 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Completion as Parameter-Efficient Test-Time Adaptation
Feb 16, 2026We introduce CAPA, a parameter-efficient test-time optimization framework that adapts pre-trained 3D foundation models (FMs) for depth completion, using sparse geometric cues. Unlike prior methods that train task-specific encoders for auxiliary inputs, which often overfit and generalize poorly, CAPA freezes the FM backbone. Instead, it updates only a minimal set of parameters using Parameter-Efficient Fine-Tuning (e.g. LoRA or VPT), guided by gradients calculated directly from the sparse observations available at inference time. This approach effectively grounds the foundation model's geometric prior in the scene-specific measurements, correcting distortions and misplaced structures. For videos, CAPA introduces sequence-level parameter sharing, jointly adapting all frames to exploit temporal correlations, improve robustness, and enforce multi-frame consistency. CAPA is model-agnostic, compatible with any ViT-based FM, and achieves state-of-the-art results across diverse condition patterns on both indoor and outdoor datasets. Project page: research.nvidia.com/labs/dvl/projects/capa.
StereoSpace: Depth-Free Synthesis of Stereo Geometry via End-to-End Diffusion in a Canonical Space
Dec 11, 2025We introduce StereoSpace, a diffusion-based framework for monocular-to-stereo synthesis that models geometry purely through viewpoint conditioning, without explicit depth or warping. A canonical rectified space and the conditioning guide the generator to infer correspondences and fill disocclusions end-to-end. To ensure fair and leakage-free evaluation, we introduce an end-to-end protocol that excludes any ground truth or proxy geometry estimates at test time. The protocol emphasizes metrics reflecting downstream relevance: iSQoE for perceptual comfort and MEt3R for geometric consistency. StereoSpace surpasses other methods from the warp & inpaint, latent-warping, and warped-conditioning categories, achieving sharp parallax and strong robustness on layered and non-Lambertian scenes. This establishes viewpoint-conditioned diffusion as a scalable, depth-free solution for stereo generation.
A Unified Solution to Video Fusion: From Multi-Frame Learning to Benchmarking
May 26, 2025
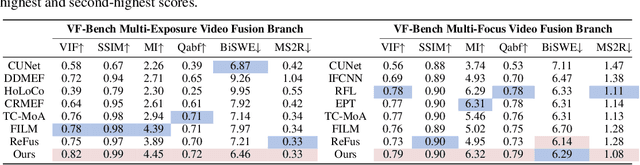
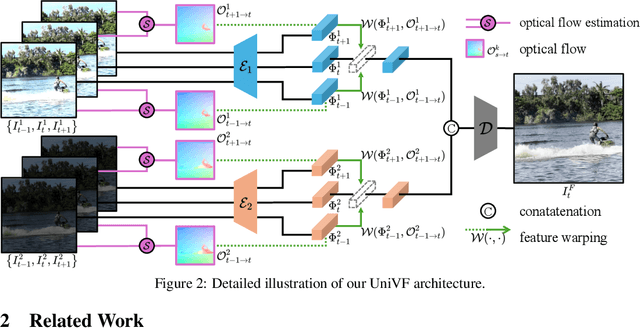
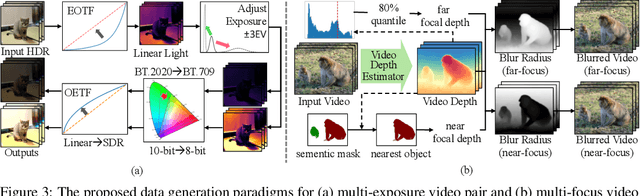
The real world is dynamic, yet most image fusion methods process static frames independently, ignoring temporal correlations in videos and leading to flickering and temporal inconsistency. To address this, we propose Unified Video Fusion (UniVF), a novel framework for temporally coherent video fusion that leverages multi-frame learning and optical flow-based feature warping for informative, temporally coherent video fusion. To support its development, we also introduce Video Fusion Benchmark (VF-Bench), the first comprehensive benchmark covering four video fusion tasks: multi-exposure, multi-focus, infrared-visible, and medical fusion. VF-Bench provides high-quality, well-aligned video pairs obtained through synthetic data generation and rigorous curation from existing datasets, with a unified evaluation protocol that jointly assesses the spatial quality and temporal consistency of video fusion. Extensive experiments show that UniVF achieves state-of-the-art results across all tasks on VF-Bench. Project page: https://vfbench.github.io.
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
May 14, 2025The success of deep learning in computer vision over the past decade has hinged on large labeled datasets and strong pretrained models. In data-scarce settings, the quality of these pretrained models becomes crucial for effective transfer learning. Image classification and self-supervised learning have traditionally been the primary methods for pretraining CNNs and transformer-based architectures. Recently, the rise of text-to-image generative models, particularly those using denoising diffusion in a latent space, has introduced a new class of foundational models trained on massive, captioned image datasets. These models' ability to generate realistic images of unseen content suggests they possess a deep understanding of the visual world. In this work, we present Marigold, a family of conditional generative models and a fine-tuning protocol that extracts the knowledge from pretrained latent diffusion models like Stable Diffusion and adapts them for dense image analysis tasks, including monocular depth estimation, surface normals prediction, and intrinsic decomposition. Marigold requires minimal modification of the pre-trained latent diffusion model's architecture, trains with small synthetic datasets on a single GPU over a few days, and demonstrates state-of-the-art zero-shot generalization. Project page: https://marigoldcomputervision.github.io
Marigold-DC: Zero-Shot Monocular Depth Completion with Guided Diffusion
Dec 18, 2024



Depth completion upgrades sparse depth measurements into dense depth maps guided by a conventional image. Existing methods for this highly ill-posed task operate in tightly constrained settings and tend to struggle when applied to images outside the training domain or when the available depth measurements are sparse, irregularly distributed, or of varying density. Inspired by recent advances in monocular depth estimation, we reframe depth completion as an image-conditional depth map generation guided by sparse measurements. Our method, Marigold-DC, builds on a pretrained latent diffusion model for monocular depth estimation and injects the depth observations as test-time guidance via an optimization scheme that runs in tandem with the iterative inference of denoising diffusion. The method exhibits excellent zero-shot generalization across a diverse range of environments and handles even extremely sparse guidance effectively. Our results suggest that contemporary monocular depth priors greatly robustify depth completion: it may be better to view the task as recovering dense depth from (dense) image pixels, guided by sparse depth; rather than as inpainting (sparse) depth, guided by an image. Project website: https://MarigoldDepthCompletion.github.io/
Video Depth without Video Models
Nov 28, 2024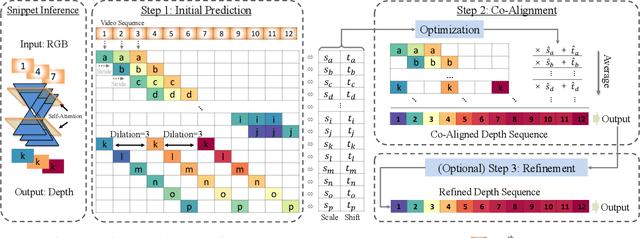
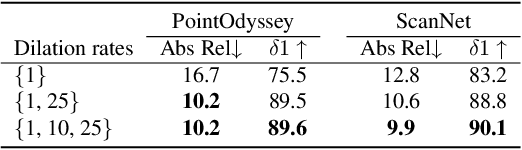
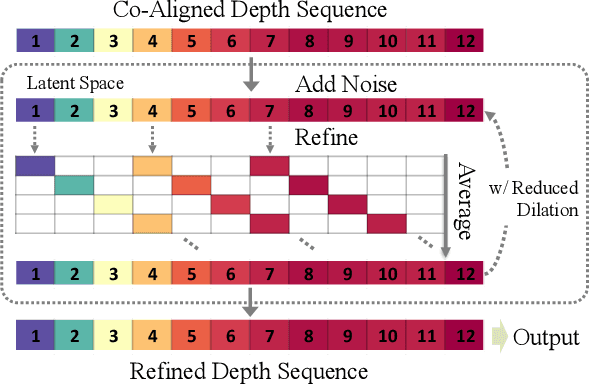
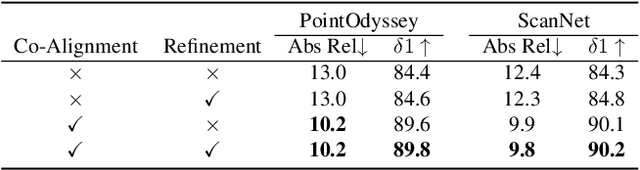
Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Jul 25, 2024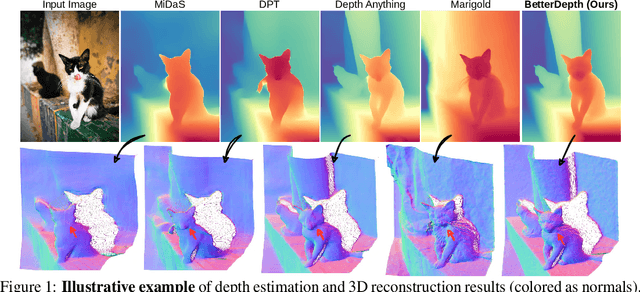

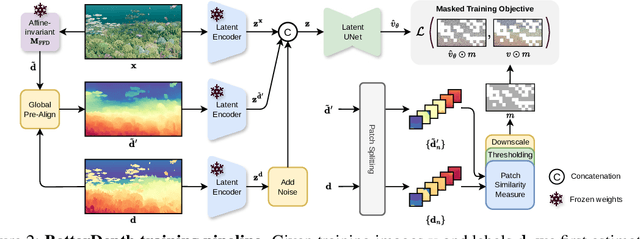
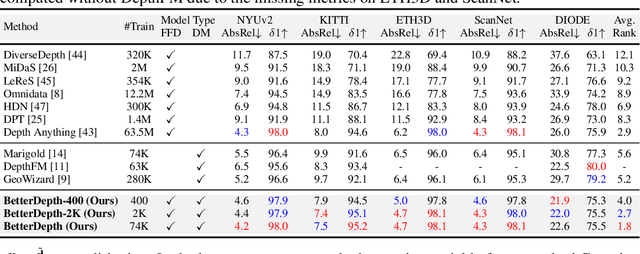
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details. Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets. To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details. By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Dec 04, 2023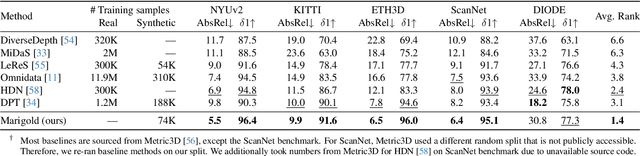
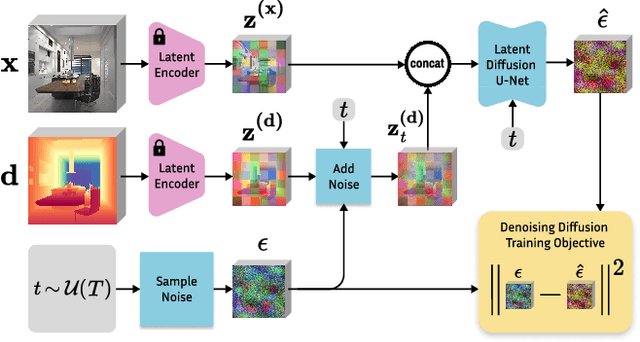
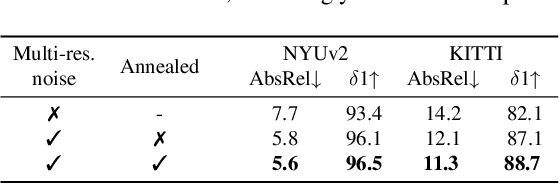
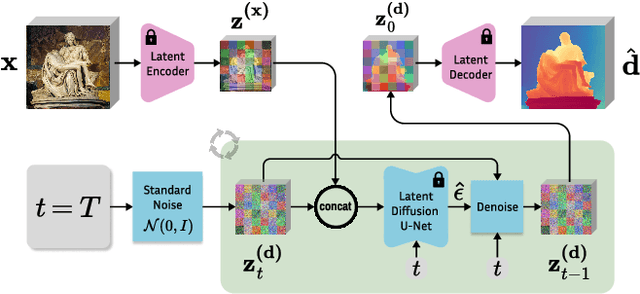
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
ImpliCity: City Modeling from Satellite Images with Deep Implicit Occupancy Fields
Jan 24, 2022
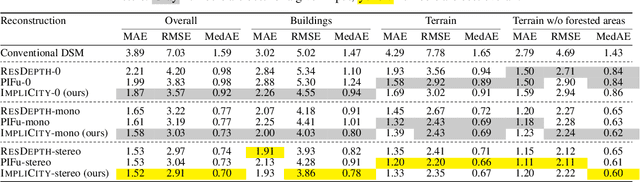
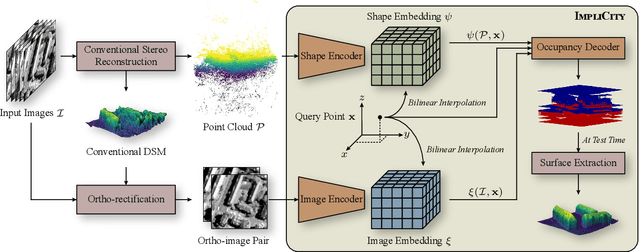

High-resolution optical satellite sensors, in combination with dense stereo algorithms, have made it possible to reconstruct 3D city models from space. However, the resulting models are, in practice, rather noisy, and they tend to miss small geometric features that are clearly visible in the images. We argue that one reason for the limited DSM quality may be a too early, heuristic reduction of the triangulated 3D point cloud to an explicit height field or surface mesh. To make full use of the point cloud and the underlying images, we introduce ImpliCity, a neural representation of the 3D scene as an implicit, continuous occupancy field, driven by learned embeddings of the point cloud and a stereo pair of ortho-photos. We show that this representation enables the extraction of high-quality DSMs: with image resolution 0.5$\,$m, ImpliCity reaches a median height error of $\approx\,$0.7$\,$m and outperforms competing methods, especially w.r.t. building reconstruction, featuring intricate roof details, smooth surfaces, and straight, regular outlines.