 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-TILISE: A Sequence-to-sequence Model for Cloud Removal in Optical Satellite Time Series
May 22, 2023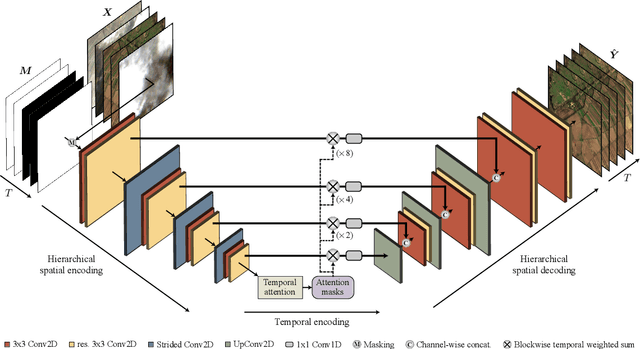
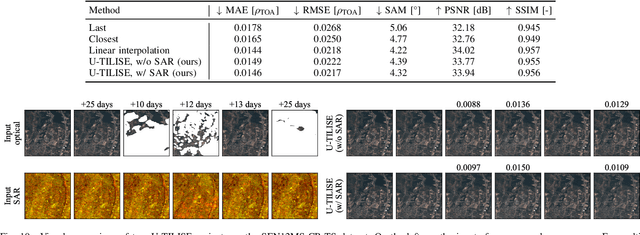
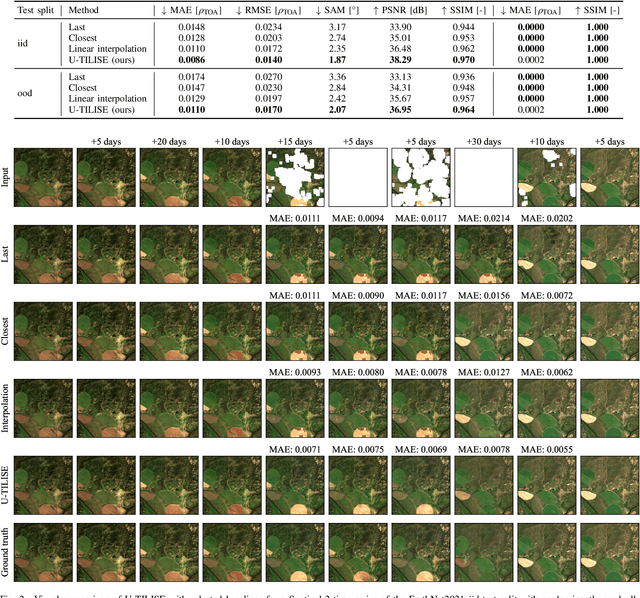

Satellite image time series in the optical and infrared spectrum suffer from frequent data gaps due to cloud cover, cloud shadows, and temporary sensor outages. It has been a long-standing problem of remote sensing research how to best reconstruct the missing pixel values and obtain complete, cloud-free image sequences. We approach that problem from the perspective of representation learning and develop U-TILISE, an efficient neural model that is able to implicitly capture spatio-temporal patterns of the spectral intensities, and that can therefore be trained to map a cloud-masked input sequence to a cloud-free output sequence. The model consists of a convolutional spatial encoder that maps each individual frame of the input sequence to a latent encoding; an attention-based temporal encoder that captures dependencies between those per-frame encodings and lets them exchange information along the time dimension; and a convolutional spatial decoder that decodes the latent embeddings back into multi-spectral images. We experimentally evaluate the proposed model on EarthNet2021, a dataset of Sentinel-2 time series acquired all over Europe, and demonstrate its superior ability to reconstruct the missing pixels. Compared to a standard interpolation baseline, it increases the PSNR by 1.8 dB at previously seen locations and by 1.3 dB at unseen locations.
ImpliCity: City Modeling from Satellite Images with Deep Implicit Occupancy Fields
Jan 24, 2022
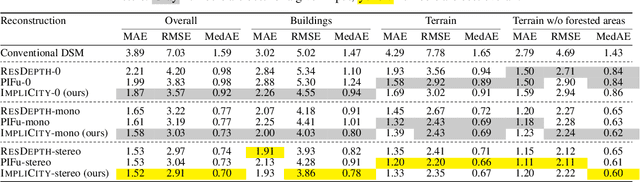
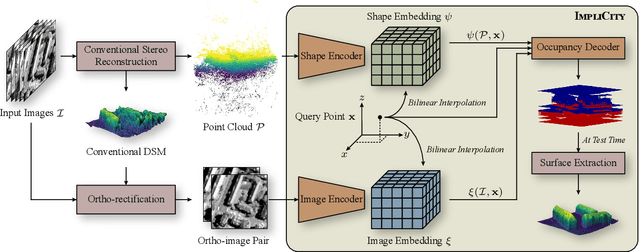

High-resolution optical satellite sensors, in combination with dense stereo algorithms, have made it possible to reconstruct 3D city models from space. However, the resulting models are, in practice, rather noisy, and they tend to miss small geometric features that are clearly visible in the images. We argue that one reason for the limited DSM quality may be a too early, heuristic reduction of the triangulated 3D point cloud to an explicit height field or surface mesh. To make full use of the point cloud and the underlying images, we introduce ImpliCity, a neural representation of the 3D scene as an implicit, continuous occupancy field, driven by learned embeddings of the point cloud and a stereo pair of ortho-photos. We show that this representation enables the extraction of high-quality DSMs: with image resolution 0.5$\,$m, ImpliCity reaches a median height error of $\approx\,$0.7$\,$m and outperforms competing methods, especially w.r.t. building reconstruction, featuring intricate roof details, smooth surfaces, and straight, regular outlines.
ResDepth: A Deep Prior For 3D Reconstruction From High-resolution Satellite Images
Jun 15, 2021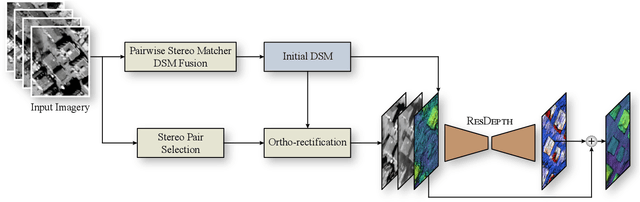
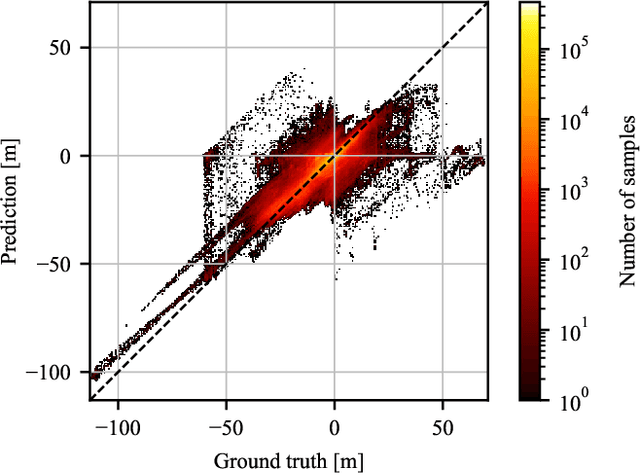
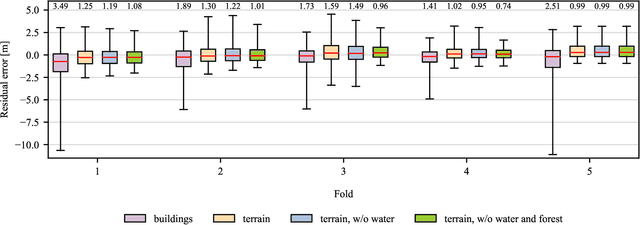

Modern optical satellite sensors enable high-resolution stereo reconstruction from space. But the challenging imaging conditions when observing the Earth from space push stereo matching to its limits. In practice, the resulting digital surface models (DSMs) are fairly noisy and often do not attain the accuracy needed for high-resolution applications such as 3D city modeling. Arguably, stereo correspondence based on low-level image similarity is insufficient and should be complemented with a-priori knowledge about the expected surface geometry beyond basic local smoothness. To that end, we introduce ResDepth, a convolutional neural network that learns such an expressive geometric prior from example data. ResDepth refines an initial, raw stereo DSM while conditioning the refinement on the images. I.e., it acts as a smart, learned post-processing filter and can seamlessly complement any stereo matching pipeline. In a series of experiments, we find that the proposed method consistently improves stereo DSMs both quantitatively and qualitatively. We show that the prior encoded in the network weights captures meaningful geometric characteristics of urban design, which also generalize across different districts and even from one city to another. Moreover, we demonstrate that, by training on a variety of stereo pairs, ResDepth can acquire a sufficient degree of invariance against variations in imaging conditions and acquisition geometry.
ResDepth: Learned Residual Stereo Reconstruction
Jan 22, 2020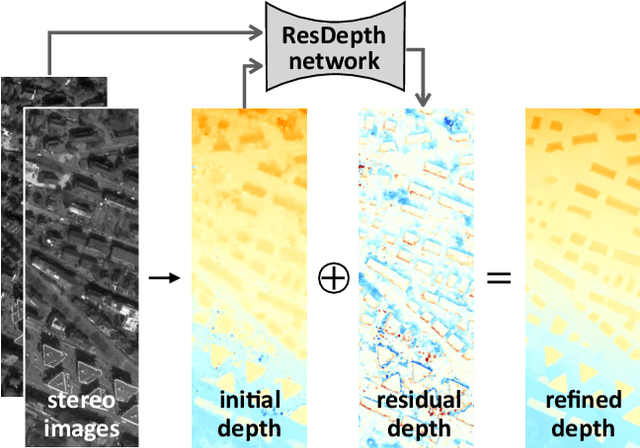

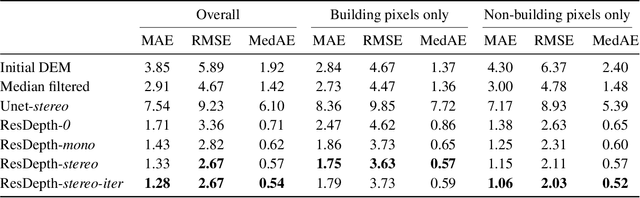

We propose an embarrassingly simple, but very effective scheme for high-quality dense stereo reconstruction: (i) generate an approximate reconstruction with your favourite stereo matcher; (ii) rewarp the input images with that approximate model; and (iii) with the initial reconstruction and the warped images as input, train a deep network to enhance the reconstruction by regressing a residual correction. The strategy to only learn the residual greatly simplifies the learning problem. A standard Unet without bells and whistles is enough to reconstruct even small surface details, like dormers and roof substructures in satellite images. We also investigate residual reconstruction with less information and find that even a single image is enough to greatly improve an approximate reconstruction. Our full model reduces the mean absolute error of state-of-the-art stereo reconstruction systems by >50%, both in our target domain of satellite stereo and on stereo pairs from the ETH3D benchmark.