 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree crop mapping of South America reveals links to deforestation and conservation
Feb 19, 2026Monitoring tree crop expansion is vital for zero-deforestation policies like the European Union's Regulation on Deforestation-free Products (EUDR). However, these efforts are hindered by a lack of highresolution data distinguishing diverse agricultural systems from forests. Here, we present the first 10m-resolution tree crop map for South America, generated using a multi-modal, spatio-temporal deep learning model trained on Sentinel-1 and Sentinel-2 satellite imagery time series. The map identifies approximately 11 million hectares of tree crops, 23% of which is linked to 2000-2020 forest cover loss. Critically, our analysis reveals that existing regulatory maps supporting the EUDR often classify established agriculture, particularly smallholder agroforestry, as "forest". This discrepancy risks false deforestation alerts and unfair penalties for small-scale farmers. Our work mitigates this risk by providing a high-resolution baseline, supporting conservation policies that are effective, inclusive, and equitable.
GSR4B: Biomass Map Super-Resolution with Sentinel-1/2 Guidance
Apr 03, 2025

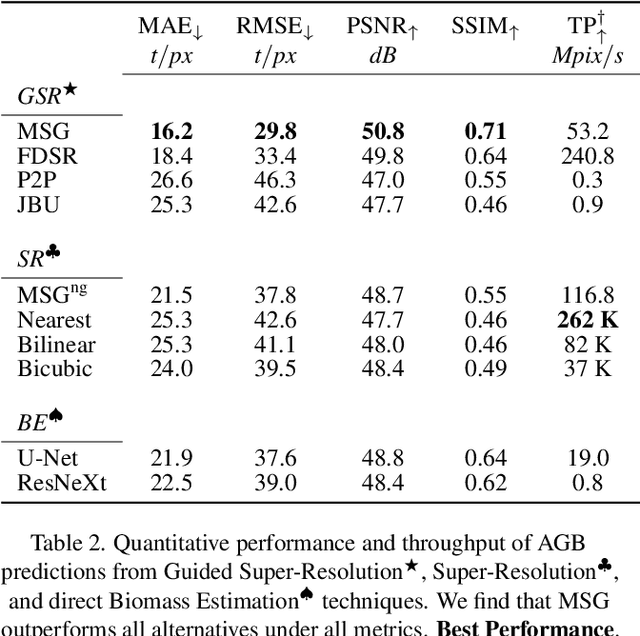

Accurate Above-Ground Biomass (AGB) mapping at both large scale and high spatio-temporal resolution is essential for applications ranging from climate modeling to biodiversity assessment, and sustainable supply chain monitoring. At present, fine-grained AGB mapping relies on costly airborne laser scanning acquisition campaigns usually limited to regional scales. Initiatives such as the ESA CCI map attempt to generate global biomass products from diverse spaceborne sensors but at a coarser resolution. To enable global, high-resolution (HR) mapping, several works propose to regress AGB from HR satellite observations such as ESA Sentinel-1/2 images. We propose a novel way to address HR AGB estimation, by leveraging both HR satellite observations and existing low-resolution (LR) biomass products. We cast this problem as Guided Super-Resolution (GSR), aiming at upsampling LR biomass maps (sources) from $100$ to $10$ m resolution, using auxiliary HR co-registered satellite images (guides). We compare super-resolving AGB maps with and without guidance, against direct regression from satellite images, on the public BioMassters dataset. We observe that Multi-Scale Guidance (MSG) outperforms direct regression both for regression ($-780$ t/ha RMSE) and perception ($+2.0$ dB PSNR) metrics, and better captures high-biomass values, without significant computational overhead. Interestingly, unlike the RGB+Depth setting they were originally designed for, our best-performing AGB GSR approaches are those that most preserve the guide image texture. Our results make a strong case for adopting the GSR framework for accurate HR biomass mapping at scale. Our code and model weights are made publicly available (https://github.com/kaankaramanofficial/GSR4B).
Deep learning meets tree phenology modeling: PhenoFormer vs. process-based models
Oct 30, 2024
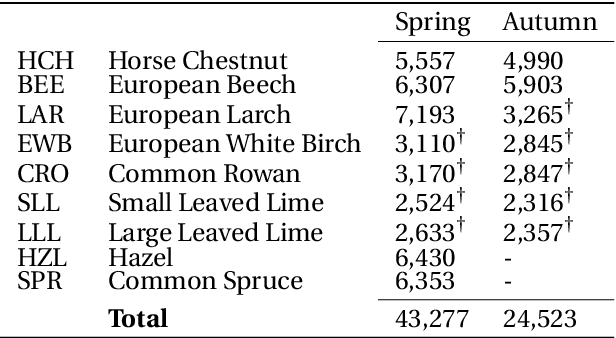

Phenology, the timing of cyclical plant life events such as leaf emergence and coloration, is crucial in the bio-climatic system. Climate change drives shifts in these phenological events, impacting ecosystems and the climate itself. Accurate phenology models are essential to predict the occurrence of these phases under changing climatic conditions. Existing methods include hypothesis-driven process models and data-driven statistical approaches. Process models account for dormancy stages and various phenology drivers, while statistical models typically rely on linear or traditional machine learning techniques. Research shows that process models often outperform statistical methods when predicting under climate conditions outside historical ranges, especially with climate change scenarios. However, deep learning approaches remain underexplored in climate phenology modeling. We introduce PhenoFormer, a neural architecture better suited than traditional statistical methods at predicting phenology under shift in climate data distribution, while also bringing significant improvements or performing on par to the best performing process-based models. Our numerical experiments on a 70-year dataset of 70,000 phenological observations from 9 woody species in Switzerland show that PhenoFormer outperforms traditional machine learning methods by an average of 13% R2 and 1.1 days RMSE for spring phenology, and 11% R2 and 0.7 days RMSE for autumn phenology, while matching or exceeding the best process-based models. Our results demonstrate that deep learning has the potential to be a valuable methodological tool for accurate climate-phenology prediction, and our PhenoFormer is a first promising step in improving phenological predictions before a complete understanding of the underlying physiological mechanisms is available.
An Open-Source Tool for Mapping War Destruction at Scale in Ukraine using Sentinel-1 Time Series
Jun 04, 2024



Access to detailed war impact assessments is crucial for humanitarian organizations to effectively assist populations most affected by armed conflicts. However, maintaining a comprehensive understanding of the situation on the ground is challenging, especially in conflicts that cover vast territories and extend over long periods. This study presents a scalable and transferable method for estimating war-induced damage to buildings. We first train a machine learning model to output pixel-wise probability of destruction from Synthetic Aperture Radar (SAR) satellite image time series, leveraging existing, manual damage assessments as ground truth and cloud-based geospatial analysis tools for large-scale inference. We further post-process these assessments using open building footprints to obtain a final damage estimate per building. We introduce an accessible, open-source tool that allows users to adjust the confidence interval based on their specific requirements and use cases. Our approach enables humanitarian organizations and other actors to rapidly screen large geographic regions for war impacts. We provide two publicly accessible dashboards: a Ukraine Damage Explorer to dynamically view our pre-computed estimates, and a Rapid Damage Mapping Tool to easily run our method and produce custom maps.
Accuracy and Consistency of Space-based Vegetation Height Maps for Forest Dynamics in Alpine Terrain
Sep 04, 2023



Monitoring and understanding forest dynamics is essential for environmental conservation and management. This is why the Swiss National Forest Inventory (NFI) provides countrywide vegetation height maps at a spatial resolution of 0.5 m. Its long update time of 6 years, however, limits the temporal analysis of forest dynamics. This can be improved by using spaceborne remote sensing and deep learning to generate large-scale vegetation height maps in a cost-effective way. In this paper, we present an in-depth analysis of these methods for operational application in Switzerland. We generate annual, countrywide vegetation height maps at a 10-meter ground sampling distance for the years 2017 to 2020 based on Sentinel-2 satellite imagery. In comparison to previous works, we conduct a large-scale and detailed stratified analysis against a precise Airborne Laser Scanning reference dataset. This stratified analysis reveals a close relationship between the model accuracy and the topology, especially slope and aspect. We assess the potential of deep learning-derived height maps for change detection and find that these maps can indicate changes as small as 250 $m^2$. Larger-scale changes caused by a winter storm are detected with an F1-score of 0.77. Our results demonstrate that vegetation height maps computed from satellite imagery with deep learning are a valuable, complementary, cost-effective source of evidence to increase the temporal resolution for national forest assessments.
Mixture of Experts with Uncertainty Voting for Imbalanced Deep Regression Problems
May 24, 2023Data imbalance is ubiquitous when applying machine learning to real-world problems, particularly regression problems. If training data are imbalanced, the learning is dominated by the densely covered regions of the target distribution, consequently, the learned regressor tends to exhibit poor performance in sparsely covered regions. Beyond standard measures like over-sampling or re-weighting, there are two main directions to handle learning from imbalanced data. For regression, recent work relies on the continuity of the distribution; whereas for classification there has been a trend to employ mixture-of-expert models and let some ensemble members specialize in predictions for the sparser regions. Here, we adapt the mixture-of-experts approach to the regression setting. A main question when using this approach is how to fuse the predictions from multiple experts into one output. Drawing inspiration from recent work on probabilistic deep learning, we propose to base the fusion on the aleatoric uncertainties of individual experts, thus obviating the need for a separate aggregation module. In our method, dubbed MOUV, each expert predicts not only an output value but also its uncertainty, which in turn serves as a statistically motivated criterion to rely on the right experts. We compare our method with existing alternatives on multiple public benchmarks and show that MOUV consistently outperforms the prior art, while at the same time producing better calibrated uncertainty estimates. Our code is available at link-upon-publication.
U-TILISE: A Sequence-to-sequence Model for Cloud Removal in Optical Satellite Time Series
May 22, 2023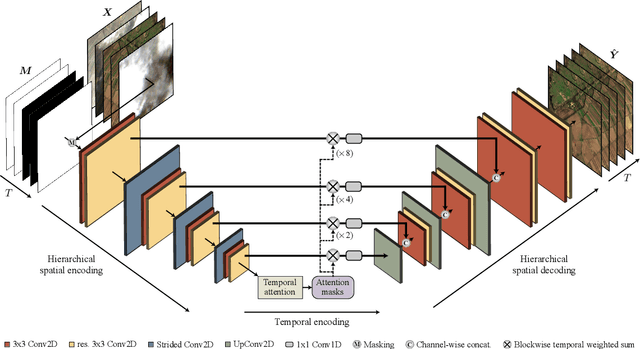
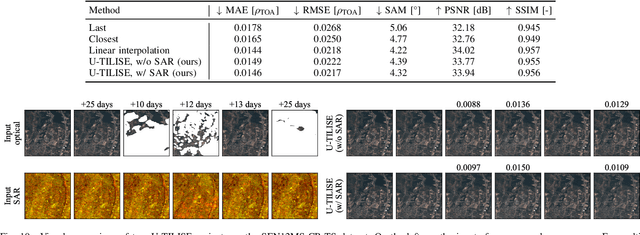
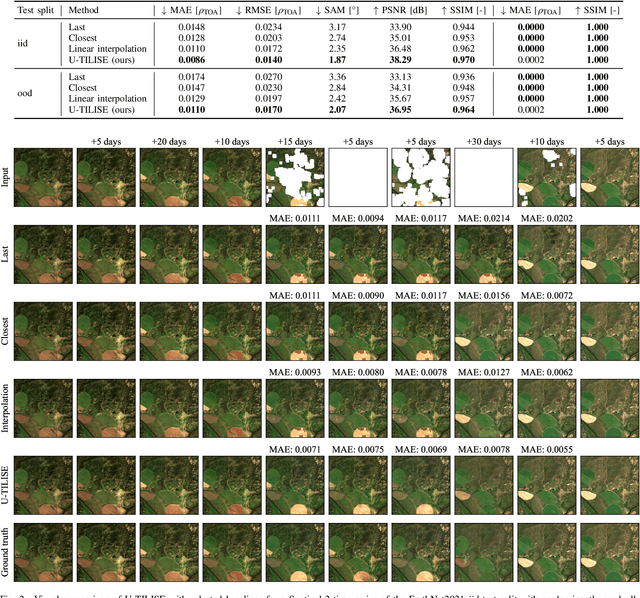

Satellite image time series in the optical and infrared spectrum suffer from frequent data gaps due to cloud cover, cloud shadows, and temporary sensor outages. It has been a long-standing problem of remote sensing research how to best reconstruct the missing pixel values and obtain complete, cloud-free image sequences. We approach that problem from the perspective of representation learning and develop U-TILISE, an efficient neural model that is able to implicitly capture spatio-temporal patterns of the spectral intensities, and that can therefore be trained to map a cloud-masked input sequence to a cloud-free output sequence. The model consists of a convolutional spatial encoder that maps each individual frame of the input sequence to a latent encoding; an attention-based temporal encoder that captures dependencies between those per-frame encodings and lets them exchange information along the time dimension; and a convolutional spatial decoder that decodes the latent embeddings back into multi-spectral images. We experimentally evaluate the proposed model on EarthNet2021, a dataset of Sentinel-2 time series acquired all over Europe, and demonstrate its superior ability to reconstruct the missing pixels. Compared to a standard interpolation baseline, it increases the PSNR by 1.8 dB at previously seen locations and by 1.3 dB at unseen locations.
UnCRtainTS: Uncertainty Quantification for Cloud Removal in Optical Satellite Time Series
Apr 11, 2023Clouds and haze often occlude optical satellite images, hindering continuous, dense monitoring of the Earth's surface. Although modern deep learning methods can implicitly learn to ignore such occlusions, explicit cloud removal as pre-processing enables manual interpretation and allows training models when only few annotations are available. Cloud removal is challenging due to the wide range of occlusion scenarios -- from scenes partially visible through haze, to completely opaque cloud coverage. Furthermore, integrating reconstructed images in downstream applications would greatly benefit from trustworthy quality assessment. In this paper, we introduce UnCRtainTS, a method for multi-temporal cloud removal combining a novel attention-based architecture, and a formulation for multivariate uncertainty prediction. These two components combined set a new state-of-the-art performance in terms of image reconstruction on two public cloud removal datasets. Additionally, we show how the well-calibrated predicted uncertainties enable a precise control of the reconstruction quality.
Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series
Dec 14, 2021

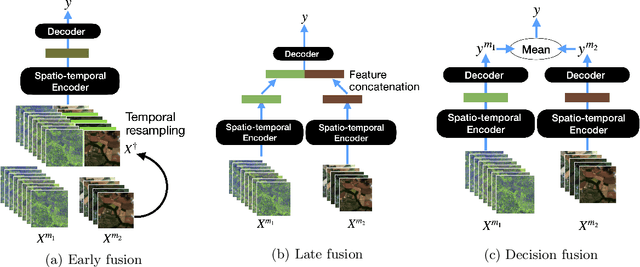

Optical and radar satellite time series are synergetic: optical images contain rich spectral information, while C-band radar captures useful geometrical information and is immune to cloud cover. Motivated by the recent success of temporal attention-based methods across multiple crop mapping tasks, we propose to investigate how these models can be adapted to operate on several modalities. We implement and evaluate multiple fusion schemes, including a novel approach and simple adjustments to the training procedure, significantly improving performance and efficiency with little added complexity. We show that most fusion schemes have advantages and drawbacks, making them relevant for specific settings. We then evaluate the benefit of multimodality across several tasks: parcel classification, pixel-based segmentation, and panoptic parcel segmentation. We show that by leveraging both optical and radar time series, multimodal temporal attention-based models can outmatch single-modality models in terms of performance and resilience to cloud cover. To conduct these experiments, we augment the PASTIS dataset with spatially aligned radar image time series. The resulting dataset, PASTIS-R, constitutes the first large-scale, multimodal, and open-access satellite time series dataset with semantic and instance annotations.
Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks
Jul 26, 2021

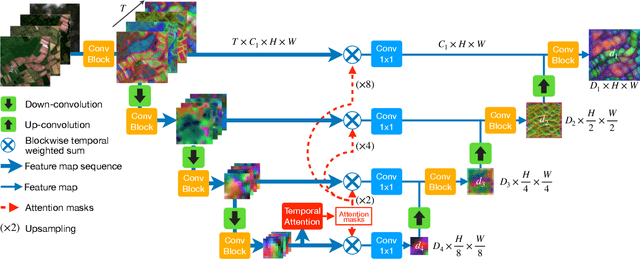
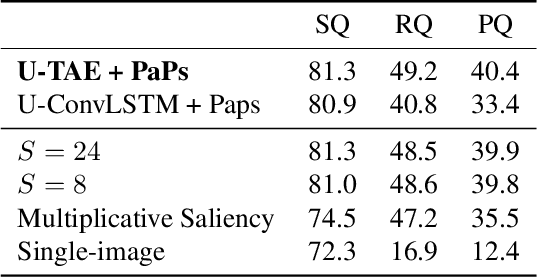
Unprecedented access to multi-temporal satellite imagery has opened new perspectives for a variety of Earth observation tasks. Among them, pixel-precise panoptic segmentation of agricultural parcels has major economic and environmental implications. While researchers have explored this problem for single images, we argue that the complex temporal patterns of crop phenology are better addressed with temporal sequences of images. In this paper, we present the first end-to-end, single-stage method for panoptic segmentation of Satellite Image Time Series (SITS). This module can be combined with our novel image sequence encoding network which relies on temporal self-attention to extract rich and adaptive multi-scale spatio-temporal features. We also introduce PASTIS, the first open-access SITS dataset with panoptic annotations. We demonstrate the superiority of our encoder for semantic segmentation against multiple competing architectures, and set up the first state-of-the-art of panoptic segmentation of SITS. Our implementation and PASTIS are publicly available.