in 13 cases. To demonstrate scalability, we deploy TARDIS on the Fields of the World dataset, offering actionable insights into pre-trained model behavior for large-scale deployments. The code is publicly available at https://github.com/microsoft/geospatial-ood-detection.
SenPa-MAE: Sensor Parameter Aware Masked Autoencoder for Multi-Satellite Self-Supervised Pretraining
Aug 20, 2024This paper introduces SenPa-MAE, a transformer architecture that encodes the sensor parameters of an observed multispectral signal into the image embeddings. SenPa-MAE can be pre-trained on imagery of different satellites with non-matching spectral or geometrical sensor characteristics. To incorporate sensor parameters, we propose a versatile sensor parameter encoding module as well as a data augmentation strategy for the diversification of the pre-training dataset. This enables the model to effectively differentiate between various sensors and gain an understanding of sensor parameters and the correlation to the observed signal. Given the rising number of Earth observation satellite missions and the diversity in their sensor specifications, our approach paves the way towards a sensor-independent Earth observation foundation model. This opens up possibilities such as cross-sensor training and sensor-independent inference.
Mapping Land Naturalness from Sentinel-2 using Deep Contextual and Geographical Priors
Jun 27, 2024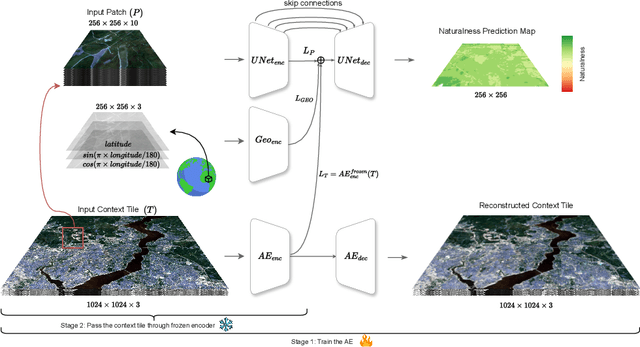
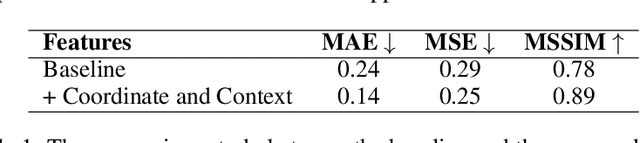
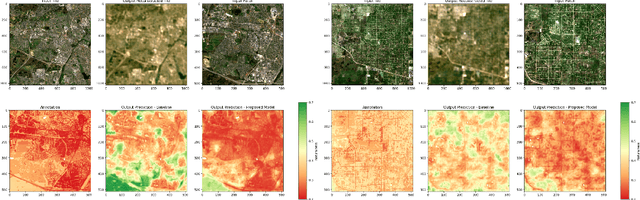

In recent decades, the causes and consequences of climate change have accelerated, affecting our planet on an unprecedented scale. This change is closely tied to the ways in which humans alter their surroundings. As our actions continue to impact natural areas, using satellite images to observe and measure these effects has become crucial for understanding and combating climate change. Aiming to map land naturalness on the continuum of modern human pressure, we have developed a multi-modal supervised deep learning framework that addresses the unique challenges of satellite data and the task at hand. We incorporate contextual and geographical priors, represented by corresponding coordinate information and broader contextual information, including and surrounding the immediate patch to be predicted. Our framework improves the model's predictive performance in mapping land naturalness from Sentinel-2 data, a type of multi-spectral optical satellite imagery. Recognizing that our protective measures are only as effective as our understanding of the ecosystem, quantifying naturalness serves as a crucial step toward enhancing our environmental stewardship.
There Are No Data Like More Data- Datasets for Deep Learning in Earth Observation
Oct 30, 2023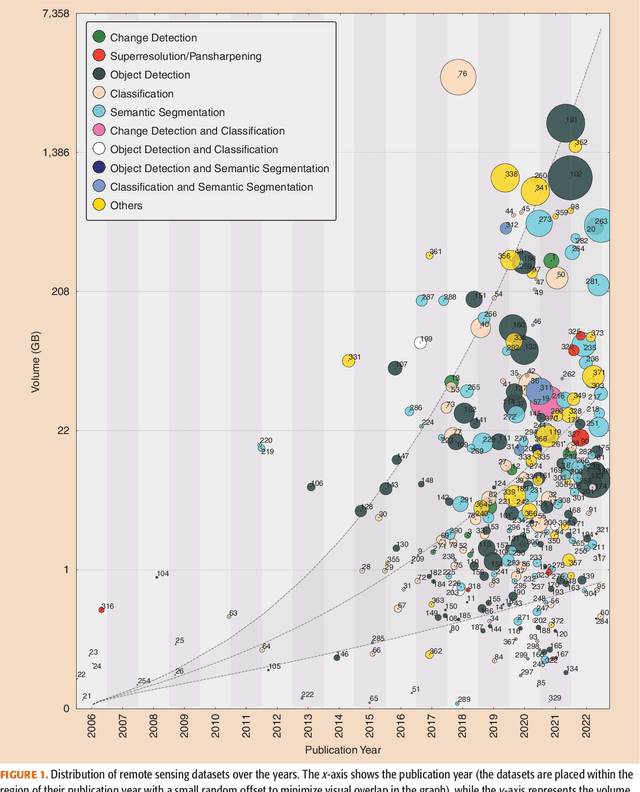

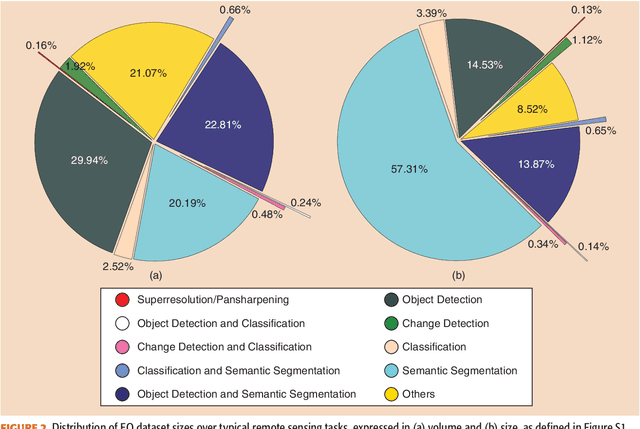
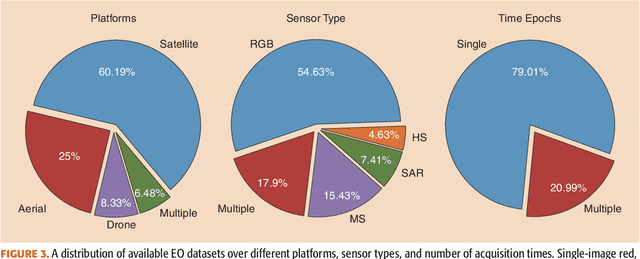
Carefully curated and annotated datasets are the foundation of machine learning, with particularly data-hungry deep neural networks forming the core of what is often called Artificial Intelligence (AI). Due to the massive success of deep learning applied to Earth Observation (EO) problems, the focus of the community has been largely on the development of ever-more sophisticated deep neural network architectures and training strategies largely ignoring the overall importance of datasets. For that purpose, numerous task-specific datasets have been created that were largely ignored by previously published review articles on AI for Earth observation. With this article, we want to change the perspective and put machine learning datasets dedicated to Earth observation data and applications into the spotlight. Based on a review of the historical developments, currently available resources are described and a perspective for future developments is formed. We hope to contribute to an understanding that the nature of our data is what distinguishes the Earth observation community from many other communities that apply deep learning techniques to image data, and that a detailed understanding of EO data peculiarities is among the core competencies of our discipline.
A Benchmarking Protocol for SAR Colorization: From Regression to Deep Learning Approaches
Oct 12, 2023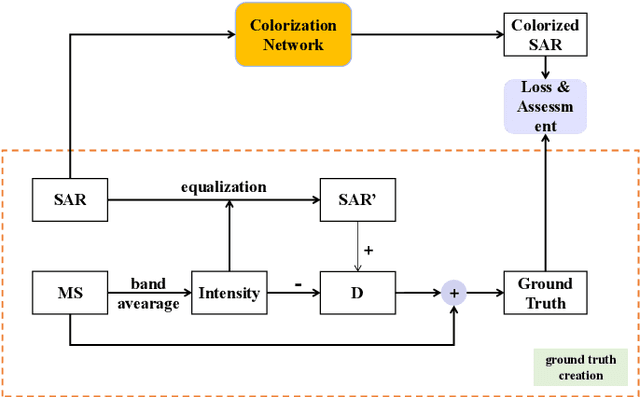



Synthetic aperture radar (SAR) images are widely used in remote sensing. Interpreting SAR images can be challenging due to their intrinsic speckle noise and grayscale nature. To address this issue, SAR colorization has emerged as a research direction to colorize gray scale SAR images while preserving the original spatial information and radiometric information. However, this research field is still in its early stages, and many limitations can be highlighted. In this paper, we propose a full research line for supervised learning-based approaches to SAR colorization. Our approach includes a protocol for generating synthetic color SAR images, several baselines, and an effective method based on the conditional generative adversarial network (cGAN) for SAR colorization. We also propose numerical assessment metrics for the problem at hand. To our knowledge, this is the first attempt to propose a research line for SAR colorization that includes a protocol, a benchmark, and a complete performance evaluation. Our extensive tests demonstrate the effectiveness of our proposed cGAN-based network for SAR colorization. The code will be made publicly available.